






英文原文:https://aituts.com/comfyui/
我们如何了解实际发生的情况以便我们可以创建和修改工作流程?
要了解节点,我们必须了解一些稳定扩散的工作原理。
让我们看一下默认的工作流程。
如果您没有使用默认工作流程,或者您一直在搞乱界面,请单击右侧边栏上的“Load Default”。
Load Checkpoint Node
用于生成图像的 .safetensors 或 .ckpt 检查点模型有 3 个主要组件:
- Unet:执行“扩散”过程,即我们称之为生成的图像的逐步处理
- CLIP:将文本转换为Unet可以理解的格式
- VAE:将图像从潜在空间解码到像素空间(当我们进行 img2img 时,也用于将常规图像从像素空间编码到潜在空间)
在 ComfyUI 工作流程中,这由 Load Checkpoint 节点及其 3 个输出表示(MODEL 指 Unet)。
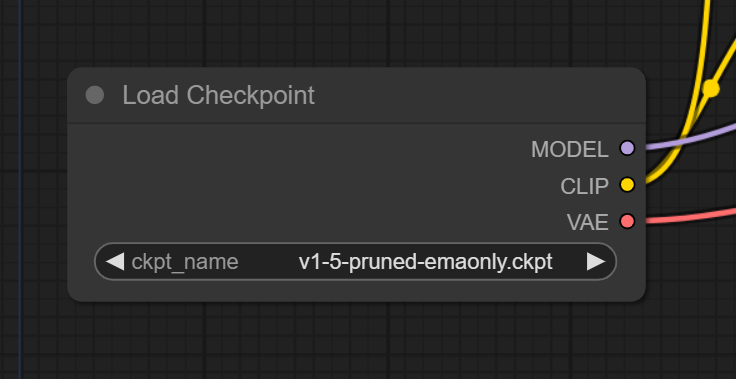
这些输出连接到什么?
CLIP Text Encode Node
Load Checkpoint 节点的 CLIP 输出连接到 CLIP Text Encode 节点。
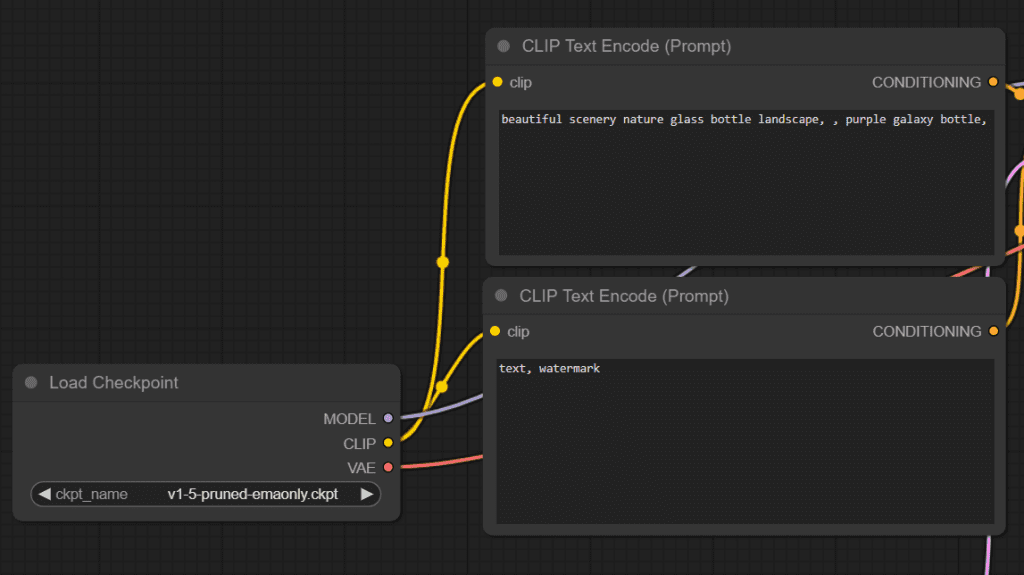
CLIP模型用于将文本转换为Unet可以理解的格式(文本的数字表示)。 我们称这些为嵌入。
CLIP Text Encode 节点将检查点的 CLIP 模型作为输入,将提示(正向和负向)作为变量,执行编码过程,并将这些嵌入输出到下一个节点 KSampler。
KSampler
在 Stable Diffusion 中,图像是通过称为采样的过程生成的。
在 ComfyUI 中,此过程发生在 KSampler 节点中。 这是实际的“生成”部分,因此您会注意到,当您对提示进行排队时,KSampler 需要花费最多的时间来运行。
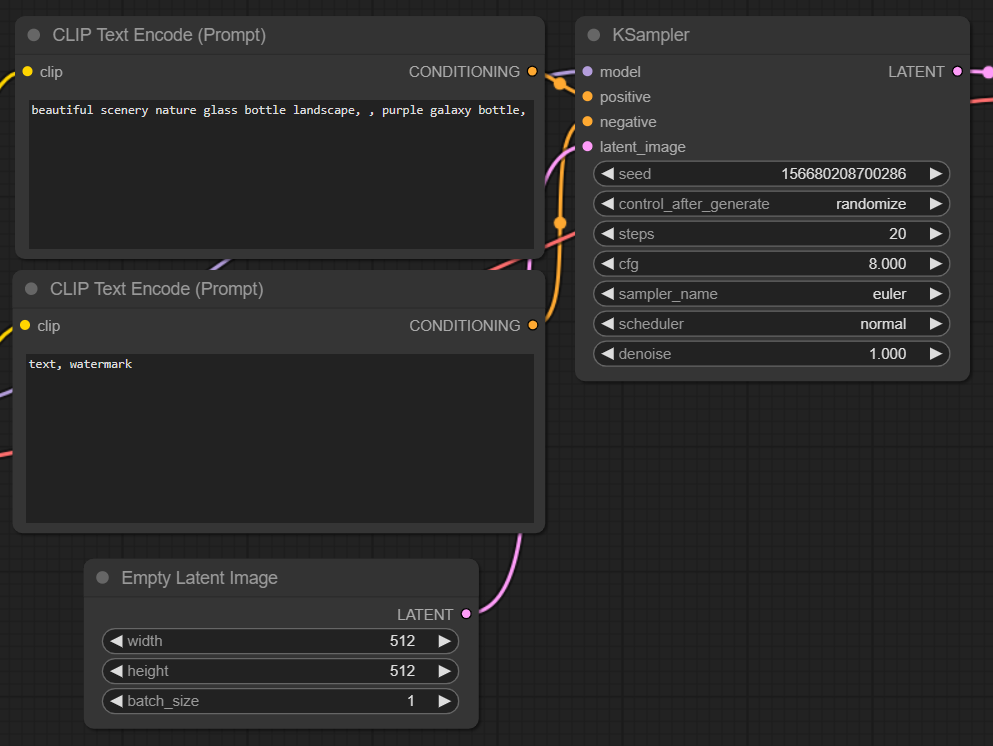
KSampler 接受以下输入:
- model:来自 Load Checkpoint 节点的 MODEL 输出 (Unet)
- positive:CLIP模型编码的正向提示(CLIP Text Encode节点)
- negative:CLIP模型编码的否定提示(其他CLIP Text Encode节点)
- latent_image:潜在空间中的图像(Empty Latent Image节点)
由于我们仅根据提示生成图像 (txt2img),因此我们使用 Empty Latent Image节点向 Latent_image 传递空图像。
(您也可以将实际图像传递给 KSampler,以执行 img2img。我们将在下面讨论这一点)
KSampler 中发生了什么?
Diffusion(扩散)是实际生成图像的过程。
我们从随机信息数组和嵌入(编码的正面和负面提示词)开始。
扩散发生在多个步骤中,每个步骤都对信息数组(也称为潜在变量)进行操作,并产生另一个更类似于提示文本的信息数组。
因此,我们从一个随机信息数组开始,最后得到一个类似于我们已知的信息的数组。
KSampler 输出此信息。 然而,它还不在像素空间中(我们看不到它),它仍然是一个潜在的表示。
VAE
VAEDecode 节点有 2 个输入:
- 我们的检查点模型附带的 VAE(您也可以添加自己的 VAE)
- 我们的KSampler已经完成去噪的潜在空间图像。
VAE 用于将图像从潜在空间转换到像素空间。
它将最终的像素图像传递到“Save Image”节点,该节点用于向我们显示图像并让我们下载它。
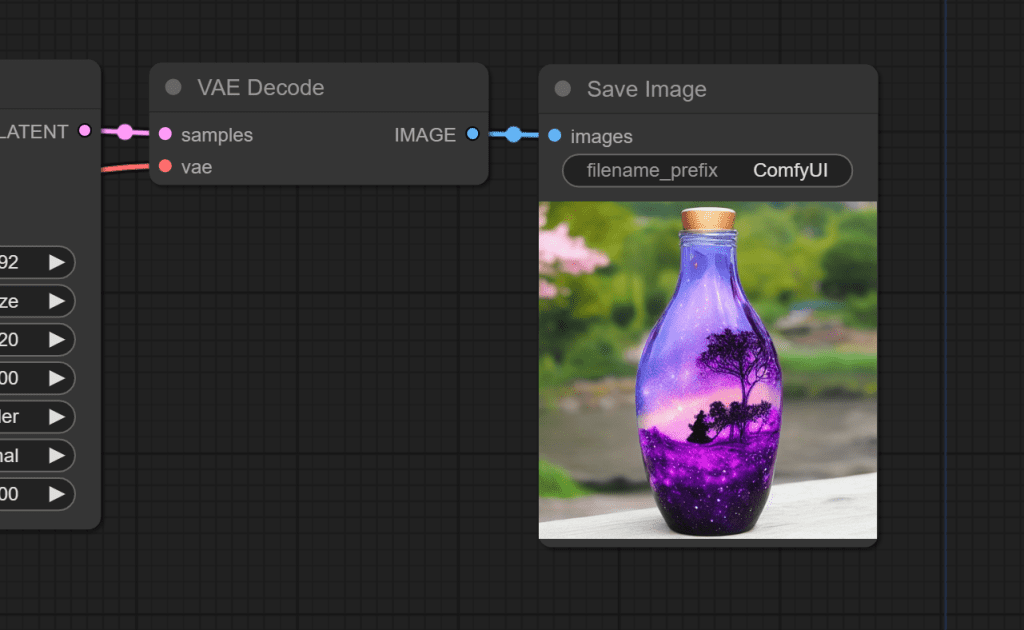
默认工作流程是您在 ComfyUI 中找到的最简单的工作流程。

















 5143
5143

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









