







1.决策树算法介绍:
决策树是一种监督学习算法,使用样本数据针对数据属性建立决策树模型,根据决策树对测试数据进行分类。
2.决策树的特点:
决策树的计算法负责读不高,输出易于理解,但是可能会出现过度匹配的问题,适用于数值型和标称型数据。
3.决策树的构造:
1、对数据集进行判断,是否特征列数大于1,如果否则构建叶子结点返回,否则继续下一步。
2、对数据集进行判断,是否当前数据集属于同一个分类,如果是则构造叶子结点返回,否则继续下一步。
3、选取当前数据集的一个特征,对数据集以该特征划分成多个子数据集,然后对每个子数据集递归构建决策树。返回分支结点。
(1) 决策树的构造过程如上,看起来很简单吧。但是如何选取划分的特征呢?总不能随机选取一个特征对数据集进行划分吧,必须要有一个划分原则:将无序数据变得有序。这里采用ID3算法划分数据,目的:将数据集划分为尽可能的属于同一分类的子数据集。“尽可能”是感性描述,在计算机中需要转化为数值来进行度量才能使用。需要使用信息论中的“熵”来度量数据集的无序度,公式如下:
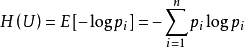
公式中n为数据集的分类总数,pi为数据集中第i个分类出现的频率,采用2 的对数。
现在已知数据集的有序度的度量方式,还需要知道一个概念“信息增益”:数据集划分前后的熵值的变化,即数据无序度的变化。
知道这些了就可以选取最合适的特征了
求当前数据集的“熵”,然后对每个特征尝试划分,求取“信息增益”,取最大信息增益的特征为最佳特征。
(2)在决策树的构造过程中,有两种情况会终止构造。一、当前数据集的特征已经构造完。二、当前数据集已经属于同一个分类。对于第一种情况,存在特征构造完,但是数据集可能不属于同一个分类,这时需要采用“多数表决”,数据集中出现次数多的分类作为叶子结点的分类。
4.Java实现决策树
下面开始最激动人心的代码编写了
首先定义数据集的结点类(Node)存储用于构建决策树的每一条数据,包含特征值和分类。代码如下:
<pre name="code" class="java">package Tree;
import java.util.ArrayList;
import java.util.List;
/*
* 数据结点类
*/
public class Node implements Cloneable{
private List<String> data; //特征值
private String type; //类型
public Node() {
super();
}
public Node(List<String> data, String type) {
super();
this.data = data;
this.type = type;
}
public List<String> getData() {
return data;
}
public void setData(List<String> data) {
this.data = data;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public Node clone(){
Node node=null;
try {
node=(Node)super.clone();
node.type=this.type;
node.data=new ArrayList<String>();
for(int i=0;i<this.data.size();++i)
node.data.add(new String(this.data.get(i)));
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return node;
}
}
package Tree;
import java.util.List;
/*
* 树节点
*/
public class TreeNode {
private String attribute; //特征
private List<BranchNode> branches; //分支数组
public TreeNode() {
super();
}
public TreeNode(String attribute, List<BranchNode> branches) {
super();
this.attribute = attribute;
this.branches = branches;
}
public String getAttribute() {
return attribute;
}
public void setAttribute(String attribute) {
this.attribute = attribute;
}
public List<BranchNode> getBranches() {
return branches;
}
public void setBranches(List<BranchNode> branches) {
this.branches = branches;
}
public String toString(){
String data="";
data+=attribute+":{";
if(branches!=null){
List<BranchNode> list=(List<BranchNode>) branches;
for(BranchNode node:list){
if(null!=node.getSubTree())
data+=node.getSubTree().toString();
}
}
data+="}";
return data;
}
}
分支结点BranchNode类,包含属性特征值value,子树subTree,代码如下:
package Tree;
import java.util.List;
/*
* 树节点
*/
public class TreeNode {
private String attribute; //属性值
private List<BranchNode> branches; //分支数组
public TreeNode() {
super();
}
public TreeNode(String attribute, List<BranchNode> branches) {
super();
this.attribute = attribute;
this.branches = branches;
}
public String getAttribute() {
return attribute;
}
public void setAttribute(String attribute) {
this.attribute = attribute;
}
public List<BranchNode> getBranches() {
return branches;
}
public void setBranches(List<BranchNode> branches) {
this.branches = branches;
}
public String toString(){
String data="";
data+=attribute+":{";
if(branches!=null){
List<BranchNode> list=(List<BranchNode>) branches;
for(BranchNode node:list){
if(null!=node.getSubTree())
data+=node.getSubTree().toString();
}
}
data+="}";
return data;
}
}
决策树构造类Tree类,代码如下:
package Tree;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.TreeMap;
import KNN.KNN;
public class Tree {
/*
* 通过指定文件路径,加载样本数据
*/
public List<Node> loadData(String fileName){
List<Node> list=new ArrayList<Node>();
BufferedReader br;
try {
br = new BufferedReader(new InputStreamReader(new FileInputStream(fileName)));
String line=null;
Node node=null;
List<String> data=null;
while((line=br.readLine())!=null){
node=new Node();
data=new ArrayList<String>();
String[] s=line.split("\t");
for(int i=0;i<s.length-1;++i){
data.add(s[i].trim());
}
node.setData(data);
node.setType(s[s.length-1].trim());
list.add(node);
}
return list;
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (NumberFormatException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return list;
}
/*
* 计算数据集的’熵‘
*/
public double calShannonEnt(List<Node> dataSet){
int num=dataSet.size();
HashMap<String,Integer> map=new HashMap<String, Integer>();
for(Node node : dataSet){
if(map.containsKey(node.getType()))
map.put(node.getType(),map.get(node.getType())+1);
else
map.put(node.getType(), 1);
}
double shannoEnt=0;
double prob;
Set<String> set=map.keySet();
for(String s : set){
prob=(float)map.get(s)/num;
shannoEnt-=prob*(Math.log(prob)/Math.log(2));
}
return shannoEnt;
}
/*
* 划分数据集
*/
public List<Node> splitDataSet(List<Node> dataSet,int x,String value){
List<Node> newSet=new ArrayList<Node>();
Node newNode=null;
for(Node node :dataSet){
if(node.getData().get(x).equals(value)){
newNode=node.clone();
newNode.getData().remove(x);
newSet.add(newNode);
}
}
return newSet;
}
/*
* 查找最佳划分特征
*/
public int chooseBestFeatureToSplit(List<Node> dataSet){
int featNum=dataSet.get(0).getData().size(); //数据集的特征数量
double oldShan=calShannonEnt(dataSet); //当前数据集的熵
int bestFeat=-1; //最佳特征下标
double bestInfoGain=0.0; //最大信息增益
for(int i=0;i<featNum;++i){
HashSet<String> set=new HashSet<String>();
for(Node node :dataSet){
set.add(node.getData().get(i));
}
double prob;
double newEntropy = 0;
for(String value: set){
List<Node> newSet=splitDataSet(dataSet, i, value);
prob=(float)newSet.size()/dataSet.size();
newEntropy+=prob*calShannonEnt(newSet);
}
if((oldShan-newEntropy)>=bestInfoGain){
bestInfoGain=oldShan-newEntropy;
bestFeat=i;
}
}
return bestFeat;
}
/*
* 查找次数最高的分类
*/
public String majorityCnt(List<String> classList){
HashMap<String,Integer> map=new HashMap<String,Integer>();
ValueComparetor vc=new ValueComparetor(map);
TreeMap<String,Integer> tm=new TreeMap<String,Integer>();
for(String s:classList){
if(map.containsKey(s))
map.put(s, map.get(s)+1);
else
map.put(s, 1);
}
tm.putAll(map);
return tm.firstKey();
}
class ValueComparetor implements Comparator<String>{
Map<String,Integer> map;
public ValueComparetor(Map<String,Integer> map ){
this.map=map;
}
public int compare(String arg0, String arg1) {
if(map.get(arg0)>=map.get(arg1))
return -1;
else
return 1;
}
}
/*
* 对给定数据集构建决策树
*/
public TreeNode createTree(List<Node> dataSet,List<String> labels){
TreeNode tree=null;
List<BranchNode> branches=new ArrayList<BranchNode>();
List<String> classList=getClassList(dataSet); //获取当前数据集的分类数组
if(dataSet.get(0).getData().size()==0){ //当数据集特征划分完
tree=new TreeNode(majorityCnt(classList),null);
return tree;
}
Set<String> set=new HashSet<String>(classList);
if(set.size()==1){ //当前数据集属于同一分类
tree=new TreeNode(classList.get(0),null );
return tree;
}
int bestFeat=chooseBestFeatureToSplit(dataSet); //获取最佳分组特征下标
String bestFeatLabel=labels.get(bestFeat); //获取最佳分组特征名
labels.remove(bestFeat); //移除分组特征名
Set<String> labelDataSet=new HashSet<String>(); //去重特征值数组
for(Node node:dataSet){
labelDataSet.add(node.getData().get(bestFeat));
}
for(String value : labelDataSet){ //针对特征的不同特征值划分数据集
List<String> subLabels=new ArrayList<String>(labels);
branches.add(new BranchNode(value, createTree(splitDataSet(dataSet, bestFeat, value), subLabels)));
}
tree=new TreeNode(bestFeatLabel, branches);
return tree;
}
/*
* 获取数据集的分类数组
*/
public List<String> getClassList(List<Node> dataSet){
List<String> classList=new ArrayList<String>();
for(Node node :dataSet){
classList.add(node.getType());
}
return classList;
}
/*
* 根据决策树对测试数据分类
*/
public String clarrify(TreeNode tree,List<String> labelsList,Node test){
if(tree.getBranches()==null){
return tree.getAttribute();
}
List<BranchNode> branches=(List<BranchNode>) tree.getBranches();
for(BranchNode branch : branches){
int index=labelsList.indexOf(tree.getAttribute());
if(branch.getValue().equals(test.getData().get(index)))
return clarrify( branch.getSubTree(),labelsList,test);
}
return null;
}
public static void main(String[] args) {
String sampFile="E:\\Java_Project\\DeepLearning\\src\\Tree\\lenses.txt";
Tree t=new Tree();
List<Node> data=t.loadData(sampFile);
String []labels={"age","prescript1", "astigmatic1", "tearRate1"};//特征名数组
List<String> labelsList=new ArrayList<String>();
Collections.addAll(labelsList, labels);
TreeNode tree=t.createTree(data, labelsList);
System.out.println("Tree"+tree); //输出决策树
String []testData={"presbyopic","myope","yes","normal"};
List<String> test=new ArrayList<String>();
Collections.addAll(test,testData);
Node node=new Node(test,null);
List<String> labelsList2=new ArrayList<String>();
Collections.addAll(labelsList2, labels);
System.out.println(t.clarrify(tree, labelsList2, node));
}
}
数据格式如下,最后一行为分类:
young myope no reduced no lenses
young myope no normal soft
young myope yes reduced no lenses
young myope yes normal hard
young hyper no reduced no lenses
young hyper no normal soft
young hyper yes reduced no lenses
young hyper yes normal hard
pre myope no reduced no lenses
pre myope no normal soft
pre myope yes reduced no lenses
pre myope yes normal hard
pre hyper no reduced no lenses
pre hyper no normal soft
pre hyper yes reduced no lenses
pre hyper yes normal no lenses
presbyopic myope no reduced no lenses
presbyopic myope no normal no lenses
presbyopic myope yes reduced no lenses
presbyopic myope yes normal hard
presbyopic hyper no reduced no lenses
presbyopic hyper no normal soft
presbyopic hyper yes reduced no lenses
presbyopic hyper yes normal no lenses
5.小结:
决策树算法只要熟悉了熵值计算,按照特征值划分数据集,最佳分类查询这几个方法,一个简单的实现还是挺容易的。这里没有给出图形化显示,如果将最终的决策树画成图,决策树分类过程非常直观、清晰易懂。















 1191
1191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









