






首先所有ImageProvider的子类,都是继承于abstract class ImageProvider<T extends Object>
通过如下的注释可以得知,ImageProvider的入口方法为
@nonVirtual
ImageStream resolve(ImageConfiguration configuration)
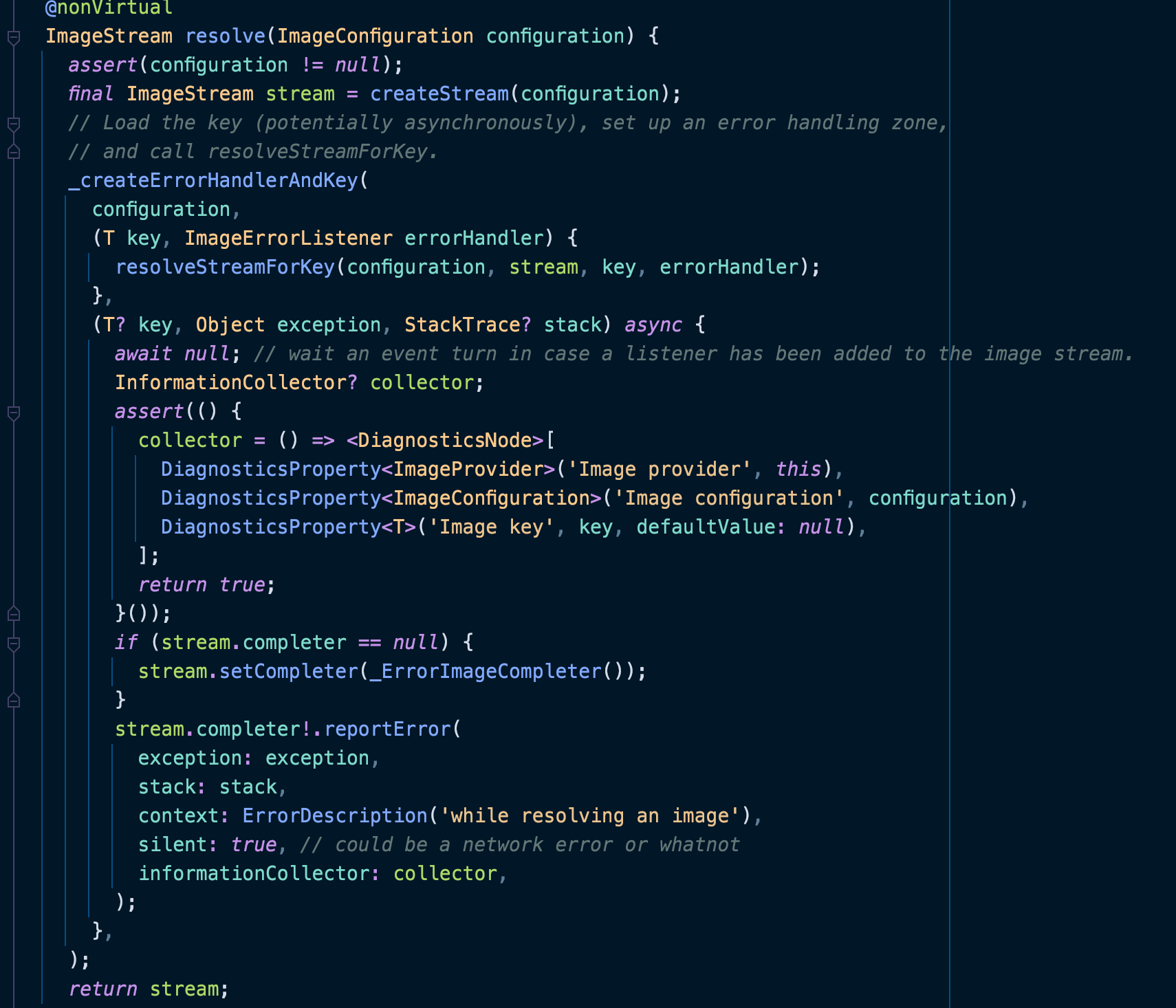
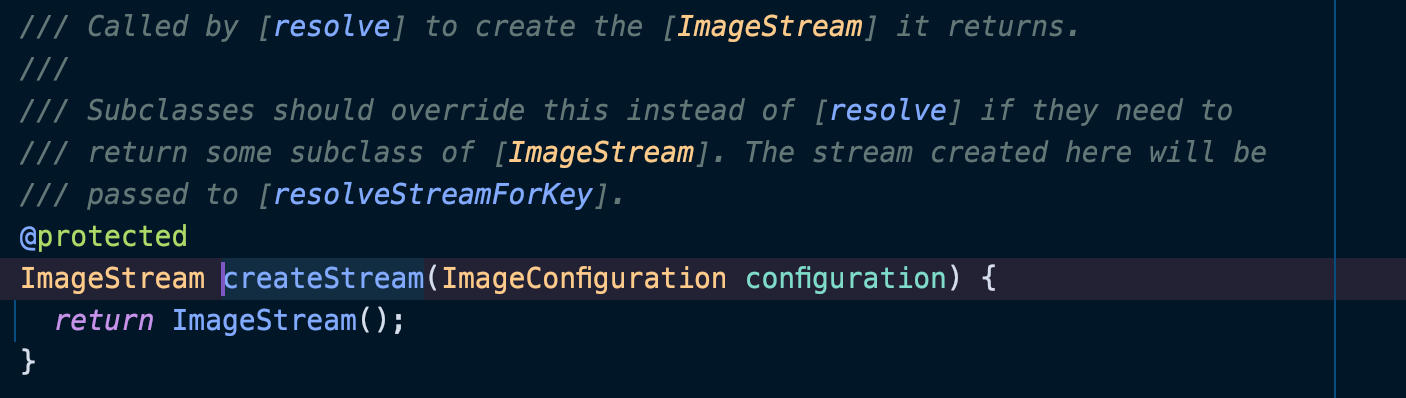
首先会调用createStream方法,这个方法如果不重写子类,则返回默认初始化的ImageStream
然后将调用_createErrorHandlerAndKey方法,该方法最主要的就是调用obtainKey获取到Key,obtainKey为子类必须重写的方法。
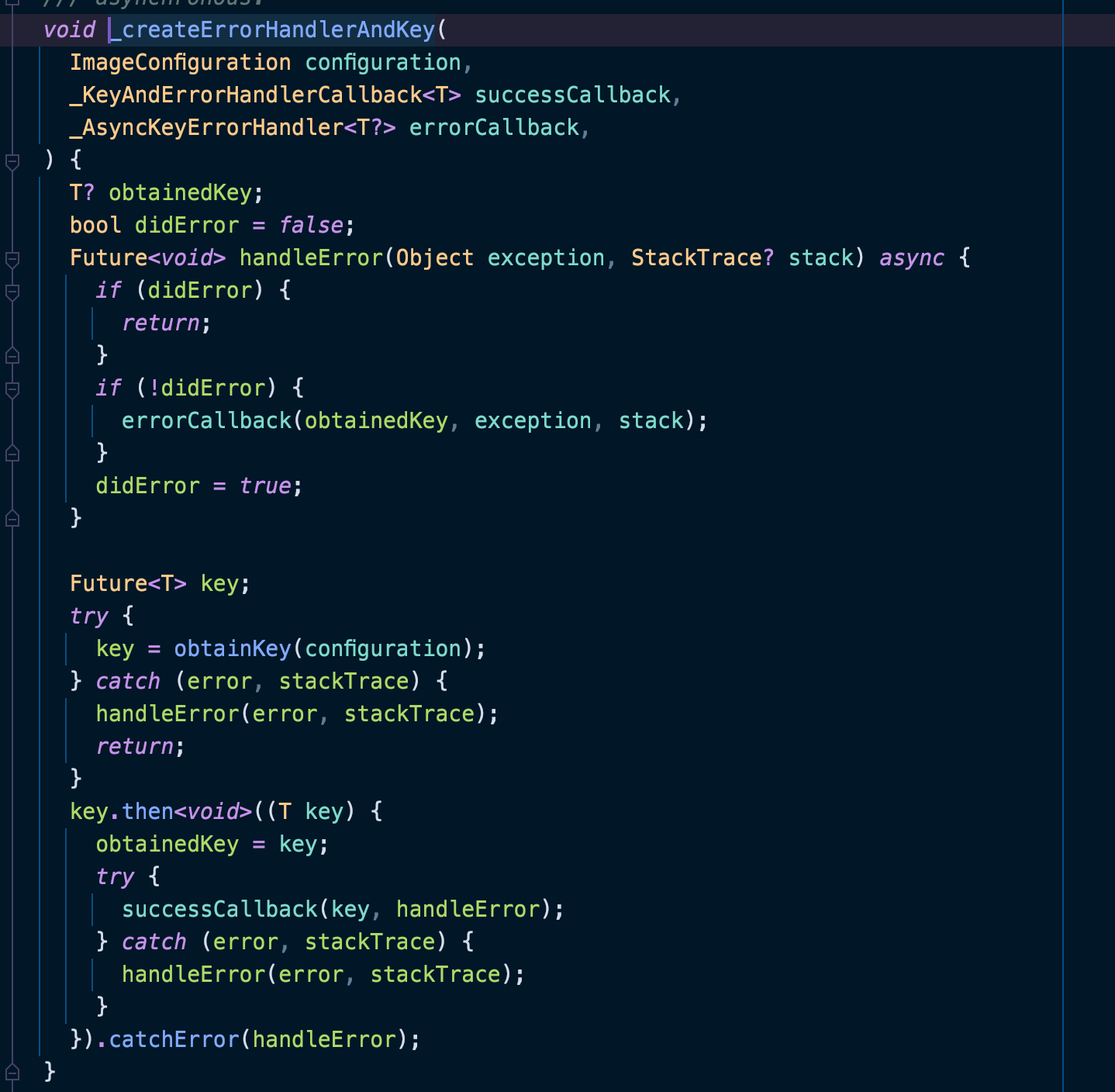
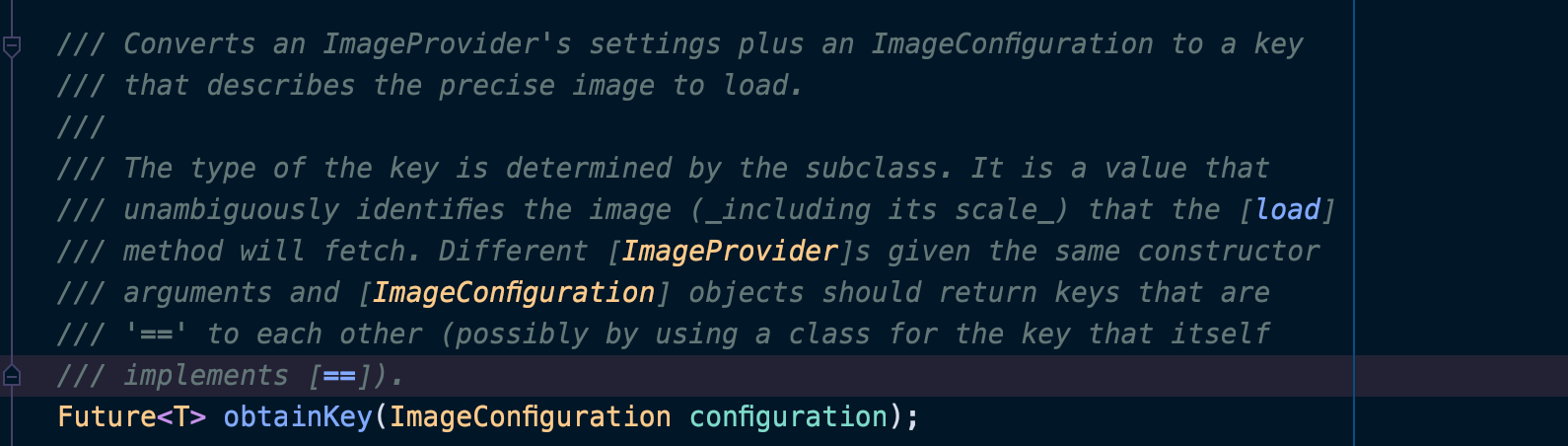
由于该方法需要子类实现,所以此处以网络请求的NetworkImage类为例

NetworkImage的obtainKey返回的key为自己本身,此时可以判定Key可以设置为任意类型,只需要
bool operator ==(Object other)
方法判定后为true,即可判定key相同
而NetworkImage判定的相同条件为,url与scale相同,则判定为同一个对象,这边可以得出url、scale将组合成唯一标识

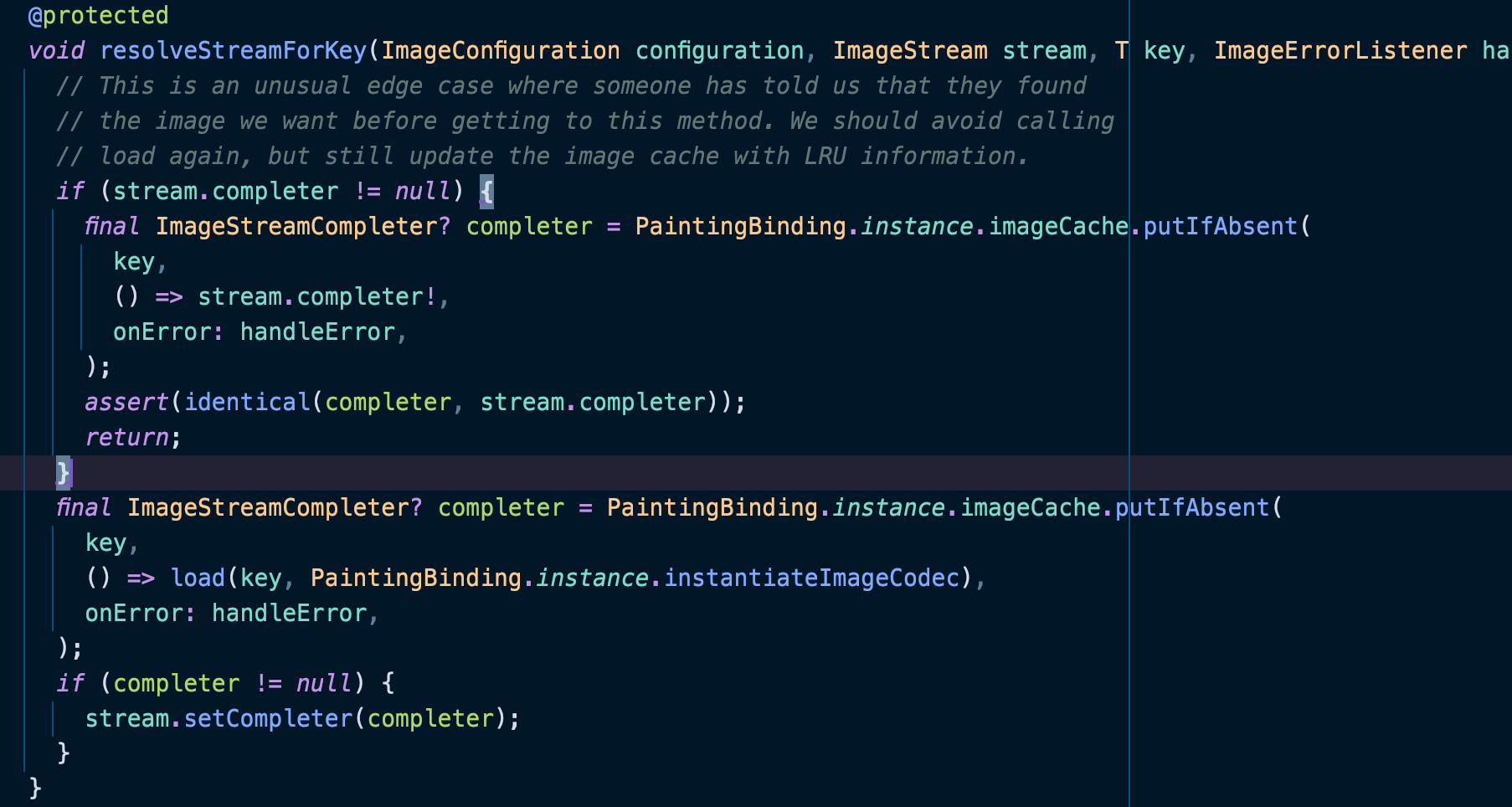
在obtainKey返回key之后,imageProvider中,将创建一个ImageStreamCompleter用于监听数据流是否读取,此时会将load方法的返回值,作为value放入缓存中。此处的imageCache的putIfAbsend并不与Map的同名方法逻辑一致,此处的方法将先判定Key是否存在,存在则直接返回completer,不再走后续逻辑,如不存在则进入loader的回调方法。load方法为子类必须继承的方法,此处将会处理并返回ImageStreamCompleter。
这个load方法在NetworkImageProvider实现如下:
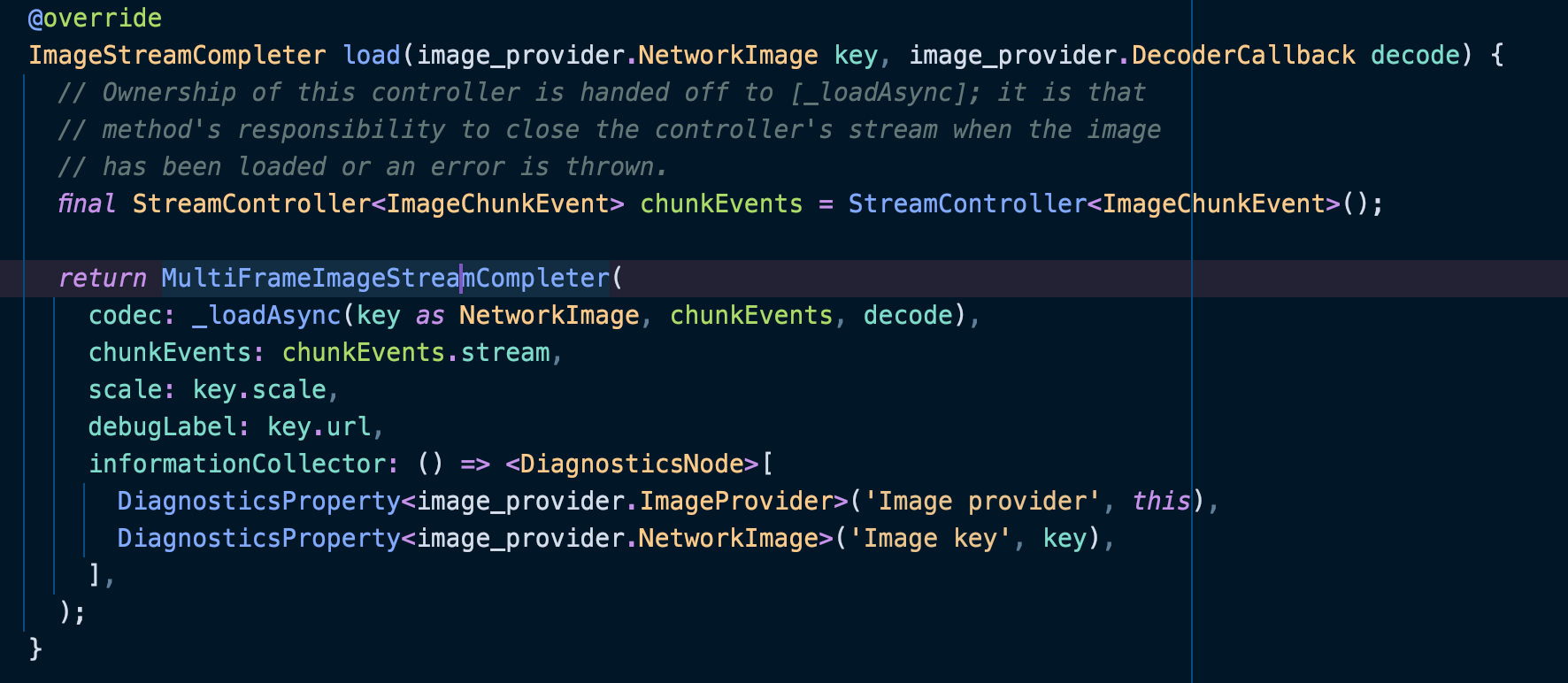
此时可以发现,此时ImageProvider的key,其实是可以作为一个参数传递者,带入所需要的参数到实际的数据流获取位置。
_loadAsync可以看出这就是实际从网络请求获取数据信息的方法,且最后将结果转换为Unit8List类型传递后实际进行解码,解码后获取到下一帧的图像才是最终显示的图像。
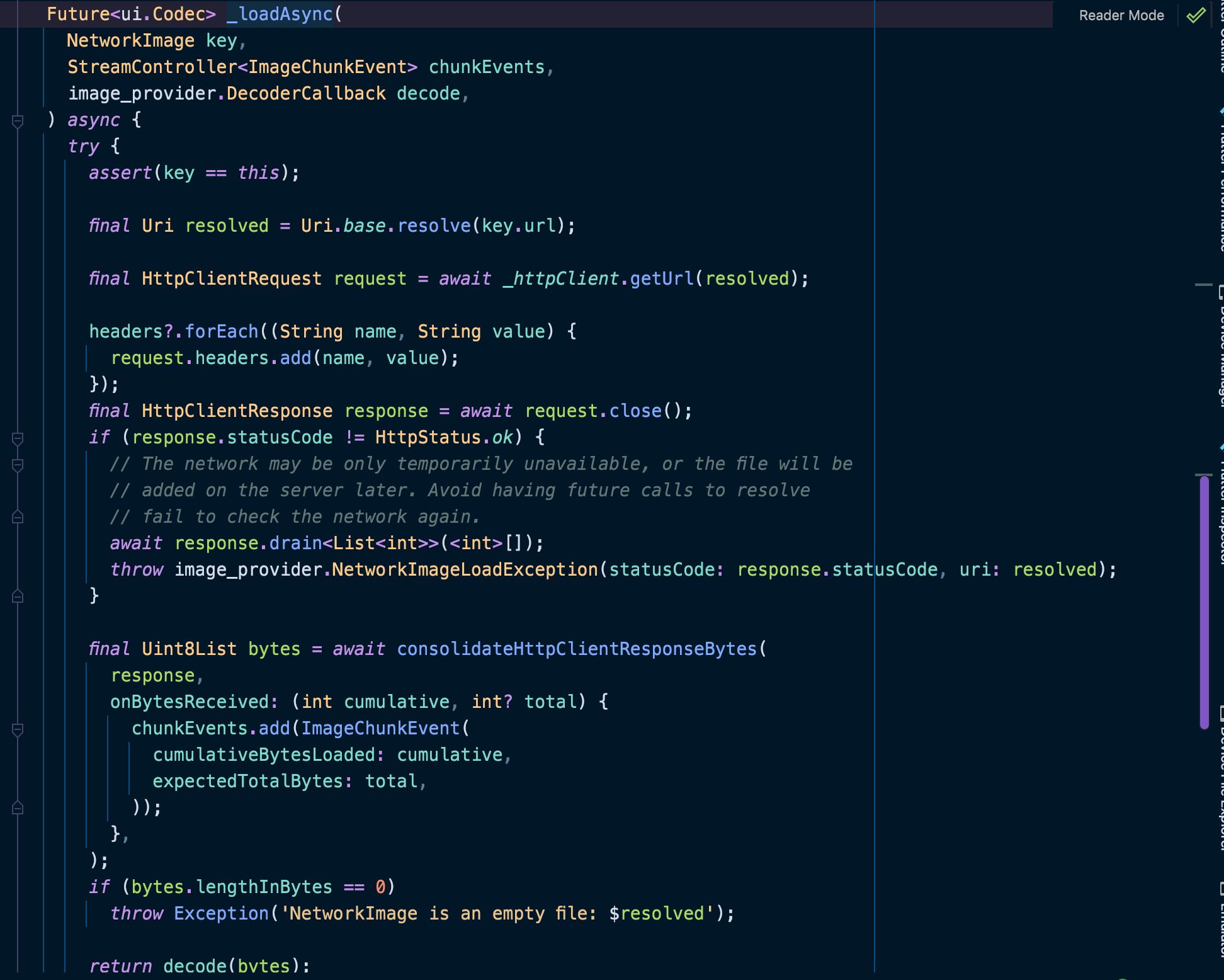
该方法可以发现一个缺陷,如果cache中没有通过key进行命中,则将会直接从网络请求中重新获取图片信息,缺少在文件层的二级缓存功能。
通过源码可以发现,framework中ImageCache是有一定限制的,当超过1000数量或100MB图片缓存后。所有通过key缓存的cache,将通过内部的链表结构与LRU算法,将以前的cache进行清理,所以在大量图片缓存后,读取原有的图片很容易造成资源浪费,此时就需要在load方法中增加一层基于文件的图片缓存层。



















 2052
2052

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











