







感知机的可变量是线性式中的权值w和偏差b,数学表达式是y=wx+b(这条线称为超平面),然后激活函数将低于这个线性式的信息抑制,低于线性式的信息激活,平面可视化为图3。
但是这种分离往往不是最优的,泛化性能不好。一个线性可分数据集的超平面有无数个,如何选取最优的那个呢?
SVM对此做出了改进。为了获得最优泛化性能的超平面,SVM首先根据KKT条件选取具有约束作用的支持向量(靠近边界的学习样本),通过几何间隔最大化的思想,将最优超平面的问题转化为支持向量与超平面欧氏距离最大化,再转化为带有一次项条件的L2范数(||w||)的最小化问题,见式3。
SVM在线性不可分的问题上也给出了自己的回答,它有创见地使用核函数取代映射函数,将学习样本映射在高维特征空间的同时降低计算复杂度,以便在高维求解最优超平面,解决了线性不可分问题。
SVM使用了与传统机器学习(如PCA、LDA)降维思想完全不同的升维思想,这打开了一个学习空间巨大的新世界,也启发了CNN的发展。SVM是浅层学习优秀的发展,具有坚实的数学理论基础。CNN则是受到猫的视觉皮层启发,走的是一条深度学习的路子。


图3
![]()
![]()
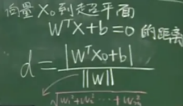

![]()
![]()
式3
我们知道多层感知机在层间是全连接的,如果输入为一张1000*1000像素的图片,连接到隐层,每个节点就需要 10^6 个权值参数和1个偏置参数参与计算,因为它使用的是全局感受野,每个神经元又相对独立,并不符合视觉图像的习惯(感兴趣区域可能只在一小块区域内),所以多层感知机在处理图片时并不适用。
为了摆脱这个困境,人们考虑不用全连接,而是一个区域一个区域地处理图片数据(局部感受野)。参考SVM的核函数概念,如果仍是1000*1000像素的图片,局部感受野为10*10,使用一个10*10的卷积核与遍历的位置相乘求和(卷积运算),作为提取到的局部特征,那么每个神经元只需要100个权值参数和1个偏置参数 (遍历时权值共享)。每个神经元的二维分布使得局部信息与空间信息同时得以保留。卷积核相当于感知机的权值,在反向传播中可学习更新。在处理多维图像时,如需改变通道数至n,则取用n个与原通道数相同的卷积核,卷积后对应位置相乘求和。如图4。得知CNN的来路,我们可以更坦然地考虑后人对它的改进。

图4















 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









