







首先是Resnet系列,原始的resnet网络在输入层有一个7*7,s=2的大卷积和3*3,s=2的最大池化层,中间层是由3*3或1*1小卷积组成的残差块的堆叠,输出层是一个全局平均池化和预测类别的全连接。
2.1 resnet-v2
在resnet-v2网络中[54],何恺明在原版的理论基础上做了组件的位置调换,如图8。在原有组件分布中,灰色路线的Relu在add之后,残差块的输出非负,不利于简化优化,所以Relu应放在右侧分支层,保持灰色路线add后数据分布不变。BN层应位于Relu层之前,因为mini-batch中梯度消失几乎不存在,正向传播时Relu层可以享受BN层的好处。又提出BN和Relu在权重层(卷积层)之前,作为残差单元的预激活,预激活与后激活效果相当,但add之前不应连接Relu层,因为Relu之后非负会影响数据分布。如此,Resnet-v2利用组件重组加速了 优化。
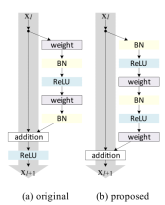 图8 resnet、resnet-v2的block对比
图8 resnet、resnet-v2的block对比
2.2 Wide ResNet
其后,人们又从增加模型宽度的角度优化残差模型,宽度指特征层的深度,Zagoruyko在2016年提出了Wide ResNet[55]。它解决了非shortcut支路不传递梯度,导致block块直接废掉的问题(即diminishing feature reuse特征重用减少问题)。解决方法是在每个残差块中添加dropout层。另改进了CNN结构,改进有三,一是增加每个残差块的卷积层(非shortcu支路卷积层数增加),二是增加卷积层的通道数(通道数*k,k是加宽因子 ),三是增加滤波器尺寸。经过实验,每个残差块的卷积层为两层深度最佳,网络宽度加倍带来的精度改善与网络深度加倍带来的精度改善相当。参数相当的情况下,WRN在深度缩水20多倍(WRN-40-4与ResNet1001),仍能保持八倍的训练速度,因为宽度增加更符合gpu并行运算的方式。
2.3 ResneXt
同年,Saining等人提出了ResneXt模型[56]。模型依然是改进残差块,思路与googlenet相似,都是走split-transform-merge(分割-变换-合并)的路线,如图9,但是与inception模块不同的是,它的支路是相同结构的拓扑组成的,并将支路数作为模型深度和宽度外的另一维度,称为“基数”。拓扑作为一个可扩展的维度,减少了人为设计,增加了泛化能力。拓扑结构导致结构的计算复杂度与原Resnet几乎相同,但精度提高了,如表1。滤波器设计借鉴VGG的小卷积堆叠思想,继承了resnet的瓶颈构架,因为卷积层数大于3时拓扑才有效。它还讨论了基数维度的组卷积,即原特征图通道数分为基数维度的组,分别做卷积计算后加和,可以降低计算量。
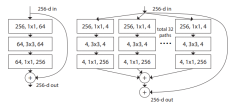 图9 resnet、resneXt的block对比
图9 resnet、resneXt的block对比
 表1 resnet-50 与resneXt-50复杂度对比
表1 resnet-50 与resneXt-50复杂度对比
2.4 Res2Net
2019年,南开大学、牛津大学和加州大学共同提出了一个Res2Net模型[57]。它解决的是在模型设计的角度上解决多尺度表达能力问题。随着VGG提出的小卷积堆叠思想的广泛利用,堆叠过程中的多尺度表达被注意并用于代替架构中特意设计的多尺度特征设计[58-61]。受架构多尺度特征设计的启发,Res2net的块结构把resnet瓶颈结构内的3*3小卷积做了改变,首先参考组卷积[56]将特征图依通道数分为s层,每层厚度为w(原通道数n=s*w),每层特征图使用一个3*3*w的小滤波器进行卷积,第一层直连,第二层输出与第三层输入融合后卷积,第三层输出与第四层输入融合后卷积,以此类推。所有层的输出在瓶径口的1*1卷积处融合,达到多尺度特征融合的目的,如图10。Res2net将s层称为一个新维度“scale”(规模)。Res2net由于其结构改进,在物体检测和分类方面表现出巨大潜力,模型复杂度也与基线模型大致相等。与分辨率相关的工作还有[62-67][77]。
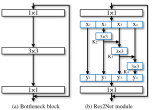 图10 res2net和resnet的block结构对比
图10 res2net和resnet的block结构对比
2.5 iResnet
2020年,Cosmin等人提出了iResnet,即改进残差网络模型[68]。它注意到resnet网络存在深层信息损失问题,思路是延续resnet-v2的进一步优化。它认为resnet-v2改善后的结构允许信息未经处理流入主路,其中shortcut的支线信息从未经数据分布的处理和非线性处理,这会限制学习能力。随着block叠加,shortcut的支线信息的数据分布会更加混乱,也不是最优的。对此它做出了三点改进。首先,为了解决信息损失和信息流动问题,iresnet将网络分段并对段的不同位置提出了开始,中间,结尾三个block块的设计,如图11。其中,开始模块的输入信息已经数据分布处理,开始模块的尾部BN在后且不做relu,可以同时作为中间模块的输入标准化处理,故中间模块的第一个BN被消除。结束模块的尾部在主线位置添加了BN和Relu,做为shortcut支线信息的数据分布处理和非线性处理,提高学习能力。一个主段结尾的数据分布处理相当于对下一主段的输出做处理。在Resnet50中,主要阶段为4段,故主线只会经过4次relu,不受深度影响,较小阻碍信号。由于只做了组件上的重组设计,模型复杂度不会增加。第二是shortcut的改进。在resnet中,shortcut的维度不匹配可以用身份映射来解决。原始的身份映射可以使用1*1小卷积使得维度对齐,但这种对齐是在空间和通道上都匹配的。如果block的输入特征图大而需要对齐的空间维度小,例如步长为2的小卷积,则会错失四分之三的信息。为了保留信息,iresnet在shortcut上的1*1小卷积之前添加了3*3的最大池化,使得空间维度上的所有像素都被考虑进去,最大池化的设置应保障卷积的步长为1,如图12。在非shortcut支路上进行对定位有利的软下采样,在shortcut支路上进行对分类有利的硬下采样,形成互补。这个改进也不会使模型复杂度增加。第三是使用分组卷积[38][56][57][69]对非shortcut支路上的3*3卷积进行的改进。分组卷积是将特征图通道分为几层(组),每层(组)使用一个小滤波器进行卷积,减少参数和计算量。由于组卷积的存在,模型得以在1*1小卷积后得到通道数更多的特征图,并分配给组卷积操作。通道数的扩长提高了3*3卷积的学习能力,如图13。Iresnet的多方面改进使得模型性能显著提升,模型深度可达3002层且持续优化。
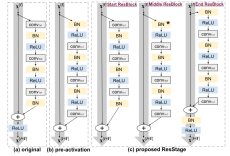 图11 resnet、resnet-v2、iresnet的block对比
图11 resnet、resnet-v2、iresnet的block对比
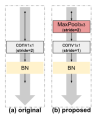 图12 resnet、iresnet在shortcut上身份映射的对比
图12 resnet、iresnet在shortcut上身份映射的对比
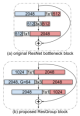 图13 iresnet在非shortcut支路上的通道数对比
图13 iresnet在非shortcut支路上的通道数对比
2.6 ResneSt
同年,Zhang等人引入通道注意力机制,提出了ResneSt,即分割-注意力网络[70]。它的块结构在非shortcut支路上做了基于组卷积和通道注意力机制的改进。首先输入的特征图为H*W*C,第一步分组,共K组,每组再切片,切R片。组内切片的特征图通道数为C/K/R,做1*1小卷积通道数不变,再做3*3卷积通道数变为C/K,把组内所有切片输出作为输入给切片注意力机制,如图14。切片注意力机制做的工作是,首先将所有切片输出加和,特征图为H*W*(C/K),求全局平均池化,特征图1*1*(C/K),连接DENSE(两个全连接),并做softmax,将得出的通道权重与原切片通道相乘,如图15。所有组的输出concat后,使用1*1小卷积调整通道数到与block输入一致,即为非shortcut支路上的输出。ResneSt是对SENet[71]、SKNet[72]、组卷积[56]的有效融合。
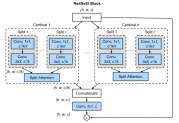 图14 resneSt的block
图14 resneSt的block
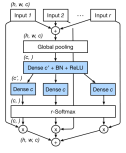 图15 resneSt的split attention结构
图15 resneSt的split attention结构
2.7 Regnet
可以看出,模型的block越来越复杂,设计方案也不可避免地走进了有用就塞进去用的境地,但设计的是否合理却只能用实验来证明。模型深度多深,宽度多宽,该分多少组,都只能靠设计者手工试,模型的设计似乎走进了不合理的瓶颈。
为了解决这个问题,同年,Radosavovic等人提出了Regnet模型[73]。它考虑的是一个良性网络的宽度、深度和组数等参数应当有一个线性关系之类的设计原则,也即设计空间的设计。作者准备衡量的参数有深度,宽度,瓶颈比和组数。实验设计的主体是一个Anynet(如resnet),anynet由三部分构成,分别是主干,身体,和头,我们保持主干和头部固定,探讨身体部分的参数影响。如图16,身体由4个stage构成,每个stage包含di(深度)个block,Block的宽度为wi,Block瓶颈结构的瓶颈比bi(输入block的通道数/第一个1*1小卷积后的通道数),Block在3*3卷积部分使用组卷积则组数为gi。实验的衡量方法是EDF(经验误差分布函数)。在设计空间采样500个模型参数并训练对应的模型,每个模型参数都进行低计算量(400MF)、低epoch(10)的大规模实验。实验结果得出:瓶颈比和组宽可以简化计算,但几乎不会影响EDF。瓶颈比bi<2时最佳,组宽gi>1时最佳,模型深度和宽度呈线性关系,如图17。根据线性关系,可以提出一个只有6个自由度,大小缩减10个数量级的regnet模型的设计规则。
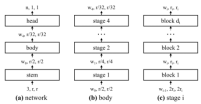 图16 anynet结构图
图16 anynet结构图
 图17 模型深度和宽度的线性关系,其中深度是对数
图17 模型深度和宽度的线性关系,其中深度是对数















 139
139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









