







一、逻辑回归
二、支持向量机
1.什么是支持向量机
支持向量机是一种二分类模型,它的目的是寻找一个超平面来对样本进行分割,原则是边界最大化,最终转化为一个凸二次规划的问题求解。
支持向量:在求解的过程中,只根据部分数据就可以确定分类器,这些数据称为支持向量
支持向量机:通过支持向量运算的分类器
当训练样本线性可分时,通过硬边界(hard margin)最大化,学习一个线性可分支持向量机
当训练样本近似线性可分时,通过软边界(soft margin)最大化,学习一个线性可分支持向量机
当训练样本不可分,通过和技巧和软边界最大化,学习一个非线性支持向量机
2. 核函数、核技巧
核函数:把原坐标系里线性不可分的数据用核函数 kernal 投影到另一个空间,尽量使得数据在新的空间线性可分。特点有以下:
- 避免维度灾难,大大减少计算量,而输入空间的维数 n 对核函数矩阵无影响。因此,核函数可以有效处理高维输入。
- 无需知道非线性变换函数 f f f的形式和参数。
- 改变输入空间到输出空间的映射,进而对特征空间的性质产生影响,最终改变各种核方法的性能
- 可以与不同的算法结合。
常见的核函数:
| 核函数 | 表达式 | 备注 |
|---|---|---|
| Linear kernal | k ( x , y ) = x t y + c k(x,y)=x^ty+c k(x,y)=xty+c | |
| Polynomial kernal | k ( x , y ) = ( a x t y + c ) d k(x,y)=(ax^ty+c)^d k(x,y)=(axty+c)d | d 为多项式次数 |
| Exponentiial kernal | k ( x , y ) = e x p ( − ∣ x − y ∣ 2 σ 2 ) k(x,y)=exp(-\frac{\left |x-y \right |}{2\sigma ^{2}}) k(x,y)=exp(−2σ2∣x−y∣) | σ > 0 \sigma>0 σ>0 |
| Gaussian kernal | k ( x , y ) = e x p ( − ∣ x − y ∣ 2 2 σ 2 ) k(x,y)=exp(-\frac{\left |x-y \right |^{2}}{2\sigma ^{2}}) k(x,y)=exp(−2σ2∣x−y∣2) | σ \sigma σ为高斯核的带宽, σ > 0 \sigma>0 σ>0, |
| Laplacian kernal | k ( x , y ) = e x p ( − ∣ x − y ∣ σ ) k(x,y)=exp(-\frac{\left |x-y \right |}{\sigma}) k(x,y)=exp(−σ∣x−y∣) | σ > 0 \sigma>0 σ>0 |
| Anova kernal | k ( x , y ) = e x p ( − σ ( x k − y k ) 2 ) d k(x,y)=exp(-\sigma(x^{k}-y^{k})^{2})^{d} k(x,y)=exp(−σ(xk−yk)2)d | |
| Sigmoid kernal | k ( x , y ) = t a n h ( a x t y + c ) k(x,y)=tanh(ax^{t}y+c) k(x,y)=tanh(axty+c) | t a n h tanh tanh为双曲正切函数, a > 0 , c < 0 a>0,c<0 a>0,c<0 |
3. SVM 的主要特点
- SVM 的基础理论是非线性映射,SVM 利用内积和函数代替向高维空间的非线性映射。
- SVM 的目标是对特征空间划分得到最优超平面,SVM 方法核心是最大化分类边界。
- SVM 的结果是支持向量,并且在分类中起决定作用。
- 适用于小样本,基本不涉及概率测度及大数定律。
- SVM 的最终决策函数只由少数的支持向量决定,计算复杂度取决于支持向量而非样本维数
- 非支持向量对结果没有影响
- SVM 问题表示为凸优化问题,因此可以寻找全局最小,局部最优也就是全局最优。
- SVM 通过最大化决策边界的边缘提供模型能力。尽管如此,用户必须提供其他参数,如使用和函数类型核引入松弛变量
- SVM 的优化目标是结构化风险最小(自带正则项)而不是经验风险最小,避免过拟合
4. 缺点
- 大规模样本难以实施,SVM 借助二次规划求解支持向量,求解二次规划涉及到 m 阶矩阵的运算(m 为样本个数)。
- 解决多分类存在困难,一般通过多个二分类器的组合解决多分类问题。
- 对缺失值敏感,尤其缺失值是支持向量的时候。对核函数敏感。
三、LR和SVM的联系
1. LR和SVM都是分类算法
普通的 LR 和 SVM 都只能处理二分类问题,当然,改进后的可以处理多分类问题
在不考虑和函数时,两者都是线性分类器。加了核函数 kernal 后分别为 KLR、KSVM。
2. 两者都是监督算法
3. 两者都是判别式模型
判别模型:假设给定观测集合 X,需要预测的变量集合为 Y,直接对条件概率分布 P(Y|X) 建模来预测Y;
生成模型:先求联合概率分布 P(X,Y),再计算边缘分布得到 P(Y|X)。
常见的判别模型有:LR、SVM、KNN、CNN、最大熵模型、条件随机场等
常见的生成模型:隐马尔可夫模型HMM,贝叶斯、高斯混合模型GMM等
四、LR和SVM不同
1. 采用的 loss function 不同
从目标函数看,LR采用的是 logistic loss,SVM采用的是hinge loss
LR loss:
L
(
w
,
b
)
=
∑
l
n
(
y
i
p
1
(
x
;
β
)
+
(
1
−
y
i
)
p
0
(
x
;
β
)
)
=
∑
(
−
y
i
β
T
x
i
+
l
n
(
1
+
e
β
T
x
i
)
)
L(w,b)=\sum ln(y_ip_1(x;\beta)+(1-y_i)p_0(x;\beta))=\sum{(-y_i\beta^Tx_i+ln(1+e^{\beta^Tx_i}))}
L(w,b)=∑ln(yip1(x;β)+(1−yi)p0(x;β))=∑(−yiβTxi+ln(1+eβTxi))
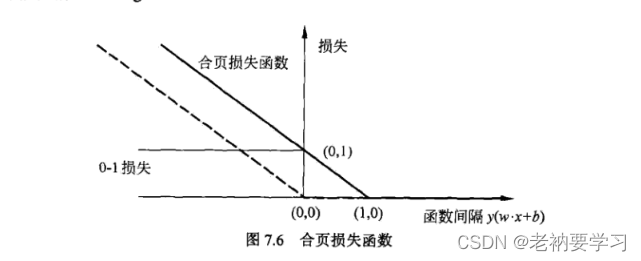
SVM Loss:又称合页函数。
L
(
w
,
b
,
α
)
=
1
2
∣
∣
w
∣
∣
2
+
∑
α
i
(
1
−
y
i
(
w
T
x
i
+
b
)
)
+
L(w,b,\alpha)=\frac{1}{2}||w||^2 + \sum\alpha_i(1-y_i(w^Tx_i+b))_+
L(w,b,α)=21∣∣w∣∣2+∑αi(1−yi(wTxi+b))+
表示当
y
i
(
w
T
x
i
+
b
)
y_i(w^Tx_i+b)
yi(wTxi+b)大于1时,loss为0,否则loss为
1
−
y
i
(
w
T
x
i
+
b
)
1-y_i(w^Tx_i+b)
1−yi(wTxi+b)
对比感知机的损失函数
−
y
i
(
w
T
x
i
+
b
)
-y_i(w^Tx_i+b)
−yi(wTxi+b),只要大于0,loss就为0。hinge loss 不仅要求分类正确,并且分类可信度足够高的时候,才能让 loss 变为0。
LR:基于极大似然估计求参数
SVM:基于 hinge loss 求参数
2. 考虑的边界点数
SVM 只考虑边界上的局部点,即支持向量,其他样本对分类决策没有影响,即SVM不依赖于数据的分布。
LR 依赖于数据分布,通过线性映射减少远离分类平面的点的权重,即对不平衡的数据要先做平衡。
3. 核函数的使用
SVM使用的是 hinge loss ,可以方便转换成对偶问题求解,在解决非线性问题时,引入核函数机制可以大大降低计算复杂度。
4. SVM 依赖于数据分布的距离测度,所以需要先对数据归一化,而LR不受影响
5. SVM损失函数自带正则项,而LR需要另外添加
LR和SVM什么时候用?
- feature数远大于样本数,都可以
- feature数与样本差不多,可以使用 KSVM
- feature较小,样本很大,可以增加更多 feature 然后使用 LR 或linear SVM
LR 和 SVM 如何处理多分类问题?
SVM:
方式一:组合多个二分类器实现多分类
1.OvO(one-versus-one):任意两个类别之间设计一个二分类器。
2.OvR(one-versus-rest):每次将一个类别作为正例,其余作为反例,共 N 个分类器。
方式二:直接修改目标函数,将多个分类面的参数合并到一个最优化问题,一次性实现多分类。
LR
方式一:组合多个二分类器
方式二:改成 softmax 回归














 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









