







首先我们先来理解一下FPS的概念:
FPS即Frames per second,当我们准备测试流畅度的时候,必须先理解两个关键指标60帧每秒以及16.67毫秒,这两个值代表什么意思?怎么得来的?
用过flash的人应该知道动画片其实是由一张张画出来的图片连贯执行产生的效果,当一张张独立的图片切换速度足够快的时候,会欺骗我们的眼睛,以为这是连续的动作。反之类推,当你的图片切换不够快的时候,就会被人眼看穿,反馈给用户的就是所谓的卡顿现象。
想要让大脑觉得动作是连续的,至少是每秒10-12帧的速度,而想达到流畅的效果,至少需要每秒24帧。这也是为什么电影片源通常都是24帧的原因。不过60帧每秒的流畅度是最佳的,我们的目标就是让程序的流畅度能接近60帧每秒,当然超过60帧速的话大部分人还是会受不了的。
综上所述,APP需要尽可能的超过24帧/秒,接近60帧/秒的速度,并且在使用的过程中保持这个速率,试想一下你吃着火锅看着电影,突然图像发生了跳跃或者画面撕裂,那种感觉就像米饭里吃到了沙子一样极度不爽,因此这意味着我们的程序需要在16.67ms内处理一幅画面内的所有事,并保持住这个状态。
计算公式:1000ms / 60 frames ≈ 16.67 ms/frames
如下转自:https://www.expreview.com/24507-all.html
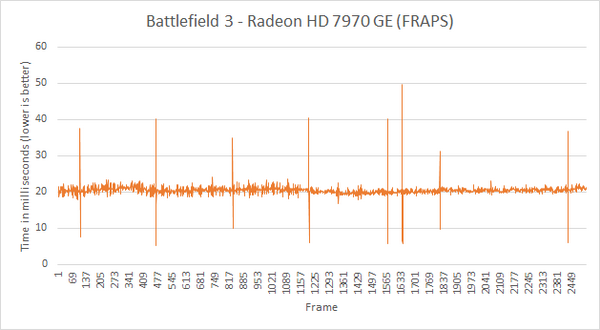
在昨天的GTX 650 Ti Boost显卡评测一文中,有读者提到我们的显卡评测缺少帧时间统计,这个问题我们一直在关注,因为帧时间的讨论还引出了另一个问题:AMD显卡的游戏的卡顿现象。
这个问题最早是从Techreport的HD 7950与GTX 660 Ti对比测试开始的,因为TR认为HD 7950性能虽然比GTX 660 Ti要高,但是在有些游戏里会感到更卡,正是因为它的帧时间不够稳定,每帧生成时间波动太大了。实际的感受就变成有时流畅,有时候就会卡。
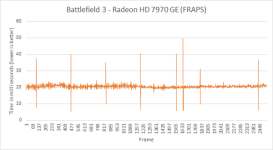
很快Tomshardware也跟进了,但也有个别媒体用自己的方式来测试,Pcper使用了一个高端的双链DVI接口的数据采集卡来收集整个显卡输出的数据,包括帧率、帧时间等等,再通过这些数据来分析游戏的帧速分布。
除了游戏内建Benchmark,使用Fraps软件记录游戏帧时间的测试方式早被大众认可,很多读者也认为这种方式比平均帧要更可靠,但是我们对帧时间的了解不多,对这种测试方式心存怀疑。非常应景的是,Anandtech网站昨晚撰文分析了这个问题,而且还有专业的AMD技术人员讲解3D渲染的过程及Fraps记录帧率的原理,帮助我们从另一个角度来看清什么是帧延迟,什么才是真正的卡顿。
值得一提的是,在各家媒体的测试中AMD显卡都是毫无疑问的“受害者”,因为他们的帧时间显得波动很大,表现不如竞争对手,很多消费者估计也会受此影响。不过,AMD既没有站出来大声反击这些质疑,也没有完全沉默不言,他们想坐下来谈谈帧延迟的问题,告诉大家他们是怎么想的。
原文内容非常理论化,内容也很长,所以我按照原文的流程分成几个部分精简的介绍一下。
◆ 显卡的3D渲染过程以及延迟的真正定义
解释帧时间之前需要先了解一下Windows系统的渲染过程(Rendering Pipeline)。渲染过程本身并不复杂,但是因为要涉及到Windows系统、CPU、GPU以及驱动等层面,需要知道是哪个环节出了问题才造成延迟的。
从基本原理上看,渲染主要有3个过程,应用程序需要将数据传递给Windows系统,Windows则通过驱动管理这个处理过程,最后等系统和驱动准备完成了,GPU就会输出一帧图像并显示出来。
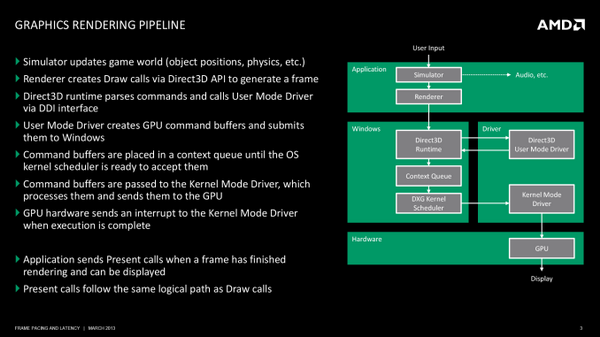
长话短说,Windows系统中负责管理的就是Direct3D API,它是DX API中最主要的3D渲染API,是一个庞大的、复杂的API命令与函数的的集合。D3D首先也是最主要的作用就是收集应用程序的各种绘制命令(draw),并将其结合起来,为进一步的工作做处理。一旦某个完整帧的帧绘制命令都收集完了,D3D就会把它处理完成的工作传递给显卡驱动堆栈的第一个组成部分——UMD( User Mode Driver)。
UMD主要负责D3D的输出,并将其变成GPU可以处理的工作批次(work batches)。这些工作批次、命令缓冲器(也叫做显示列表,Display Lists)都是适合目前GPU处理的指令及数据的集合。
UMD另外一个工作就是着色器编译(shader compilation)以及将正确而且最适合的表面格式(surface formats)分配给GPU。

UMD的工作完成之后,它就会把命令缓冲器传递回D3D,D3D再依次把命令交给上下文队列(context queue),这是可能会造成卡顿的第一个瓶颈,至于它为什么会造成瓶颈,后面还会继续讲到。
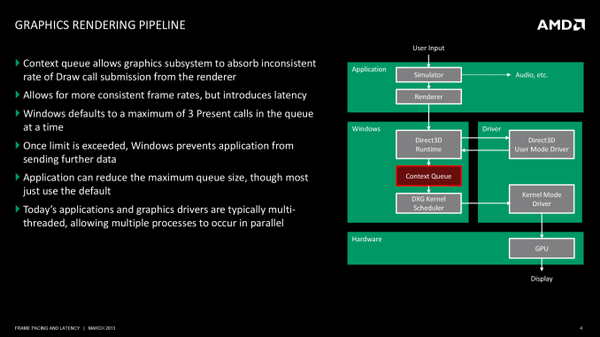
上下文队列之上还有GPU调度器,它负责管理原本应该通过context queue送到KMD( kernel mode GPU driver)而实际上却脱离的命令缓冲导致的爆音(popping)意外。
通过上面的一系列过程我们在GPU的后端缓冲器里最终渲染出了一帧完整的图像,但是这一帧并不会自动输出到显示设备上,命令缓冲器批次的最后一步是Direct3D Present,Present命令的作用就是告诉GPU将后端缓冲器发到前端,然后将渲染的图像输出给用户,只有present指令执行完之后图像才会输出。
以上就是一个3D渲染过程的简单介绍,下面我们再来看看什么是真正的帧延迟。
延迟的真正定义
卡顿(shutting)的定义有很多,实际中我们一般这么定义:任何可能导致每帧时间显著变化的情况都可以定义为卡顿,这是一个通用的定义,但是造成卡顿的情况有很多,还得分别来看。
Anandtech将卡顿分为单卡卡顿和多卡卡顿两个部分来讲,不过首先还是看各种可能造成卡顿的原因。如果GPU用了超过预期的时间(要知道不可能先于时间精确预计需要渲染多少次)来渲染图像这就会造成卡顿;如果驱动程序需要等待很长时间才能为GPU准备好需要渲染的某一帧,这也会造成卡顿;如果游戏的仿真步长( simulation step)用了很长时间也会导致卡顿;如果CPU/OS太忙导致不能预期发送指令也会导致卡顿,总之就是造成卡顿有各种可能,每一个步骤出了意外情况都可能导致卡顿现象发生。
而造成这些现象的根本原因是Windows系统并不是一个实时操作系统(real-time operating system),这意味着它不能在某个周期内执行任意的一条指令,只有当它准备好执行的时候才可以进行操作。为了达到这种毫秒级的反应,应用和驱动程序需要确保每个过程都是平滑进行的。
虽然Windows系统一直在努力保证各项工作都是即时进行的,但是要知道PC是由各种各样的硬件组成的,种类和数量都非常庞大,这就造成了它很难消除卡顿。
最回到我们的问题上来,如果禁用了垂直同步,卡顿就是一个很常见(虽然不是一直出现)的问题。如果开了垂直同步,以目前LCD的60Hz刷新率来算,平均生成每帧至少需要16.6ms。由于60fps这个限制,开了垂直同步之后,任何低于16.6ms的帧生成时间都会被阻挡在上下文队列中,这种固定16.6ms的帧时间就大大减少了卡顿现象。
如果读者需要进一步了解垂直同步及三重缓冲的信息,可以翻阅几年前我们论坛版主privater翻译的Anandtech的另一篇文章
在讨论帧时间时我们还必须要区分两个定义,一个是延迟(latency),一个是帧间隔(frame interval)。延迟在这里的定义是指完整渲染完一帧图像的时间,而帧间隔跟延迟有关,但是又不同,它指的是每帧的间隔时间,典型的来说就是在渲染完成的末尾、正在显示的每帧间隔时间。
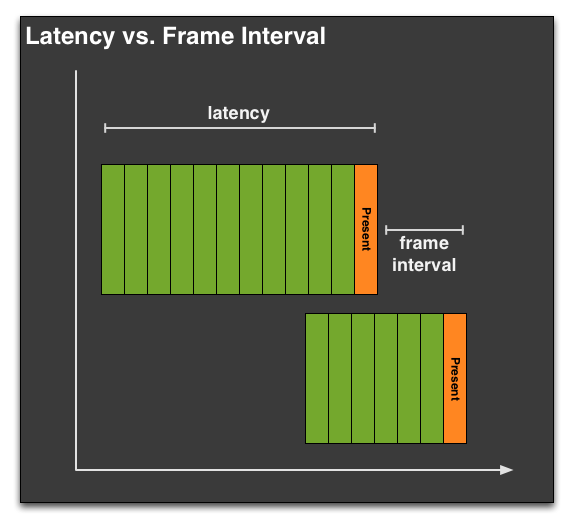
这张图更好理解,延迟是完成一帧的渲染时间,帧间隔则是负责发送输出指令的两个present命令之间的时间。
我们通常所说的卡顿实际上并不是这个延迟决定的,而是帧间隔(frame interval)时间决定的。帧延迟可以用独立测量出来,fraps软件就是最常用的工具了。我们这里谈的则是帧间隔。
虽然我们可以建立一个存在帧间隔分割点的模型,在这个点上可以视其为卡顿或者不卡顿,但是帧间隔这个概念对每个人的感觉也是不同的,生成这一帧需要的时间比前一帧多了5ms,这样会导致卡顿吗?10ms?20ms?30ms?如果是在30fps vs 60fps之间呢?
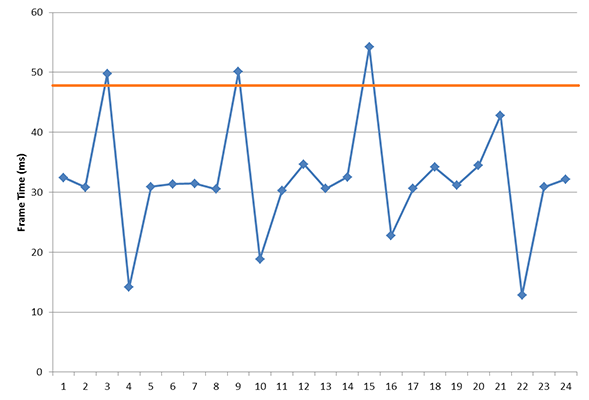
在与AMD的交谈中,AMD就提出了这样一个简单而又重要的问题:我们可以用工具客观测量出卡顿的存在,但是我们不能客观地衡量卡顿对每个用户的影响。
下面的讨论就有点哲学味道了,总之Anandtech及AMD更倾向于认为卡顿这个事就算可以测量出来,但是它对每个人的影响也是很难评估的。
在了解了3D渲染过程以及什么才是卡顿的真正定义之后,我们再回头看看frpas这类软件是如何捕捉延迟的,是否真的靠谱。
◆ Fraps记录延迟为什么不靠谱及总结
Fraps记录帧速解读
Fraps软件的名头和作用不用多费笔墨了,这个软件是评测编辑最常用的工具之一,很多没有内建benchmark工具的程序及游戏都是靠Fraps来手动测量的,其截图、录像功能也非常实用。
虽然它很实用,但是AMD还是认为这个软件有问题,它记录的帧时间并不一定准确。
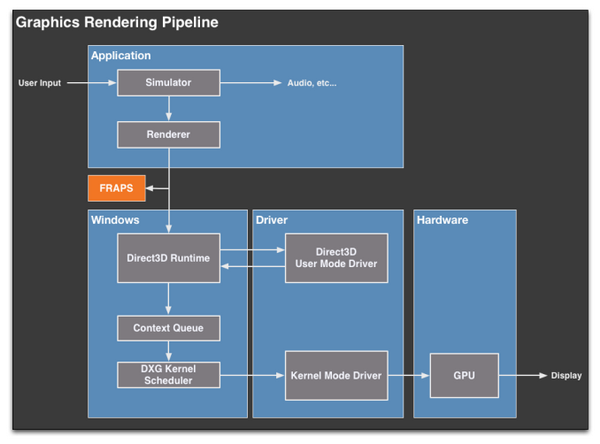
还是要先了解一下Fraps的工作原理,它通过dll文件注入到应用程序中,然后开始拦截D3D Present命令,在这里Fraps可以延迟输出指令以便插入自己的绘制指令。当用户按键激活帧数及帧时间测试时,Fraps就会计算present指令,当它每次察觉到发出一个present指令之后就会记录下来,认为生成了一帧新图像,然后再允许present指令通过。
这套流程对大部分应用都很管用,这也是Fraps如此受欢迎的原因之一。用Fraps软件测量游戏的平均帧还好,但是用它来测量游戏的帧间隔(也就是我们说的延迟、卡顿的原因)就不靠谱了。
Fraps过早地开始注入渲染过程,它比GPU优先、比驱动程序还要优先,甚至比D3D还以及context queue还要优先,因此Fraps可以告诉你进入渲染过程之前发生了什么,但是它无法告诉你渲染完成之后发生了什么,而真正决定游戏卡顿与否的关键就在后一个阶段上。
因此用Fraps来判断游戏卡顿与否是有问题的。从前面的渲染过程介绍中我们知道,只有当context queue准备好接受指令之后程序才会开始渲染新的一帧图像,而Fraps记录的只是渲染开始的部分,并非整个渲染过程,因此它只能告诉你它看到了什么,而不能告诉你渲染末期的帧间隔。
AMD对Fraps担忧的问题有两点,首先根据我们前面的定义,Fraps实际上是不能真正测量游戏的延迟的,context queue会阻挡任何试图测量真正的帧延迟的努力,两个present指令之间的时间并不等于渲染完成一帧所需的时间,特别是在下一个present指令因为任何原因被延迟的情况下,二者更没有关系了。
AMD的第二个顾虑就是Fraps越来越多地被用作帧延迟的测量工具,但是因为它过早介入了渲染过程,实际上它看到的延迟并非用户感受到的,如果Fraps认为AMD显卡有更多卡顿但是用户并没有感觉到这个问题,这是AMD显卡的错吗?
需要指出的是,我们的最终目标还是尽可能将卡顿变得更小更少,而AMD也在为这个目标而努力,但是让AMD担心的是Fraps测量的结果使得他们显卡的卡顿现象看起来更多了。

AMD对fraps软件的看点与评价
原文后面还有很多内容,包括对另一个测量工具GPU View的分析,还有单卡下的卡顿及多卡系统下的卡顿问题的探讨,不过我们的目的现在已经达到了,来看看最后的总结吧。
总结:
Anandtech这篇文章很强大,虽然读起来会比较费力,但是多多少少让我们了解了显卡的渲染过程以及什么才是真正的延迟,对Fraps原理的解析也有助于我们理解为什么AMD认为Fraps软件测量的“延迟”并不能成为真正的延迟,这也是Anandtech网站没有采用帧延迟的方式来衡量显卡性能的原因之一。
原文的总结部分也很长,长话短说就是AMD以及NVIDIA对滥用Fraps帧时间测试的评测方法也是有一定顾虑的,不过AMD的态度还不错,他们也承认了测试反应出的问题,并且在驱动中不断优化这个问题,毕竟就算Fraps测量的不准,记录出来的结果中N卡的卡顿还是要比A卡平均好一些。
Anandtech说他们也在考虑新的测试方法,未来几周就会露面。这对我们来说也是一个提醒,超能习惯用的测试成绩表格主要是基于平均帧数,平均帧或许很粗略,但是从小编使用几年的感觉来说它还是有说服力的,因为帧时间以及最低帧给我的感觉是太随机了,同一个测试重复几次得到的结果都不一样,反倒是平均值更有可重复可验证性。
当然,我们也不会就此停步不前,也会尝试用更多的方式来展现所测产品的真实性能,这一点还会继续改进。
最后,Anandtech也强调了他们这篇文章不是否定Fraps的价值,它依然是一个非常好用、实用的测量工具。

















 5021
5021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









