







 本文介绍了k近邻(k-Nearest Neighbor, KNN)算法的基本概念,包括算法概述、距离计算和可视化,并通过一个电影分类的例子进行深入解释。然后,展示了使用Python3.5实现KNN的详细步骤,包括数据准备、算法实现和完整代码。文章还总结了KNN算法的优缺点,并给出了K值选择和优化改进的建议。"
133391577,9784150,血肿与水肿建模:2023年研究生数学建模竞赛E题分析,"['数学建模', '医学研究', '数据分析', '统计方法', '疾病治疗']
本文介绍了k近邻(k-Nearest Neighbor, KNN)算法的基本概念,包括算法概述、距离计算和可视化,并通过一个电影分类的例子进行深入解释。然后,展示了使用Python3.5实现KNN的详细步骤,包括数据准备、算法实现和完整代码。文章还总结了KNN算法的优缺点,并给出了K值选择和优化改进的建议。"
133391577,9784150,血肿与水肿建模:2023年研究生数学建模竞赛E题分析,"['数学建模', '医学研究', '数据分析', '统计方法', '疾病治疗']
转载请注明作者和出处:http://blog.csdn.net/u013829973
系统版本:window 7 (64bit)
python版本:python 3.5
IDE:Spyder (一个比较方便的办法是安装anaconda,那么Spyder和jupyter以及python几个常用的包都有了,甚至可以方便的安装TensorFlow等,安装方法链接)
代码和数据集在: GitHub
k近邻算法
1.1 k近邻算法概述
k近邻(k-nearest neighbor,KNN)是一种基本的分类与回归算法。于1968年由Cover和Hart提出。k近邻的输入是实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k近邻算法假设给定一个训练数据集,其中的实例类别已定,分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻法不具有显式的学习过程。简单的说,给定一个训练数据集,对新的输入实例,在训练集中找到与该实例最近邻的k个实例,这k个实例的多数属于哪个类,就把该输入实例分为这个类。这就是k近邻算法中k的出处,通常k是不大于20的整数。
k近邻算法的三个基本要素:k值的选择、距离度量、分类决策规则
下面我们就用一个简单的例子来更好的理解k近邻算法:
已知表格的前四部电影,根据打斗镜头和接吻镜头判断一个新的电影所属类别?
| 电影名称 | 打斗镜头 | 接吻镜头 | 电影类型 |
|---|---|---|---|
| 1 | 3 | 104 | 爱情片 |
| 2 | 2 | 100 | 爱情片 |
| 3 | 99 | 5 | 动作片 |
| 4 | 98 | 2 | 动作片 |
| 未知电影? | 18 | 90 | 未知 |
已知的训练集包含两个特征(打斗镜头和接吻镜头)和类别(爱情片还是动作片)。根据经验,动作片往往打斗镜头比较多,而爱情片往往就是接吻的镜头比较多了。但是knn算法可没有我们这么感性的认识。
1.2 可视化与距离计算
我们首先对训练数据进行可视化:
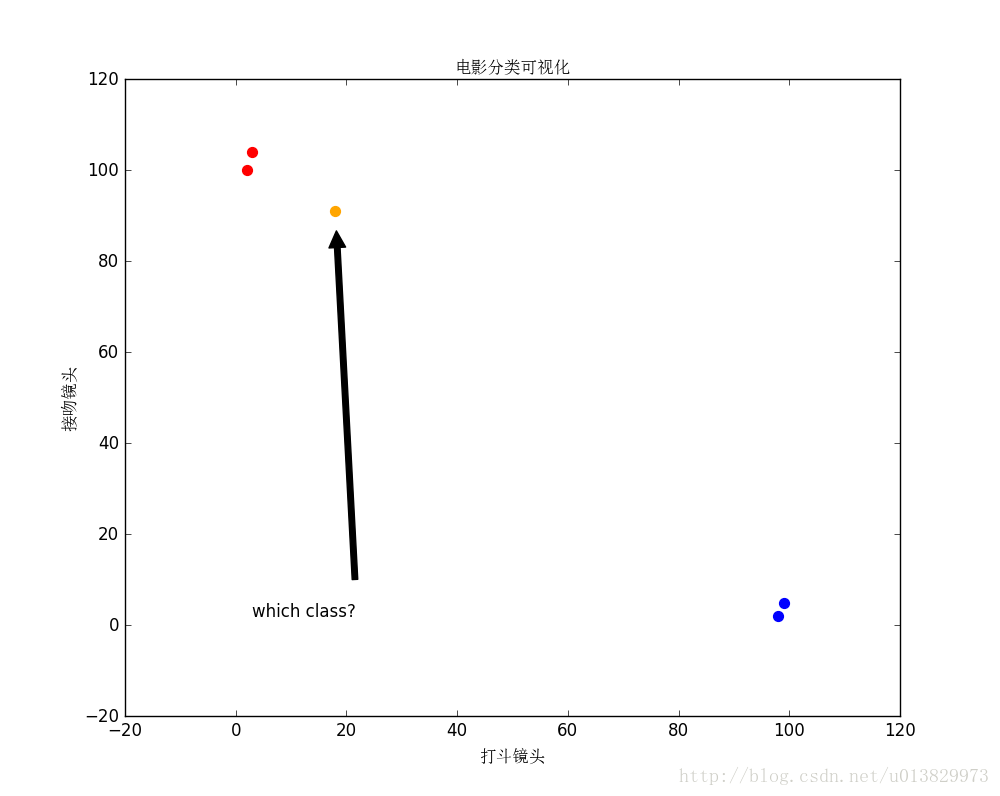
图1.1 电影分类(图中的红色点代表爱情片,蓝色点代表动作片,橙色点代表未知电影)
那么,knn是通过计算什么来判断未知电影属于哪一类的呢?答案:距离。我们首先计算训练集的所有电影与未知电影的欧式距离:(这里的距离除了欧式距离,还有曼哈顿距离、切比雪夫距离、闵可夫斯基距离等等)
欧式距离(Euclidean Distance)计算公式:两个n维向量 a(x11,x12,…,x1n)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3680
3680

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









