







/** Spark SQL源码分析系列文章*/
Spark SQL的核心执行流程我们已经分析完毕,可以参见Spark SQL核心执行流程,下面我们来分析执行流程中各个核心组件的工作职责。
本文先从入口开始分析,即如何解析SQL文本生成逻辑计划的,主要设计的核心组件式SqlParser是一个SQL语言的解析器,用scala实现的Parser将解析的结果封装为Catalyst TreeNode ,关于Catalyst这个框架后续文章会介绍。
一、SQL Parser入口
Sql Parser 其实是封装了scala.util.parsing.combinator下的诸多Parser,并结合Parser下的一些解析方法,构成了Catalyst的组件UnResolved Logical Plan。
先来看流程图:
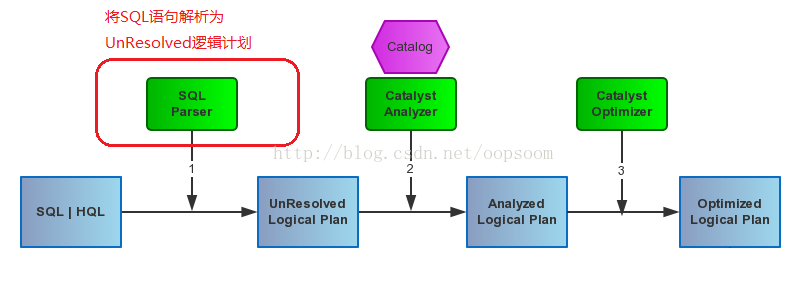
一段SQL会经过SQL Parser解析生成UnResolved Logical Plan(包含UnresolvedRelation、 UnresolvedFunction、 UnresolvedAttribute)。
在源代码里是:
-
def sql(sqlText: String): SchemaRDD = new SchemaRDD(this, parseSql(sqlText))//sql("select name,value from temp_shengli") 实例化一个SchemaRDD -
protected[sql] def parseSql(sql: String): LogicalPlan = parser(sql) //实例化SqlParser -
class SqlParser extends StandardTokenParsers with PackratParsers { -
def apply(input: String): LogicalPlan = { //传入sql语句调用apply方法,input参数即sql语句 -
// Special-case out set commands since the value fields can be -
// complex to handle without RegexParsers. Also this approach -
// is clearer for the several possible cases of set commands. -
if (input.trim.toLowerCase.startsWith("set")) { -
input.trim.drop(3).split("=", 2).map(_.trim) match { -
case Array("") => // "set" -
SetCommand(None, None) -
case Array(key) => // "set key" -
SetCommand(Some(key), None) -
case Array(key, value) => // "set key=value" -
SetCommand(Some(key), Some(value)) -
} -
} else { -
phrase(query)(new lexical.Scanner(input)) match { -
case Success(r, x) => r -
case x => sys.error(x.toString) -
} -
} -
}
1. 当我们调用sql("select name,value from temp_shengli")时,实际上是new了一个SchemaRDD
2. new SchemaRDD时,构造方法调用parseSql方法,parseSql方法实例化了一个SqlParser,这个Parser初始化调用其apply方法。
3. apply方法分支:
3.1 如果sql命令是set开头的就调用SetCommand,这个类似Hive里的参数设定,SetCommand其实是一个Catalyst里TreeNode之LeafNode,也是继承自LogicalPlan,关于Catalyst的TreeNode库这个暂不详细介绍,后面会有文章来详细讲解。
3.2 关键是else语句块里,才是SqlParser解析SQL的核心代码:
-
phrase(query)(new lexical.Scanner(input)) match { -
case Success(r, x) => r -
case x => sys.error(x.toString) -
}
可能 phrase方法大家很陌生,不知道是干什么的,那么我们首先看一下SqlParser的类图:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3153
3153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









