







原文:
Deep Learning Meets Recommendation Systems
Published by Wann-Jiun Ma at ** January 24, 2017
https://blog.nycdatascience.com/student-works/deep-learning-meets-recommendation-systems/
Contributed by Wann-Jiun Ma. He is currently attending the NYC Data Science Academy Online Data Science Bootcamp program. This post is based on his final capstone project and is finished in two weeks (part-time).
Introduction
几乎每个人都喜欢花时间与家人和朋友一起观看电影。 当我们坐在我们的沙发上选择我们将要在接下来的两个小时里观看的电影时,结果花费了20分钟也找不到一个合适的电影,这样的经历真是太令人失望了 当我们需要选择电影并且节省时间时,我们绝对需要计算机程序向我们推荐电影。显然,电影推荐已经成为我们生活的重要组成部分。 据数据科学中心 Data Science Central 统计,尽管数据很难得到,但据很多知情人士估计,对于像亚马逊和Netflix这样的主要电子商务平台,推荐系统可能会承担多达10%至25%的增量收入。在这里,我研究了电影推荐的一些基本推荐算法,并尝试将深度学习整合到我的电影推荐系统中。
电影是娱乐和视觉艺术相结合的绝佳例子。电影海报通常可以直接快速的将电影的情况传递给观众。根据 DesignMantic的说法,“任何电影的发布和预先发布,他们的海报是引发炒作的主要因素,一半以上的人(即目标受众)是基于电影海报决定是否预订门票并观看电影“。我们甚至可以通过查看海报的排版来预测任何电影的氛围场景(movie’s mood by just looking at the typography of is poster)。这听起来有点像魔术,但绝对有可能通过查看其海报来预测电影的流派。对于我自己,我只是看它的海报来决定是否看电影。例如,既然我不是漫画电影的粉丝,所以每当我看到有卡通主题或颜色的电影海报,我知道这些电影不是我的选择之内。这个决策过程非常简单,不需要任何评论阅读(不确定人们有时间阅读评论)。因此,除了一些标准的电影推荐算法之外,我还使用深度学习来处理电影海报,并尝试寻找类似的电影给用户推荐。目标是模仿人类的视觉能力,并通过观看基于深度学习的电影海报来构建直观的电影推荐者。这个项目的灵感来自Ethan Rosenthal的博文 Ethan Rosenthal’s blog posts ,我在他的博文中修改了他的代码,以适应这里使用的算法。
我们使用从MovieLens网站MovieLens 下载的电影数据集。 该数据集由1071个用户应用于9,066部电影的100,000个评级和1,300个标签应用程序组成。 数据集最近更新于10/2016。
Collaborative Filtering
大致来说,有三种类型的推荐系统(不包括简单排名方法):
- 基于内容的推荐
- 协同过滤
- 混合模型
对于基于内容的推荐系统content-based recommendation ,这是一个回归问题,我们尝试使用项目内容作为特征进行用户到项目的评分预测。另一方面,对于基于协同过滤的推荐系统 collaborative filtering ,我们通常不会提前知道特征内容,并且通过使用不同用户之间的相似性(用户可以给出相同项目的相似评分)和项目之间的相似性(类似的电影可能会被用户评分相似),我们会学习潜在的特征,同时对用户对商品的评分做出预测。另外,在学习了项目的特征之后,我们可以根据以前的使用信息来测量项目之间的相似度,并向用户推荐最相似的项目。基于内容和协作过滤的建议是十多年前的最先进的技术。显然,有许多不同的模型和算法来提高预测性能。例如,对于我们预先没有用户到项目评级信息的情况,我们可以使用所谓的隐性矩阵因式分解 implicit matrix factorization,并用一些偏好和置信度度量来替换用户到项目的评级,例如用户点击相应项目执行协作过滤的次数。此外,我们还可以结合基于内容的协同过滤方法,将内容用作“侧面信息”来提高预测性能。这种混合方法通常通过“学习排名”算法”Learning to Rank”实现。
在这个项目中,我将重点放在基于协同过滤的方法上。首先,我将讨论使用项目(用户)相似度来进行用户对项目的评估预测而无需回归,也可以根据项目的相似度进行推荐。然后,我将讨论如何使用回归来学习潜在的特征并同时做出建议。之后,我们将会看到如何在推荐系统中使用深度学习。
Item Similarity
对于基于协同过滤的推荐系统,第一个构建块构建了每个行代表用户的评分矩阵,每列对应于该用户给予特定电影的平分。 我们建立我们的评分矩阵如下:
df = pd.read_csv('ratings.csv', sep=',')
df_id = pd.read_csv('links.csv', sep=',')
df = pd.merge(df, df_id, on=['movieId'])
rating_matrix = np.zeros((df.userId.unique().shape[0], max(df.movieId)))
for row in df.itertuples():
rating_matrix[row[1]-1, row[2]-1] = row[3]
rating_matrix = rating_matrix[:,:9000]其中“ratings.csv”包含用户ID,电影ID,评分和时间信息,“link.csv”包含电影ID,IMDB id和TMDB id。 我们结合这两个表,因为每个电影需要IMDB id信息才能从电影数据库网站 The Movie Database使用其API获取电影海报。 我们检查我们的评分矩阵的稀疏度如下:
sparsity = float(len(ratings.nonzero()[0]))
sparsity /= (ratings.shape[0] * ratings.shape[1])
sparsity *= 100其中评分矩阵稀疏,只有非零项的1.40%。 现在,为了训练和测试,我们将评级矩阵分成两个较小的矩阵。 我们从评级矩阵中移除10个评级,并将它们放在测试集中。
train_matrix = rating_matrix.copy()
test_matrix = np.zeros(ratings_matrix.shape)
for i in xrange(rating_matrix.shape[0]):
rating_idx = np.random.choice(
rating_matrix[i, :].nonzero()[0],
size=10,
replace=True)
train_matrix[i, rating_idx] = 0.0
test_matrix[i, rating_idx] = rating_matrix[i, rating_idx]
where, s(u,v) *is just the cosine similarity measure between user *u and user v.
similarity_user = train_matrix.dot(train_matrix.T) + 1e-9
norms = np.array([np.sqrt(np.diagonal(similarity_user))])
similarity_user = ( similarity_user / (norms * norms.T) )
similarity_movie = train_matrix.T.dot(train_matrix) + 1e-9
norms = np.array([np.sqrt(np.diagonal(similarity_movie))])
similarity_movie = ( similarity_movie / (norms * norms.T) )使用用户之间的相似性,我们能够对每个用户对电影的评分进行预测,并且还可以计算我们的用户到电影评分预测的相应MSE。 通过考虑类似用户给出的评级来进行预测。 特别是,我们可以根据以下公式进行用户到电影的评分预测。
rˆui=(∑is(u,v)rvi∑v∥s(u,v)∥)
其中用户u到电影i的预测是用户v给予电影i的用户u和v之间的相似度作为权重的等级的加权和(归一化)。
from sklearn.metrics import mean_squared_error
prediction = similarity_user.dot(train_matrix) / np.array([np.abs(similarity_user).sum(axis=1)]).T
prediction = prediction[test_matrix.nonzero()].flatten()
test_vector = test_matrix[test_matrix.nonzero()].flatten()
mse = mean_squared_error(prediction, test_vector)
print 'MSE = ' + str(mse)我们的预测获得的MSE是9.8252。 这个数字是什么意思? 这是好还是坏的推荐? 通过查看MSE得分来评估我们的预测性能不是非常直观。 因此,我们通过直接查看电影推荐来评估表现。 我们会查询感兴趣的电影,并要求我们的系统向我们推荐几部电影。 首先要做的是获取相应的电影海报,以便我们可以看到推荐的电影是什么。 我们使用IMDB ID号码从电影数据库网站 The Movie Database使用其API获取电影海报。
import requests
import json
from IPython.display import Image
from IPython.display import display
from IPython.display import HTML
idx_to_movie = {}
for row in df_id.itertuples():
idx_to_movie[row[1]-1] = row[2]
idx_to_movie
k = 6
idx = 0
movies = [ idx_to_movie[x] for x in np.argsort(similarity_movie[idx,:])[:-k-1:-1] ]
movies = filter(lambda imdb: len(str(imdb)) == 6, movies)
n_display = 5
URL = [0]*n_display
IMDB = [0]*n_display
i = 0
for movie in movies:
(URL[i], IMDB[i]) = get_poster(movie, base_url)
i += 1
images = ''
for i in range(n_display):
images += "<img style='width: 100px; margin: 0px; \
float: left; border: 1px solid black;' src='%s' />" \
% URL[i]
display(HTML(images)) 现在,这很有趣! 我们来看看我们的建议。 我们将显示四个最相似的电影以及我们查询的动作。 我们查询的电影放在左边,后面是四个推荐的电影。 我们来试试查询“Heat”。

Heat是1995年的美国犯罪电影,由Robert De Niro,Al Pacino主演。 结果看起来不错 离开拉斯维加斯可能不是一个很好的建议。 我猜是因为Nicolas Cage在电影“The ROCK”中,对于热爱的观众来说,这是一个很好的推荐。 因此,它可能是使用相似矩阵与协同过滤的缺点之一。 我们来试试更多的例子。

看起来不错,Toy Story 2绝对应该向喜欢Toy Story的观众推荐。 但是,Forrest Gump对我来说并没有太大的意义。 显然,汤姆·汉克斯(Tom Hanks)的声音在玩具总动员电影中,所以推荐了阿甘。 请注意,只要查看海报,就可以在玩具总动员和福雷斯特·甘普之间分辨出电影类型,情绪等差异,对吧? 当他看到海报假设每个孩子都喜欢玩具总动员时,孩子可能会忽略Forrest Gump。
Alternating and Stochastic Gradient Descent
在前面的讨论中,我们简单地计算用户和项目的余弦相似度,并使用这种相似性度量来预测用户对项目的评分,并提出项目到项目的推荐。 我们现在把我们的问题作为一个回归问题。 我们为所有用户引入所有电影和权重向量x的潜在特征。 目标是简单地将评分预测的MSE(L2规范正则化术语)最小化。
rˆui=xTuyi
L=∑u,i(ru,i−xTuyi)2+λ∑u∥xu∥+σ∑∥yi∥
注意,现在权重向量和特征向量都是决策变量。 显然这并不是一个凸问题。 就目前来说,不用担心这个非凸的问题的收敛性。 有很多方法来解决这个非凸优化问题。 一种方法是以交替的方式求解权重向量(用户)和特征向量(用于电影)。 当我们求解权重向量时,我们假定特征向量是常数向量。 另一方面,当我们解决特征向量时,我们假设权重向量是常数向量。 解决这个回归问题的另一种方法是组合权重向量和特征向量的更新,并在相同的迭代中进行更新。 此外,可以实现随机梯度下降以加速计算。 在这里,我使用随机梯度下降法来解决这个回归问题。 我的预测的MSE如下所示。
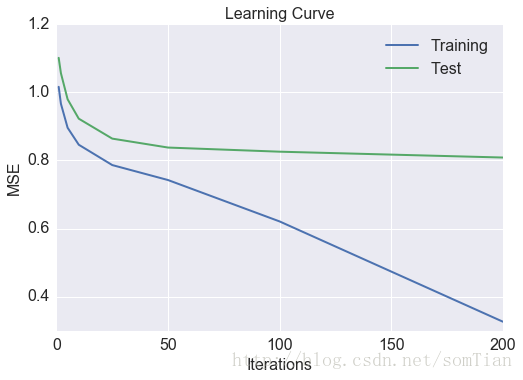
MSE比使用相似矩阵获得的小得多。 当然,我们也可以使用网格搜索和交叉验证来调整我们的模型和算法的参数。
再次,我们来看看我们的建议,通过查询感兴趣的电影。

看起来效果并不好,我不知道这四部电影是通过查询热推荐给我的。 他们看起来完全不匹配Heat。 他们看起来像浪漫/戏剧电影。 如果我发现一部类似于美国电影大片电影明星的电影,我想要观看一场电视剧? 我觉得很好的MSE结果可能给我们一个非常糟糕的建议。
那么让我们来讨论基于协同过滤的推荐系统的弱点。
- 协同过滤方法通过使用数据查找类似的用户和电影,这导致流行项目比不受欢迎的项目更容易被推荐。
- 由于没有与这些电影相关的许多使用数据,协作过滤很难为用户推荐任何新电影。
在接下来的讨论中,我们将考虑采用不同的方法来解决协同过滤问题。 我们用深度的学习向用户推荐电影。
Deep Learning
我们将在Keras中使用VGG16训练我们的神经网络。 我们的数据集中没有目标,我们只考虑第四到最后一层作为特征向量。 我们使用此特征向量来表征我们的数据集中的每个电影。 在训练我们的神经网络之前,有一些预处理步骤。训练过程总结如下。
df_id = pd.read_csv('links.csv', sep=',')
idx_to_movie = {}
for row in df_id.itertuples():
idx_to_movie[row[1]-1] = row[2]
total_movies = 9000
movies = [0]*total_movies
for i in range(len(movies)):
if i in idx_to_movie.keys() and len(str(idx_to_movie[i])) == 6:
movies[i] = (idx_to_movie[i])
movies = filter(lambda imdb: imdb != 0, movies)
total_movies = len(movies)
URL = [0]*total_movies
IMDB = [0]*total_movies
URL_IMDB = {"url":[],"imdb":[]}
i = 0
for movie in movies:
(URL[i], IMDB[i]) = get_poster(movie, base_url)
if URL[i] != base_url+"":
URL_IMDB["url"].append(URL[i])
URL_IMDB["imdb"].append(IMDB[i])
i += 1
# URL = filter(lambda url: url != base_url+"", URL)
df = pd.DataFrame(data=URL_IMDB)
total_movies = len(df)
import urllib
poster_path = "/Users/wannjiun/Desktop/nycdsa/project_5_recommender/posters/"
for i in range(total_movies):
urllib.urlretrieve(df.url[i], poster_path + str(i) + ".jpg")
from keras.applications import VGG16
from keras.applications.vgg16 import preprocess_input
from keras.preprocessing import image as kimage
image = [0]*total_movies
x = [0]*total_movies
for i in range(total_movies):
image[i] = kimage.load_img(poster_path + str(i) + ".jpg", target_size=(224, 224))
x[i] = kimage.img_to_array(image[i])
x[i] = np.expand_dims(x[i], axis=0)
x[i] = preprocess_input(x[i])
model = VGG16(include_top=False, weights='imagenet')
prediction = [0]*total_movies
matrix_res = np.zeros([total_movies,25088])
for i in range(total_movies):
prediction[i] = model.predict(x[i]).ravel()
matrix_res[i,:] = prediction[i]
similarity_deep = matrix_res.dot(matrix_res.T)
norms = np.array([np.sqrt(np.diagonal(similarity_deep))])
similarity_deep = similarity_deep / norms / norms.T 在代码中,我们首先从TMDB网站使用IMDB id的API获取电影海报,然后我们向VGG16提供海报并训练我们的神经网络,最后,我们使用VGG16学习的功能计算余弦相似度。 在我们得到电影相似性之后,我们可以推荐类似的电影,使用最高的相似度。 请注意,VGG16学习的总共有25088个特征,我们使用这些特征来表示我们的数据集中的每个电影。
让我们看看使用深度学习的推荐。

对Heat的推荐没有爱情戏剧!这些海报肯定有一些共同的特点。 他们是深蓝色,有人在海报等。再次,让我们试一下Toy Story。

Forrest Gump没有被推荐! 结果看起来不错! 我非常喜欢这样做,所以让我们再来一些例子。

请注意,这些海报中有一到两个人,非常冷的主题或风格。

这些海报想让观众知道相应的电影是有趣的,响亮的,密集的,并且在他们中有很多的动作,所以海报的颜色和图像是非常强大的。

另一方面,这些海报想要向观众展示相应的电影是关于一个人的。

我们发现一些类似于功夫熊猫的电影。

这是一个非常有趣的一个。 我们确实发现了类似的怪物,也发现了Tom Cruse!

所有这些海报都有一个类似姿势的女人。 等待! 是Shaq!?

我们成功地找到了蜘蛛侠!

这一个发现了类似排版的海报。
Conclusions
在推荐系统中有几种使用深度学习的方法:
- 无监督的学习方法。
- 预测协同过滤产生的潜在特征。
- 使用深度学习产生的功能作为辅助信息。
电影海报有元素,引起观众兴趣和兴趣。在这个项目中,我们使用深度学习作为一种无监督的学习方法,并通过处理电影海报来学习电影的相似性。显然,这只是在推荐系统中使用深度学习的第一步。有很多事情我们可以尝试。例如,我们可以使用深度学习来预测协同过滤所产生的潜在特征。 Spotify已经对类似的方法进行了音乐推荐。而不是图像处理,他们考虑使用深度学习来预测通过处理一首歌曲的声音从协同过滤得到的潜在特征。另一个可能的方法是使用深入学习的特征作为辅助信息来提高预测精度。
References:
– http://blog.ethanrosenthal.com/2015/11/02/intro-to-collaborative-filtering/
– http://blog.ethanrosenthal.com/2016/01/09/explicit-matrix-factorization-sgd-als/
– http://blog.ethanrosenthal.com/2016/10/19/implicit-mf-part-1/
– http://blog.ethanrosenthal.com/2016/11/07/implicit-mf-part-2/
– http://blog.ethanrosenthal.com/2016/12/05/recasketch-keras/
– https://www.designmantic.com/blog/2016-movie-poster-design-trends/
– https://www.designmantic.com/blog/movie-moods-in-typography/
– http://www.datasciencecentral.com/profiles/blogs/understanding-and-selecting-recommenders-1
– http://www.datasciencecentral.com/profiles/blogs/5-types-of-recommenders
– http://benanne.github.io/2014/08/05/spotify-cnns.html
– Andrew Ng, “Machine Learning,” Recommender Systems, 2016
– Aaron van den Oord, et al., “Deep content-based music recommendation,” NIPS, 2013
– Yifan Hu, et al., “Collaborative Filtering for Implicit Feedback Datasets,”
– Ste en Rendle, “BPR: Bayesian Personalized Ranking from Implicit Feedback,”















 484
484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









