







//编码和解码一致就不会造成乱码,浏览器默认的是当前系统的默认字符编码,因此解码的时候会查gbk
一.字节输出流乱码解决
1.字节输出流getOutputStream().write();
package com.itheima;
import java.io.IOException;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
//编码和解码一致就不会造成乱码,浏览器默认的是当前系统的默认字符编码,因此解码的时候会查gbk
public class Demo6Servlet extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
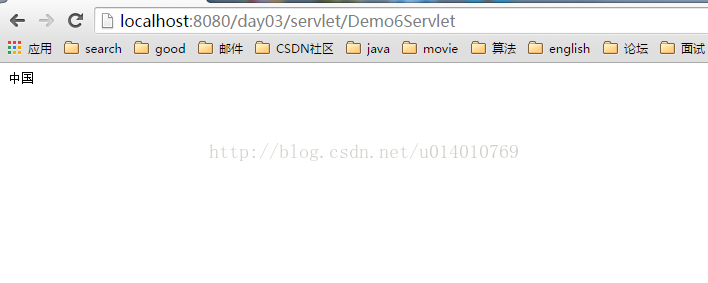
response.getOutputStream().write("中国".getBytes());//查看String类的getBytes方法可以看到使用的是当前系统默认的编码进行解码即当前是gbk
}
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
doGet(request, response);
}
}
不会乱码,因为getBytes编码的时候会查gbk,浏览器解码的时候会使用gbk.因此不会乱码!
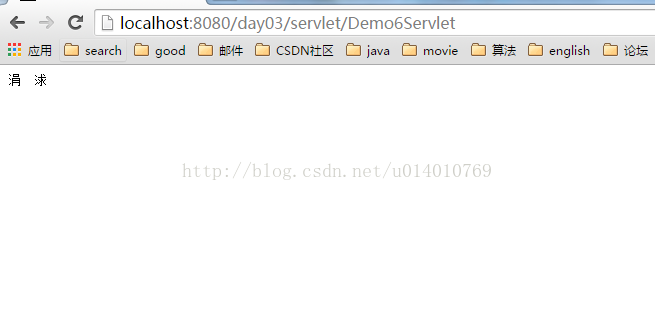
2.如果指定编码
response.getOutputStream().write("中国".getBytes("utf-8"))必定会乱码,因为编码使用的是utf-8,浏览器解码的时候使用默认的gbk因此会乱码
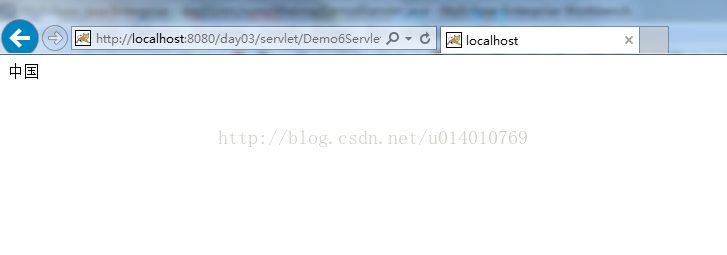
解决方式:
告知浏览器使用utf-8编码进行解码:
使用//通知浏览器使用utf-8解码
response.setHeader("Content-Type", "text/html;charset=utf-8");















 7766
7766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









