







HBase 概述
HBase是Hadoop的生态系统,是建立在Hadoop文件系统(HDFS)之上的分布式、面向列的数据库,通过利用Hadoop的文件系统提供容错能力。如果你需要进行实时读写或者随机访问大规模的数据集的时候,请考虑使用HBase!
HBase作为Google Bigtable的开源实现,Google Bigtable利用GFS作为其文件存储系统类似,则HBase利用Hadoop HDFS作为其文件存储系统;Google通过运行MapReduce来处理Bigtable中的海量数据,同样,HBase利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
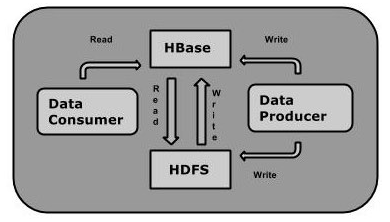
HBase处理数据
虽然Hadoop是一个高容错、高延时的分布式文件系统和高并发的批处理系统,但是它不适用于提供实时计算;HBase是可以提供实时计算的分布式数据库,数据被保存在HDFS分布式文件系统上,由HDFS保证期高容错性,但是再生产环境中,HBase是如何基于hadoop提供实时性呢? HBase上的数据是以StoreFile(HFile)二进制流的形式存储在HDFS上block块儿中;但是HDFS并不知道的HBase用于存储什么,它只把存储文件认为是二进制文件,也就是说,HBase的存储数据对于HDFS文件系统是透明的。
HBase与HDFS
在下面的表格中,我们对HDFS与HBase进行比较:
| HDFS | HBase |
|---|---|
| HDFS适于存储大容量文件的分布式文件系统。 | HBase是建立在HDFS之上的数据库。 |
| HDFS不支持快速单独记录查找。 | HBase提供在较大的表快速查找 |
| HDFS提供了高延迟批量处理;没有批处理概念。 | HBase提供了数十亿条记录低延迟访问单个行记录(随机存取)。 |
| HDFS提供的数据只能顺序访问。 | HBase内部使用哈希表和提供随机接入,并且其存储索引,可将在HDFS文件中的数据进行快速查找。 |
HBase 数据模型
HBase通过表格的模式存储数据,每个表格由列和行组成,其中,每个列又被划分为若干个列族(row family),请参考下面的图:
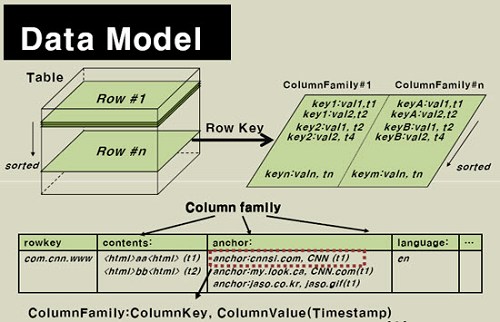
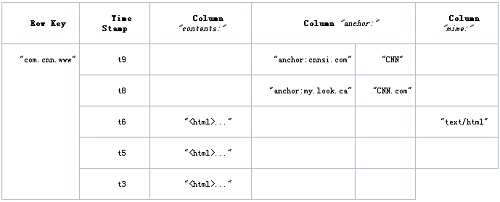
现在我们来看看HBase的逻辑数据模型与物理数据模型(实际存储的数据模型):
逻辑数据模型:
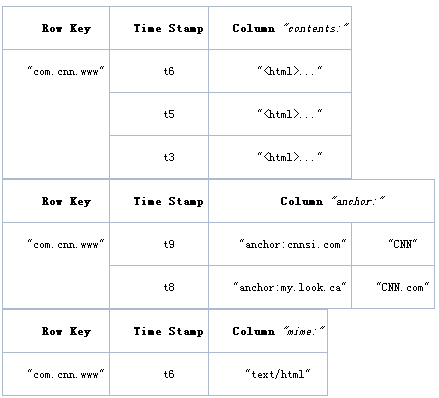
物理数据模型:
HBase 架构
下图显示了HBase的组成结构:
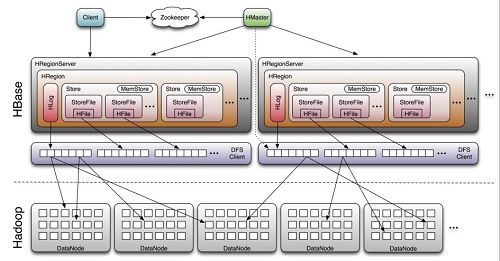
通过上图我们可以得出Hbase中的每张表都按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过 256M 就要被分割成两个,由 HRegionServer管理,管理哪些HRegion由HMaster分配。
现在我们来介绍一下HBase中的一些组成部件以及它们起到的作用:
-
Client:包含访问HBase的接口,并维护cache来加快对HBase的访问。
-
Zookeeper:HBase依赖Zookeeper,默认情况下HBase管理Zookeeper实例(启动或关闭Zookeeper),Master与RegionServers启动时会向Zookeeper注册。Zookeeper的作用如下:
- 保证任何时候,集群中只有一个master
- 存储所有Region的寻址入口
- 实时监控Region server的上线和下线信息。并实时通知给master
- 存储HBase的schema和table元数据
-
HRegionServer:用来维护master分配给他的region,处理对这些region的io请求;负责切分正在运行过程中变的过大的region。
-
HRegion:HBase表在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。Region按大小分隔,每个表一般是只有一个region,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
-
Store:每一个Region由一个或多个Store组成,至少是一个Store,HBase会把一起访问的数据放在一个Store里面,即为每个ColumnFamily建一个Store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者多个StoreFile组成。Store的大小被HBase用来判断是否需要切分Region。
-
StoreFile:memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
-
HLog:HLog记录数据的所有变更,可以用来恢复文件,一旦region server 宕机,就可以从log中进行恢复。
-
LogFlusher:一个LogFlusher的类是用来调用HLog.optionalSync()的。
-
HRegionServer:用来维护master分配给他的region,处理对这些region的io请求;负责切分正在运行过程中变的过大的region。
-
HRegion:HBase表在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。Region按大小分隔,每个表一般是只有一个region,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
-
Store:每一个Region由一个或多个Store组成,至少是一个Store,HBase会把一起访问的数据放在一个Store里面,即为每个ColumnFamily建一个Store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者多个StoreFile组成。Store的大小被HBase用来判断是否需要切分Region。
-
StoreFile:memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
-
HLog:HLog记录数据的所有变更,可以用来恢复文件,一旦region server 宕机,就可以从log中进行恢复。
-
LogFlusher:一个LogFlusher的类是用来调用HLog.optionalSync()的。
HBase 的应用
- HBase是用来当有需要写重的应用程序。
- HBase可以帮助快速随机访问数据。
- HBase被许多公司所采纳,例如,Facebook、Twitter、Yahoo!、Adobe、OpenPlaces、WorldLingo等等。
Hbase查询速度快的原理分析
HBase能提供实时计算服务主要原因是由其架构和底层的数据结构决定的,即由LSM-Tree(Log-Structured Merge-Tree) + HTable(region分区) + Cache决定——客户端可以直接定位到要查数据所在的HRegion server服务器,然后直接在服务器的一个region上查找要匹配的数据,并且这些数据部分是经过cache缓存的。
前面说过HBase会将数据保存到内存中,在内存中的数据是有序的,如果内存空间满了,会刷写到HFile中,而在HFile中保存的内容也是有序的。当数据写入HFile后,内存中的数据会被丢弃。
HFile文件为磁盘顺序读取做了优化,按页存储。下图展示了在内存中多个块存储并归并到磁盘的过程,合并写入会产生新的结果块,最终多个块被合并为更大块。

多次刷写后会产生很多小文件,后台线程会合并小文件组成大文件,这样磁盘查找会限制在少数几个数据存储文件中。HBase的写入速度快是因为它其实并不是真的立即写入文件中,而是先写入内存,随后异步刷入HFile。所以在客户端看来,写入速度很快。另外,写入时候将随机写入转换成顺序写,数据写入速度也很稳定。
而读取速度快是因为它使用了LSM树型结构,而不是B或B+树。磁盘的顺序读取速度很快,但是相比而言,寻找磁道的速度就要慢很多。HBase的存储结构导致它需要磁盘寻道时间在可预测范围内,并且读取与所要查询的rowkey连续的任意数量的记录都不会引发额外的寻道开销。比如有5个存储文件,那么最多需要5次磁盘寻道就可以。而关系型数据库,即使有索引,也无法确定磁盘寻道次数。而且,HBase读取首先会在缓存(BlockCache)中查找,它采用了LRU(最近最少使用算法),如果缓存中没找到,会从内存中的MemStore中查找,只有这两个地方都找不到时,才会加载HFile中的内容,而上文也提到了读取HFile速度也会很快,因为节省了寻道开销。
举例:
A:如果快速查询(从磁盘读数据),hbase是根据rowkey查询的,只要能快速的定位rowkey, 就能实现快速的查询,主要是以下因素:
1、hbase是可划分成多个region,你可以简单的理解为关系型数据库的多个分区。
2、键是排好序了的
3、按列存储的
首先,能快速找到行所在的region(分区),假设表有10亿条记录,占空间1TB, 分列成了500个region, 1个region占2个G. 最多读取2G的记录,就能找到对应记录;
其次,是按列存储的,其实是列族,假设分为3个列族,每个列族就是666M, 如果要查询的东西在其中1个列族上,1个列族包含1个或者多个HStoreFile,假设一个HStoreFile是128M, 该列族包含5个HStoreFile在磁盘上. 剩下的在内存中。
再次,是排好序了的,你要的记录有可能在最前面,也有可能在最后面,假设在中间,我们只需遍历2.5个HStoreFile共300M
最后,每个HStoreFile(HFile的封装),是以键值对(key-value)方式存储,只要遍历一个个数据块中的key的位置,并判断符合条件可以了。 一般key是有限的长度,假设跟value是1:19(忽略HFile上其它块),最终只需要15M就可获取的对应的记录,按照磁盘的访问100M/S,只需0.15秒。 加上块缓存机制(LRU原则),会取得更高的效率。
B:实时查询
实时查询,可以认为是从内存中查询,一般响应时间在1秒内。HBase的机制是数据先写入到内存中,当数据量达到一定的量(如128M),再写入磁盘中, 在内存中,是不进行数据的更新或合并操作的,只增加数据,这使得用户的写操作只要进入内存中就可以立即返回,保证了HBase I/O的高性能。
实时查询,即反应根据当前时间的数据,可以认为这些数据始终是在内存的,保证了数据的实时响应。
https://www.w3cschool.cn/hbase_doc/hbase_doc-vxnl2k1n.html
















 2742
2742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











