







目录
在 leetCode 中,「岛屿问题」是一个系列系列问题。
我们首先明确一下岛屿问题中的网格结构是如何定义的,以方便我们后面的讨论。
网格问题是由 m \times nm×n 个小方格组成一个网格,每个小方格与其上下左右四个方格认为是相邻的,要在这样的网格上进行某种搜索。
岛屿问题是一类典型的网格问题。每个格子中的数字可能是 0 或者 1。我们把数字为 0 的格子看成海洋格子,数字为 1 的格子看成陆地格子,这样相邻的陆地格子就连接成一个岛屿。

以 leetcode 200 题为例 https://leetcode-cn.com/problems/number-of-islands/
此类问题一般有三种方法:深度优先搜索(DFS)、广度优先搜索(BFS)和并查集(DSU)。
1. 深度优先搜索(DFS)
1.1 模板
void dfs(int[][] grid, int r, int c) {
// 判断 base case
// 如果坐标 (r, c) 超出了网格范围,直接返回
if (!inArea(grid, r, c)) {
return;
}
// 访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int r, int c) {
return 0 <= r && r < grid.length
&& 0 <= c && c < grid[0].length;
}1.2 避免重复
是标记已经遍历过的格子。以岛屿问题为例,我们需要在所有值为 1 的陆地格子上做 DFS 遍历。每走过一个陆地格子,就把格子的值改为 2,这样当我们遇到 2 的时候,就知道这是遍历过的格子了。也就是说,每个格子可能取三个值:
0 —— 海洋格子
1 —— 陆地格子(未遍历过)
2 —— 陆地格子(已遍历过)
void dfs(int[][] grid, int r, int c) {
// 判断 base case
if (!inArea(grid, r, c)) {
return;
}
// 如果这个格子不是岛屿,直接返回
if (grid[r][c] != 1) {
return;
}
grid[r][c] = 2; // 将格子标记为「已遍历过」
// 访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int r, int c) {
return 0 <= r && r < grid.length
&& 0 <= c && c < grid[0].length;
}
1.3 图解
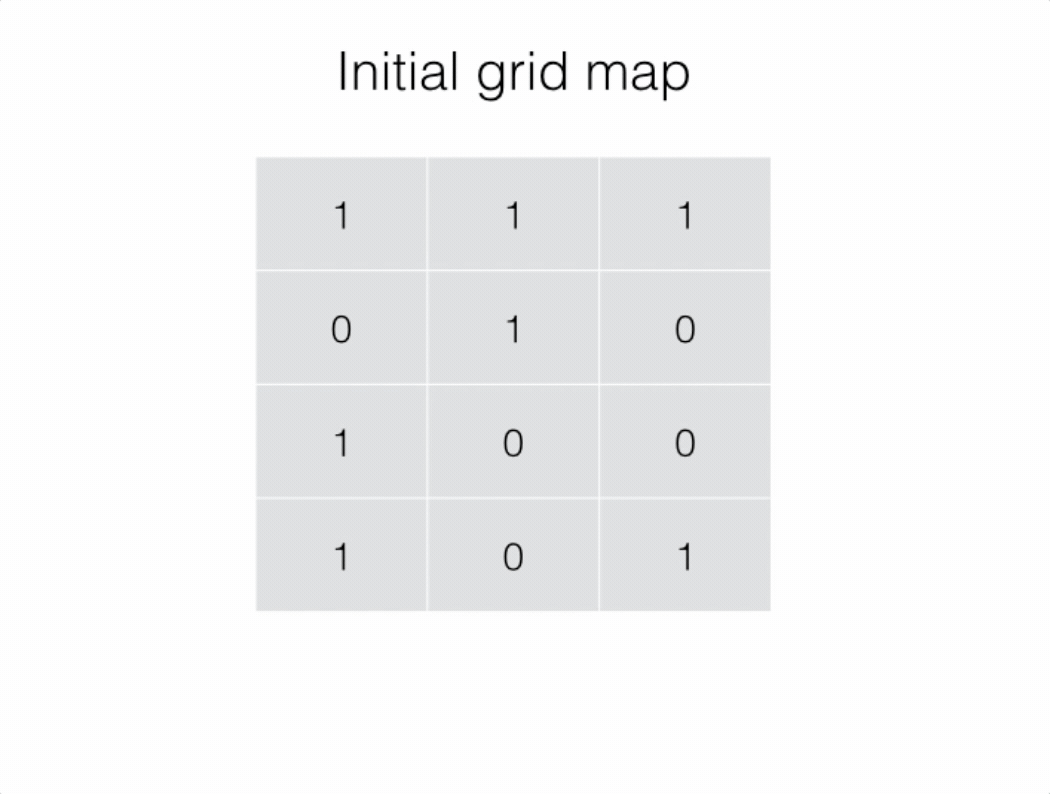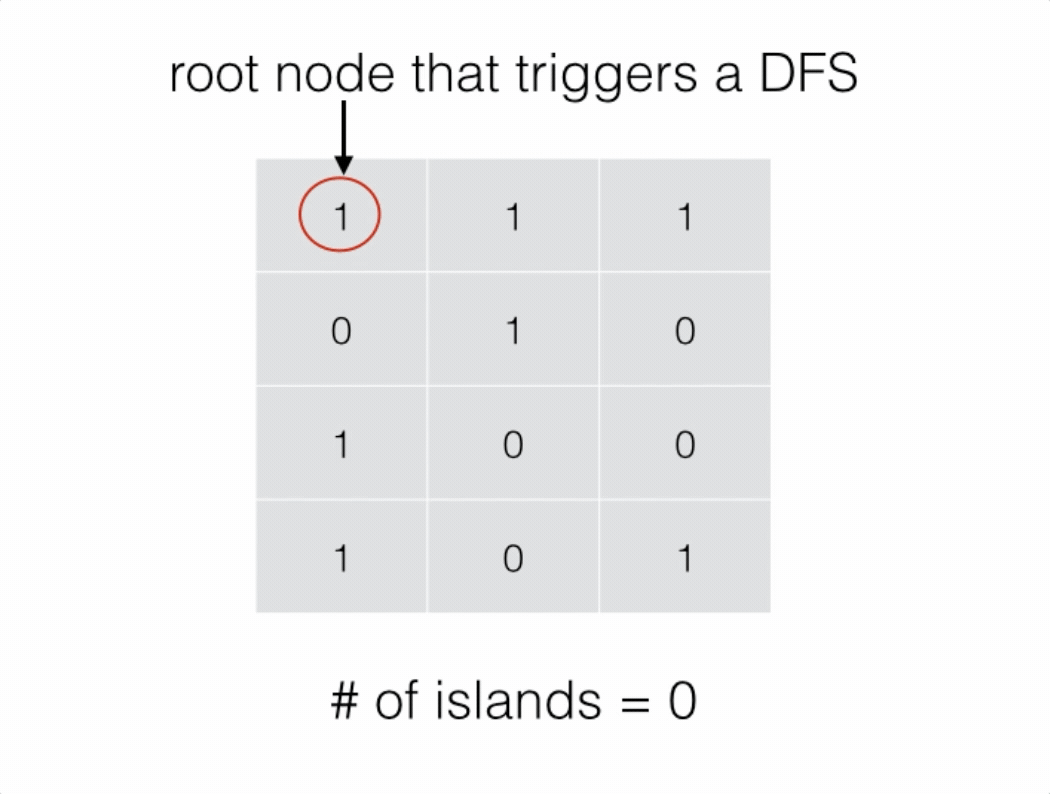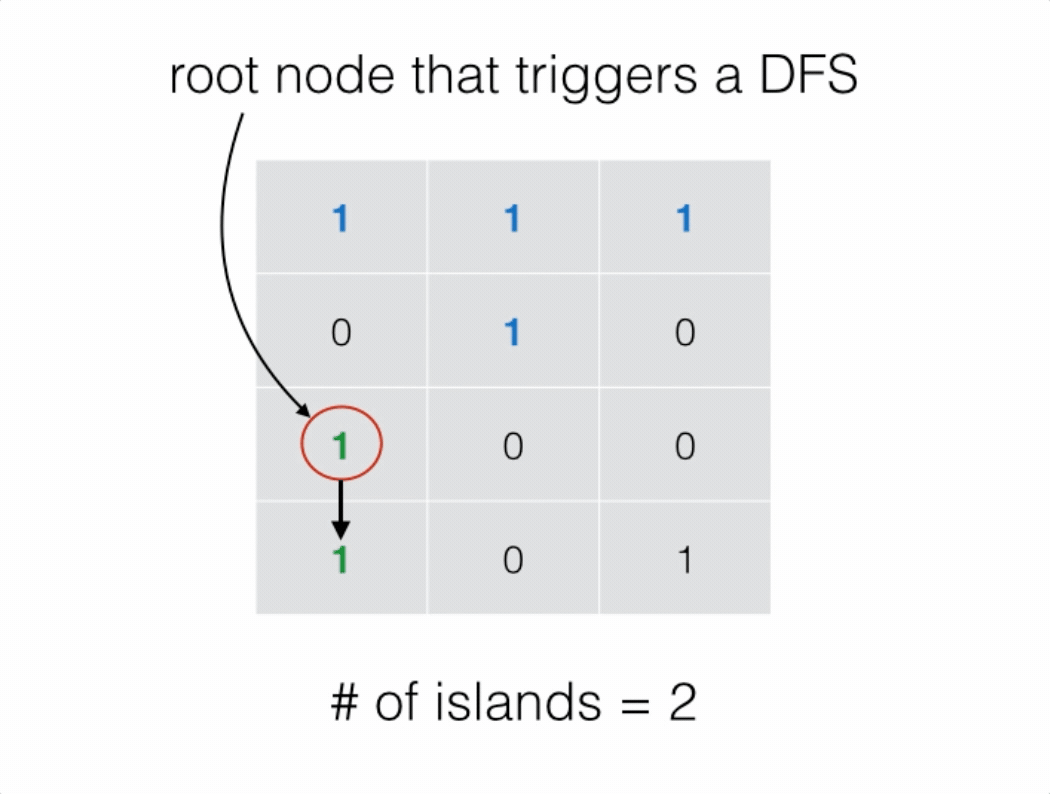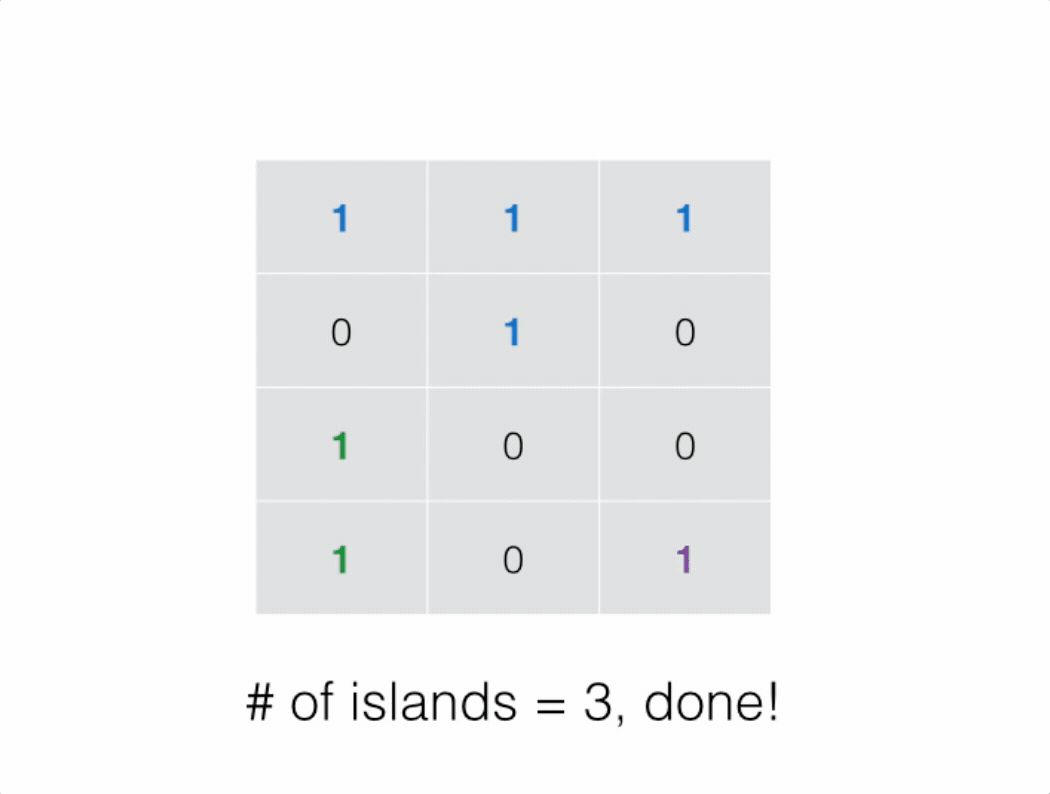
我们可以将二维网格看成一个无向图,竖直或水平相邻的 1 之间有边相连。
为了求出岛屿的数量,我们可以扫描整个二维网格。如果一个位置为 1,则以其为起始节点开始进行深度优先搜索。在深度优先搜索的过程中,每个搜索到的 1 都会被标记为 2。
最终岛屿的数量就是我们进行深度优先搜索的次数。
1.4 实现
public int numIslands1(char[][] grid) {
// 判断 base case
if(grid == null || grid.length == 0) return 0;
int ri = grid.length;
int rj = grid[0].length;
int num = 0;
for(int i = 0; i < ri; i++) {
for(int j = 0; j < rj; j++) {
if(grid[i][j] == '1') {
num++;
dfs(grid, i, j);
}
}
}
return num;
}
void dfs(char[][] grid, int r, int c) {
// 判断 base case
if(!inArea(grid, r, c)) {
return;
}
// 如果这个格子不是岛屿,直接返回
if(grid[r][c] != 1) {
return;
}
grid[r][c] = 2; // 将格子标记为「已遍历过」
// 访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(char[][] grid, int r, int c) {
return 0 <= r && r < grid.length && 0 <= c && c < grid[0].length;
}2. 广度优先搜索(BFS)
思想同DFS,只不过广度优先遍历需要队列帮助实现。
2.1 实现
public int numIslands2(char[][] grid) {
if(grid == null || grid.length == 0) return 0;
int ri = grid.length;
int rj = grid[0].length;
int num = 0;
for(int i = 0; i < ri; i++) {
for(int j = 0; j < rj; j++) {
if(grid[i][j] == '1') {
num++;
bfs(grid, i, j);
}
}
}
return num;
}
private void bfs(char[][] grid, int r, int c) {
Queue < int[] > queue = new LinkedList < > (); // 存放x,y的坐标
queue.offer(new int[] {
r, c
});
while(!queue.isEmpty()) {
int[] poll = queue.poll();
r = poll[0]; // x坐标
c = poll[1]; // y坐标
// 判断 base case
if(!inArea(grid, r, c)) {
continue;
}
// 如果这个格子不是岛屿,直接continue,开始下次循环
if(grid[r][c] != 1) {
continue;
}
grid[r][c] = 2; // 将格子标记为「已遍历过」
queue.offer(new int[] {
r - 1, c
});
queue.offer(new int[] {
r + 1, c
});
queue.offer(new int[] {
r, c - 1
});
queue.offer(new int[] {
r, c + 1
});
}
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(char[][] grid, int r, int c) {
return 0 <= r && r < grid.length && 0 <= c && c < grid[0].length;
}3. 并查集(DSU)
关于连通性问题,并查集也是常用的数据结构。
并查集是一种数据结构, 常用于描述集合,经常用于解决此类问题:某个元素是否属于某个集合,或者 某个元素 和 另一个元素是否同属于一个集合。
一般需要三个步骤,用三个函数分别表示:
- QuickUnion()初始化数组
- union()合并(组队)
- find() 查找所属集合
3.1 思路

并查集中维护连通分量的个数,在遍历的过程中:
- 相邻的陆地(只需要向右看和向下看)合并,只要发生过合并,岛屿的数量就减少 11;
- 在遍历的过程中,同时记录空地的数量;
- 并查集中连通分量的个数 - 空地的个数,就是岛屿数量。
3.1.1 图解
简单说就是,创建一个数组,该数组里存的数字代表所属的集合。
比如arr[4]==1;代表4是第一组。如果arr[7]==1,代表7也是第一组。既然 arr[4] == arr[7] == 1 ,那么说明4 和 7同属于一个集合。
1、初始化所属集合数组
先初始化一个数组。初始时数组内的值与数组的下角标一致。即每个数字都自成立一个小组。
0属于第0个小组(集合),1属于第1个小组(集合),2属于第2个小组(集合)..........

将这个例子的并查集用树形表示来,如下图所示:

2、合并集合
接下来让几个数字进行合并操作,就是组队的过程(合并集合)。
让 5和6进行组队。5里的值就变为6了。含义就是:5放弃了第5小组,加入到了第6小组。5和6属于第6小组。

接下来 让1 和2 进行组队。1的下角标就变为2了。含义就是:1和2都属于第2小组。

接下来让 2 3进行组队:2想和3进行组队,2就带着原先的所有队友,加入到了3所在的队伍。看下面arr[1] == arr[2]==arr[3]==3,意思就是1 2 3 都属于第3小组。

接下来 1 和 4 进行组队:1就带着原先所有的队友一起加入到4所在的队伍中了。看下面arr[1] == arr[2]==arr[3]==arr[4]==4,意思就是1 2 3 4都属于第4小组。

接下来1 和 5进行组队:1就带着原先所有的队友一起加入到5所在的队伍中。5在哪个队伍呢? 因为arr[5]==6,所以5在第6小组。1就带着所有队友进入了小组6。
看下面arr[1] == arr[2]==arr[3]==arr[4]==arr[5]==arr[6]==6,意思就是1 2 3 4 5 6都属于第6小组。

用树形表示来,如下图所示:

最后就看所属集合数组中有多少个不同的值,即为所求。
3.1.2 初始化数组 QuickUnion()
public class QuickUnion {
private int[] parents;
private int count = 0;
QuickUnion(char[][] grid) {
int x = grid.length;
int y = grid[0].length;
parents = new int[x * y];
for(int i = 0; i < x; i++) {
for(int j = 0; j < y; j++) {
if(grid[i][j] == '1') {
// 初始化指向自己
parents[i * y + j] = i * y + j;
count++;
}
}
}
}
}3.1.3 查找所属集合 find()
也就是说求出某个元素所属的集合
public int find(int element) {
while(parents[element] != element) {
element = parents[element];
}
return element;
}这样的实现方法效率有点慢,直接进行优化。
并查集优化:路径压缩
路径压缩就是处理并查集中的深的结点。实现方法很简单,就是在find函数里加上一句 parent[element] = parent[parent[element]];就好了,就是让当前结点指向自己父亲的父亲,减少深度,同时还没有改变根结点的weight。
public int find(int element) {
while(parents[element] != element) {
parents[element] = parents[parents[element]];
element = parents[element];
}
return element;
}3.1.4 合并 union()
public void union(int x, int y) {
int xRoot = find(x);
int yRoot = find(y);
if(xRoot == yRoot) return;
parents[xRoot] = yRoot;
count--;
}3.2 实现
public int numIslands3(char[][] grid) {
if(grid == null || grid.length == 0) return 0;
int x = grid.length;
int y = grid[0].length;
QuickUnion union = new QuickUnion(grid);
for(int i = 0; i < x; i++) {
for(int j = 0; j < y; j++) {
if(grid[i][j] == '1') {
// 下侧
if(i + 1 < x && grid[i + 1][j] == '1')
union.union(i * y + j, (i + 1) * y + j);
// 右侧
if(j + 1 < y && grid[i][j + 1] == '1')
union.union(i * y + j, i * y + j + 1);
}
}
}
return union.count;
}
public class QuickUnion {
private int[] parents;
private int count = 0;
QuickUnion(char[][] grid) {
int x = grid.length;
int y = grid[0].length;
parents = new int[x * y];
for(int i = 0; i < x; i++) {
for(int j = 0; j < y; j++) {
if(grid[i][j] == '1') {
// 初始化指向自己
parents[i * y + j] = i * y + j;
count++;
}
}
}
}
public void union(int x, int y) {
int xRoot = find(x);
int yRoot = find(y);
if(xRoot == yRoot) return;
parents[xRoot] = yRoot;
count--;
}
public int find(int element) {
while(parents[element] != element) {
parents[element] = parents[parents[element]];
element = parents[element];
}
return element;
}
}















 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









