






1.同一进程下的线程可以共享的是
A stack
B data section
C register set
D thread ID
选B
线程共享的内容包括:
进程代码段
进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)、
进程打开的文件描述符、
信号的处理器、
进程的当前目录
进程用户ID与进程组ID
线程独有的内容包括:
线程ID
寄存器组的值
线程的堆栈
错误返回码
线程的信号屏蔽码
2.\n与\r的ASCII值分别是多少
回车,ASCII码13
换行,ASCII码10
进程间的通信机制
管道
消息队列
共享内存
套接字
可用作c语言的用户标识符
可用于标识符的有数字,字母,下划线,其中不能以数字开头,再去掉系统的一些关键字,其余都可以作为用户自定义的标识符。
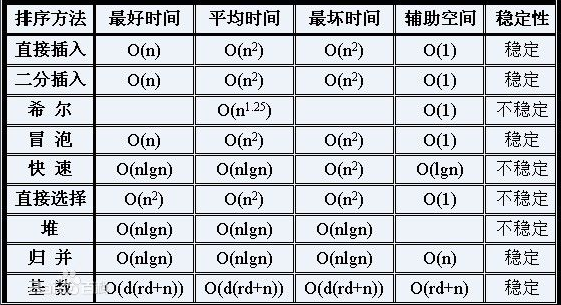
各类排序的方法及原理总结
1.希尔排序
希尔排序属于插入类排序,是将整个有序序列分割成若干小的子序列分别进行插入排序。
排序过程:先取一个正整数d1小于n,把所有序号相隔d1的数组元素放一组,组内进行直接插入排序;然后取d2小于d1,重复上述分组和排序操作;直至di=1,即所有记录放进一个组中排序为止。
2.稳定性
由于多次插入排序,我们知道一次插入排序是稳定的,不会改变相同元素的相对顺序,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,最后其稳定性就会被打乱,所以shell排序是不稳定的。
3.插入排序
插入排序法,插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为O(n^2)。是稳定的排序方法。
4.快速排序
快速排序(Quicksort)是对冒泡排序的一种改进。
通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
设要排序的数组是A[0]……A[N-1],首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一趟快速排序。
5.归并排序
归并操作(merge),也叫归并算法,指的是将两个顺序序列合并成一个顺序序列的方法。
如 设有数列{6,202,100,301,38,8,1}
初始状态:6,202,100,301,38,8,1
第一次归并后:{6,202},{100,301},{8,38},{1},比较次数:3;
第二次归并后:{6,100,202,301},{1,8,38},比较次数:4;
第三次归并后:{1,6,8,38,100,202,301},比较次数:4;
总的比较次数为:3+4+4=11,;
逆序数为14;
归并排序是稳定的排序
6.堆排序
堆排序是不稳定排序
7.选择排序
选择排序是给每个位置选择当前元素最小的,比如给第一个位置选择最小的,在剩余元素里面给第二个元素选择第二小的,依次类推,直到第n-1个元素,第n个元素不用选择了,因为只剩下它一个最大的元素了。
时间复杂度
const与define的区别
1.const常量有数据类型,而宏常量没有数据类型,编译器可对前者进行类型安全检查,对后者只进行字符替换,没有类型安全检查,并且在字符替换可能产生意想不到的错误
2.调试工具可以对const常量进行调试,不能对宏常量进行调试
关于sizeof与strlen
1.sizeof计算栈中分配的大小,sizeof是运算符,而strlen是函数
2.sizeof的参数可以是内置类型,如sizeof(int),而strlen只能用char*做参数,且必须以“\0”结尾
内联函数与宏的区别
1.内敛函数与普通函数相比可加快程序运行速度,因为不需要中断调用,而宏只是一个简单的替换
2.内联函数要做参数类型检查,而宏是不做参数类型检查的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









