







、目录
1.Logistic 回归定义
Logistic 回归是一个用于二分分类的算法。
公式定义如下:
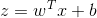
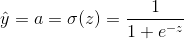
2.Logistic 回归的损失函数:
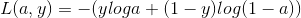
3.梯度下降法
(1) 通过梯度下降法训练模型参数
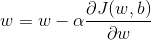
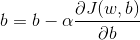
其中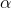
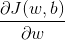
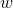
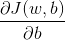
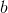
(2) 根据公式(3)可算得:
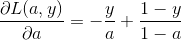
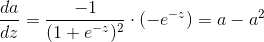
根据链式法则
"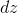
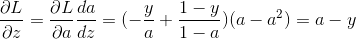
“
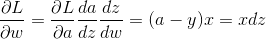
"
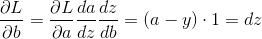
更新:
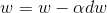
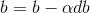
(3) 梯度下降法
(a)对于m个训练样本的情况
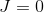
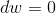
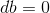
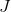
For i = 1 to m
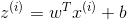
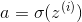
![J += -[y^{(i)}loga^{(i)} + (1-y^{(i)})log(1-a^{(i)})]](https://img-blog.csdnimg.cn/20181218110335331)
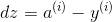
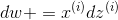
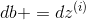
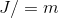
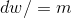
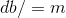
(b)完成以上所有的计算后更新参数:
(a)(b)过程循环执行。相当于Logistic 回归包含两个大循环(num_iterations表示迭代次数)
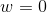
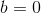
For i = 1 to num_iterations
For i = 1 to m
4.代码实现
(1)准备工作
编写sigmoid函数
import numpy as np
def sigmoid(z):
return 1.0 / (1 + np.exp(-z))(2) 初始化
def initialize_with_zeros(dim):
w = np.zeros((dim, 1))
b = 0
assert(w.shape == (dim, 1))
assert(isinstance(b, float) or isinstance(b, int)) #变量类型是否正确
return w, b(3)计算m个样本的损失函数和梯度
矢量化技术它可以使码摆脱这些显式的for循环
def propagate(w, b, X, Y):
"""
w -- 权值, 大小为(n_x, 1)的numpy数组
b -- 偏置
X -- 大小为(n_x, m) m为训练样本的个数
Y -- 标签
Return:
cost -- negative log-likelihood cost for logistic regression
dw -- gradient of the loss with respect to w, thus same shape as w
db -- gradient of the loss with respect to b, thus same shape as b
"""
m = X.shape[1]
# FORWARD PROPAGATION (FROM X TO COST)
A = sigmoid(np.dot(w.T, X)+b)
cost = -(1.0/m)*np.sum(Y*np.log(A)+(1-Y)*np.log(1-A))
# BACKWARD PROPAGATION (TO FIND GRAD)
dw = (1.0/m)*np.dot(X,(A-Y).T)
db = (1.0/m)*np.sum(A-Y)
assert(dw.shape == w.shape)
assert(db.dtype == float)
cost = np.squeeze(cost) #把shape中为1的维度去掉
assert(cost.shape == ())
grads = {"dw": dw,
"db": db}
return grads, cost
(4)使用梯度下降更新参数
目标是通过最小化成本函数J来学习w和b。
def optimize(w, b, X, Y, num_iterations, learning_rate, print_cost = False):
"""
此函数通过运行梯度下降算法来优化w和b
参数:
w - 权重,一个大小为(n_x, 1)的数组
b - 偏置,标量
X - 大小为(n_x, m)的数组
Y - 标签
num_iterations - 优化循环的迭代次数
learning_rate - 梯度下降更新规则的学习率
print_cost - 为每100步打印一次损失
返回:
params - 包含权重w和偏置b的字典
grads - 包含权重梯度和相对于损失函数的偏置的字典
损失 - 优化期间计算的所有损失的列表,这将用于绘制学习曲线。
"""
costs = []
for i in range(num_iterations):
grads, cost = propagate(w, b, X, Y)
dw = grads["dw"]
db = grads["db"]
w = w - learning_rate*dw
b = b - learning_rate*db
# 记录损失
if i % 100 == 0:
costs.append(cost)
if print_cost and i % 100 == 0:
print ("Cost after iteration %i: %f" %(i, cost))
params = {"w": w,
"b": b}
grads = {"dw": dw,
"db": db}
return params, grads, costs
(5)预测类别
def predict(w, b, X):
'''
使用学习到的w和b来预测数据集X的标签。
参数:
w - 权重
b - 偏置
返回:
Y_prediction - 包含X中示例的所有预测(0/1)的numpy数组(向量)
'''
m = X.shape[1]
Y_prediction = np.zeros((1,m))
w = w.reshape(X.shape[0], 1)
A = sigmoid(np.dot(w.T, X) + b)
for i in range(A.shape[1]):
if A[0,i] > 0.5:
Y_prediction[0,i] = 1
else:
Y_prediction[0,i] = 0
assert(Y_prediction.shape == (1, m))
return Y_prediction
for i in range(A.shape[1]):
if A[0,i] > 0.5:
Y_prediction[0,i] = 1
else:
Y_prediction[0,i] = 0也可以简写为
A[A >= 0.5] = 1
A[A < 0.5] = 0 (6)总结
Logistic Regression的步骤
- 初始化(w,b)
- 迭代优化损失以学习参数(w,b)
- 计算损失及其梯度
- 使用梯度下降更新参数
- 使用学习到的(w,b)预测给定示例集的标签
将所有函数整合到一起
def model(X_train, Y_train, X_test, Y_test, num_iterations = 2000, learning_rate = 0.5, print_cost = False):
"""
参数:
X_train - 训练集
Y_train - 训练集标签
X_test - 测试集
Y_test - 测试集标签
num_iterations - 迭代次数
learning_rate - 学习率
print_cost - 设置为true以每100次迭代打印成本
返回:
d - 包含模型信息的字典。
"""
# 1.初始化参数
w, b = initialize_with_zeros(X_train.shape[0])
# 2.梯度下降学的模型参数 计算损失
parameters, grads, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate, print_cost)
# Retrieve parameters w and b from dictionary "parameters"
w = parameters["w"]
b = parameters["b"]
# Predict test/train set examples (≈ 2 lines of code)
Y_prediction_test = predict(w, b, X_test)
Y_prediction_train = predict(w, b, X_train)
# Print train/test Errors
print("train accuracy: {} %".format(100 - np.mean(np.abs(Y_prediction_train - Y_train)) * 100))
print("test accuracy: {} %".format(100 - np.mean(np.abs(Y_prediction_test - Y_test)) * 100))
d = {"costs": costs,
"Y_prediction_test": Y_prediction_test,
"Y_prediction_train" : Y_prediction_train,
"w" : w,
"b" : b,
"learning_rate" : learning_rate,
"num_iterations": num_iterations}
return d















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









