









翻译自:pratical rendering and computation with Direct3D 11
介绍
在Direct3D 11中 Buffer Resource提供了一维线性内存块。可以使用许多不同的配置来更改缓冲区的行为,但是它们都具有相同的基本线性布局
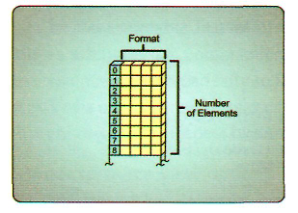
缓冲区的大小以字节为单位度量,组成缓冲区的元素可以有不同的大小,这取决于缓冲区的类型,以及每个特定缓冲区类型的特定配置。一些缓冲区类型将主要用于应用程序的c++端,而另一些缓冲区类型将主要用于HLSL着色器程序。本节将探讨每种不同类型的缓冲区,描述它们提供的功能,并演示如何创建它们。此外,我们将讨论缓冲区的常见用法,并提供基本的HLSL语法来声明和在着色器程序中使用这些资源。
Vertex Buffers
顶点缓冲区的目的是存放所有最终将组装成顶点并通过渲染管线发送的数据。最简单的顶点缓冲区配置是顶点结构数组,其中每个顶点包含位置、法向量和纹理坐标等元素。这些顶点元素必须符合可用的格式和类型规范。然而,在顶点中需要的任何通用信息也可以打包到顶点结构中,以允许为特定的渲染算法定制输入数据。
除了上面描述的简单数组样式的顶点缓冲区之外,这些缓冲区还允许其他一些更复杂的配置。例如,可以同时使用多个顶点缓冲区。这允许顶点数据分开存储在不同的缓冲区中。例如,顶点位置可以存储在一个缓冲区中,顶点法向量可以存储在另一个缓冲区中。这允许应用程序根据需要有选择地添加顶点数据,而不是为所有渲染场景使用一个大的整体缓冲区。这种技术可以用来减少渲染操作所需的带宽。
也可以执行实例渲染,其中一个或多个顶点缓冲区提供模型的每个顶点数据,另外一个顶点缓冲区提供每个实例数据,而不是每个顶点数据。通过第二个缓冲区的实例数据,将第一个缓冲区的模型数据渲染成一系列的实例模型。每个实例的数据可以包括一个世界坐标转换、颜色变化或用于区分模型的不同实例的任何其他内容。这种设置允许通过一个draw调用渲染许多对象,从而降低了渲染操作的总体CPU开销。
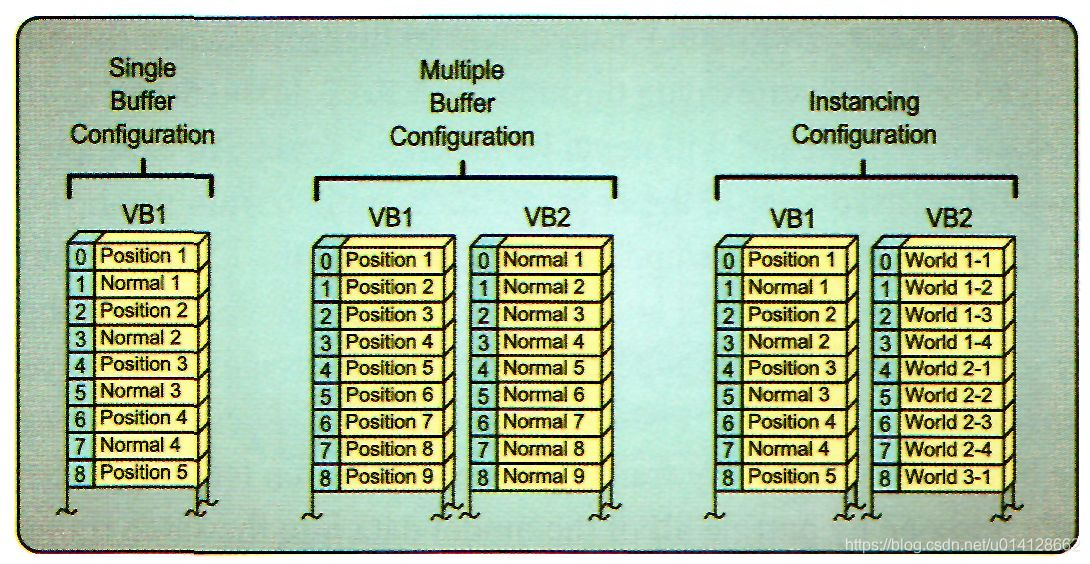
从图中可以看出,每种类型的顶点缓冲区都遵循我们的一般缓冲区布局。每个缓冲区都是由相同大小的元素组成的一维数组。单个数据元素的大小总是与同一缓冲区中的其他元素的大小相同,尽管如果使用多个缓冲区,它们可能具有不同的元素大小。
Vertex Buffer使用
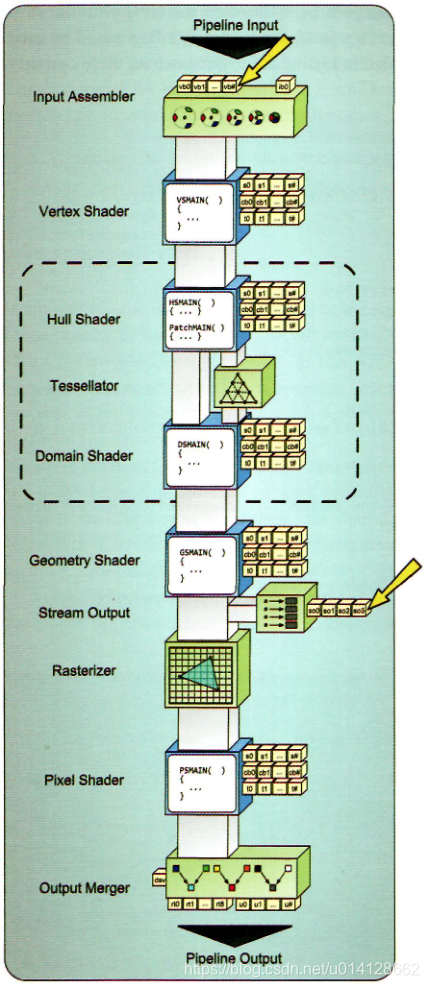
如上所述,顶点缓冲区的主要目的是为渲染管线提供每个顶点的信息,可以是直接提供,也可以是通过实例提供。为此,将顶点缓冲区绑定到管道的主要位置位于input assembler阶段,该阶段作为渲染管线的入口点。除了input assembler阶段,顶点缓冲区也可以附加到stream output阶段,以允许渲染管线将顶点数据流到缓冲区中,以便在后续的渲染 passes中使用数据。
创建Vertex Buffer
在渲染管线中可以绑定资源的位置,每种资源都必须在创建时设置相应的绑定标志,以便允许将资源绑定到那里。记住这一点,顶点缓冲区必须始终设置d3d11_bind_vertex_buffer绑定标志。如果该缓冲区还用于从渲染管线中流出顶点数据那么还可以选择性的包含D3D11_BIND_STREAM_OUTPUT绑定标志。
除了绑定标志的选择之外,顶点缓冲区的另一个主要考虑因素是缓冲区将要使用的场景。取决于顶点缓冲区的内容是否会频繁更改,以及这些更改是否来自CPU或GPU,将需要不同的使用标志。例如,如果将加载到缓冲区的数据是静态的,那么应该使用d3d11_usage_constant usage标志创建缓冲区资源。在这种情况下,当创建缓冲区时,它将通过传递给创建方法的D3D11_SUBRESURCE_DATA参数用顶点数据初始化,并且再也不会被修改。这种类型的顶点缓冲区的一个例子将用于保存静态地形网格的内容。
但是,如果CPU经常更新缓冲区,则应该使用D3D11_USAGE_DYNAMIC创建缓冲区,并为CPU访问标志参数使用CPU写标志。这种类型的顶点缓冲区使用的一个例子是,当顶点转换在CPU上而不是GPU上执行时。然后,这些更新将被复制到每个帧的缓冲区资源中。这是一种常用的技术,通过将所有模型数据放入同一参照系(通常是world space或view space),将许多draw调用压缩为一个调用。第三种使用类型是创建一个缓冲区,该缓冲区将由GPU使用流输出功能进行更新。在本例中,将使用D3D11_USAGE_DEFAULT usage标志。
ID3DllBuffer* CreateVertexBuffer( UINT size,bool dynamic,bool streamout,D3D11_SUBRES0URCE_DATA* pData )
{
D3D11_BUFFER_DESC desc;
desc.ByteWidth = size;
desc.MiscFlags = 0;
desc.StructureByteStride = 0;
// Select the appropriate binding locations based on the passed in flags
if ( streamout )
desc.BindFlags = D3D11_BIND_VERTEX_BUFFER | D3D11_BIND_STREAM_0UTPUT;
else
desc.BindFlags = D3D11_BIND_VERTEX_BUFFER;
// Select the appropriate usage and CPU access flags based on the passed
// in flags
if ( dynamic )
{
desc.Usage = D3D11_USAGE_DYNAMIC;
desc.CPUAccessFlags = D3D11_CPU_ACCESS_WRITE;
}
else
{
desc.Usage = D3D11_USAGE_IMMUTABLE;
desc.CPUAccessFlags = 0;
}
// Create the buffer with the specified configuration
ID3D11Buffer* pBuffer = 0;
HRESULT hr = g_pDevice->CreateBuffer( &desc, pData, &pBuffer );
if ( FAILED( hr ) )
{
// Handle the error here...
return( 0 );
}
return( pBuffer );
}
Resource View
顶点缓冲区直接绑定到IA阶段或Stream Output阶段。因此,在使用资源视图时不需要创建资源视图。
Index Buffer
介绍
索引缓冲区提供了通过引用顶点缓冲区中存储的顶点数据来定义基本类型的非常有用的功能。索引缓冲区或多或少提供指向顶点列表的索引列表。根据所需的基元类型(如点、线和三角形),将形成适当大小的索引组,以定义该基元由哪些顶点组成。
索引缓冲区的使用可能会显著减少需要定义的顶点总数。由于每个相邻基元定义可以引用与其相邻基元相同的顶点数据,因此共享顶点不需要在顶点缓冲区中重复。此外,这种顶点共享允许多个原语使用来自顶点着色器的相同输出顶点。
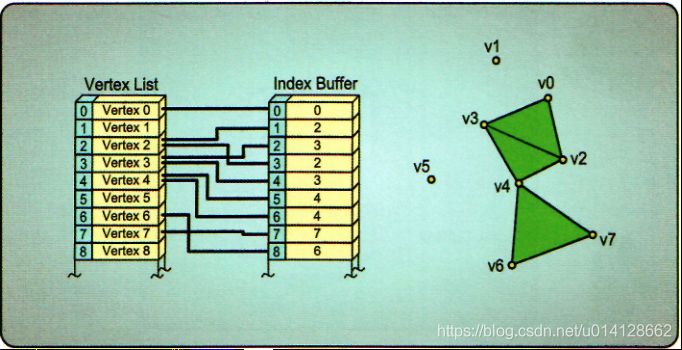
使用Index Buffer
由于索引缓冲区指定了要在基本设置操作中使用哪些顶点,所以您必须提前知道将要使用什么基本拓扑—否则您将不知道将索引放入哪个顺序。这通常是通过选择渲染算法和几何加载例程提前确定的。在准备执行draw函数的渲染管线配置过程中,所需的索引缓冲区被绑定到input assembler阶段(IA),该阶段将用于为管道生成输入图元( input primitives)。由于这些缓冲区具有非常特殊的用途,所以它们通常不绑定到其他位置的管道。这个绑定位置如图
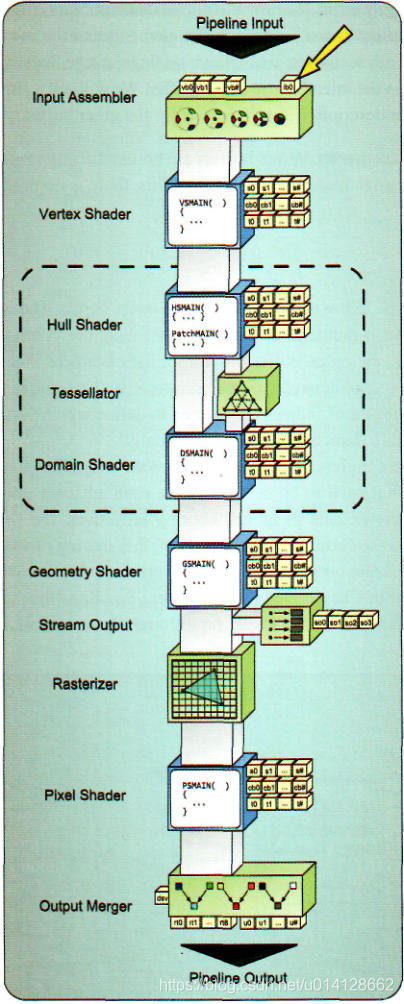
创建Index Buffer
在创建索引缓冲区时,我们遵循标准的缓冲区创建过程,并填充D3D11_BUFFER_DESC结构。索引缓冲区的描述结构不会在缓冲区之间频繁更改,因为这类数据通常在内容创建程序中定义一次,然后按原样导出。在应用程序启动阶段之后,索引缓冲区索引通常不会更改。但是,如果某些新算法确实需要动态更新索引缓冲区,也可以使用跟Vertext Buffers一样的动态更新属性来创建它。这可以在“Vertext Buffers”一节中讨论的draw call reduction方案中使用,在该方案中,将多个几何集合动态地分组到一起,形成一组顶点和索引缓冲区。
ID3DllBuffer* CreateIndexBuffer( UINT size,bool dynamic,D3D11_SUBRES0URCE_DATA* pData )
{
D3D11_BUFFER_DESC desc;
desc.ByteWidth = size;
desc.MiscFlags = 0;
desc.StructureByteStride = 0;
deSC.BindFlagS = D3D11_BIND_INDEX_BUFFER;
// Select the appropriate usage and CPU access flags based on the passed
// in flags
if ( dynamic )
{
desc.Usage = D3D11_USAGE_DYNAMIC;
desc.CPUAccessFlags = D3D11_CPU_ACCESS_WRITE;
}
else
{
desc.Usage = D3D11_USAGE_IMMUTABLE;
desc.CPUAccessFlags = 0;
}
// Create the buffer with the specified configuration
ID3DllBuffer* pBuffer = 0;
HRESULT hr = g_pDevice->CreateBuffer( &desc, pData, &pBuffer );
if ( FAILED( hr ) )
{
// Handle the error here...
return( 0 );
}
return( pBuffer );
}
要指定的第一项是缓冲区的大小(以字节为单位)。从代码清单中可以看到,索引缓冲区总是使用D3D11_BIND_INDEX_BUFFER绑定标志创建的。当需要静态索引缓冲区时,usage标志指定为D3D11_USAGE_IMMUTABLE,没有任何CPU访问标志设置。在本例中,必须使用D3D11_SUBRES0URCE_DATA结构将缓冲区的预期内容提供给创建调用。如果需要动态缓冲区,我们将选择D3D11_USAGE_DYNAMIC,以及D3D11_CPU_ACCESS_WRITE CPU访问标志。
Resource view
索引缓冲区直接绑定到IA程序阶段,不需要资源视图的帮助。因此,不需要创建资源视图来使用索引缓冲区。
Constant Buffer
介绍
Constant Buffer它可以从可编程着色器阶段访问,并随后在HLSL代码中使用。一个Constant Buffer是用来提供constant信息给可编程着色程序正在执行的管道。术语constant是指在执行draw或dispatch调用期间,Buffer中的数据始终保持常量。任何只在管道调用之间更改的信息,例如世界转换矩阵或对象颜色,都将在一个常量缓冲区中提供给着色器程序。这种机制是将数据从主机应用程序传输到每个可编程着色器阶段的主要方法。常量缓冲区中包含的信息的类型和数量可能因缓冲区而异。这完全取决于每个特定着色器程序所需的数据,由着色器程序中的结构声明定义。缓冲区可以或多或少地针对基本HLSL类型的任何组合以及由这些基本类型组成的结构进行定制。这些类型包括标量、向量、矩阵、这些类型的数组、类实例以及结构中每种类型的组合。如图描述了这一类型的单一组合:
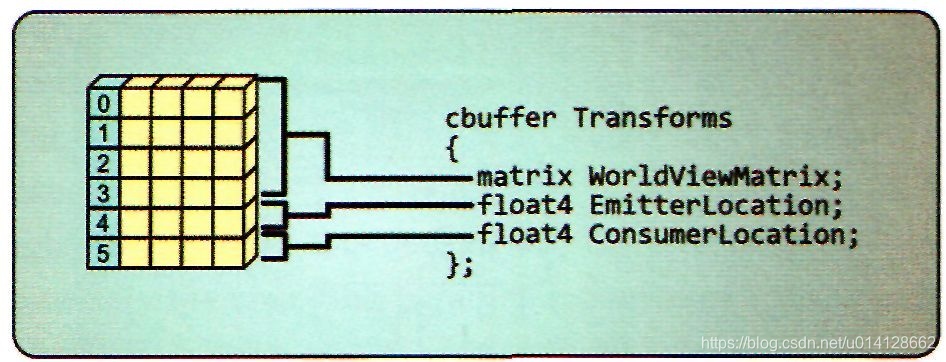
顶点缓冲区和索引缓冲区都定义一个基本的数据元素,然后以类似数组的方式多次重复该元素。而常量缓冲区不一样,常量缓冲区定义了一个基本元素,但它没有提供元素的一个以上实例。创建缓冲区时,缓冲区的大小足以容纳所需的信息,但不是更大。这意味着常量缓冲区实现的是结构而不是数组。
使用常量缓冲区
每个可编程管道阶段都可以接受一个或多个常量缓冲区。然后,它使缓冲区中的信息可以在着色器程序中使用。访问数据时就像在着色器程序中全局声明结构内容一样。这意味着每个结构的元素必须在这个伪全局范围内具有唯一的名称。这种能力为向特定渲染算法所需的着色器程序添加变化提供了很大的灵活性。需要注意的是,为将缓冲区绑定为常量缓冲区而创建的缓冲区可能不会绑定到管道上的任何其他类型的连接点。实际上,这不是一个问题,因为一个常量缓冲区的内容已经可以用于所有可编程的管道阶段。如图所示突出显示了用于绑定常量缓冲区的管道上的位置。
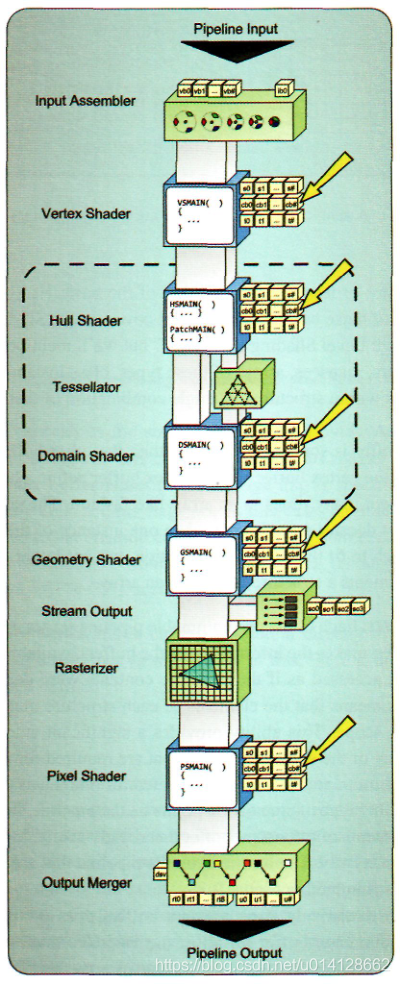
能够使用相对较大的常量缓冲区并不意味着您应该为着色器程序中所需的所有变量自动创建一个较大的缓冲区。由于CPU在每次使用之间都会更新常量缓冲区,所以在进行任何更改之后,必须将它们的内容上传到GPU。让我们假设一个情况。假设着色器程序需要十个参数,但是在每次渲染对象之间,只有两个参数会发生变化。在本例中,我们将在每次draw调用之间将所有10个参数写入缓冲区,只是为了更新两个不同的参数,因为整个缓冲区总是完全更新的。根据要渲染的对象的数量,这些额外的参数更新可能会造成大量不必要的带宽浪费。如果我们创建两个常量缓冲区,其中一个保存八个静态参数,另一个保存两个动态参数,那么我们只能更新不断变化的参数,并显著减少每个帧所需的数据更新量。但是,我们需要确保缓冲区只在真正需要时才更新!
更新常量缓冲区的另一个潜在的缺点是,这些缓冲区只支持从着色器程序读取访问。因为它是只读的,所以可以同时将一个常量缓冲区绑定到管道中的多个位置,而不可能导致内存访问冲突。
创建Constant Buffer
常量缓冲区还提供了许多不同的资源配置,以获得最佳的性能。根据CPU更新常量缓冲区的频率,选择两种典型配置。如果在应用程序的生命周期中多次更新常量缓冲区,则动态缓冲区资源最有意义。当然,如果一个常量缓冲区将包含一些不会在整个应用程序中更改的数据(例如固定的后台缓冲区(back buffer)大小),那么将它创建为一个完全静态的缓冲区会更有效,使用不可变的使用标志。
ID3DllBuffer* CreateConstantBuffer( UINT size,bool dynamic,bool CPUupdates,
D3D11_SUBRES0URCE_DATA* pData )
{
D3D11_BUFFER_DESC desc;
desc.ByteWidth = size;
desc.HiscFlags = 0;
desc.StructureByteStride = 0;
desc.BindFlags = D3Dll_BIND_C0NSTANT_BUFFERj
// Select the appropriate usage and CPU access flags based on the passed
// in flags
if ( dynamic && CPUupdates )
{
desc.Usage = D3D11_USAGE_DYNAMIC;
desc.CPUAccessFlags = D3D11_CPU_ACCESS_WRITE;
}
else if ( dynamic && !CPUupdates )
{
desc.Usage = D3D11_USAGE_DEFAULT;
desc.CPUAccessFlags = 0;
}
else
{
desc.Usage = D3D11_USAGE_IMMUTABLE;
desc.CPUAccessFlags = 0;
}
// Create the buffer with the specified configuration
ID3D11Buffer* pBuffer = 0;
HRESULT hr = g_pDevice->CreateBuffer( &desc, pData, &pBuffer );
if ( FAILED( hr ) )
{
// Handle the error here...
return( 0 );
}
return( pBuffer );
}
与顶点缓冲区和索引缓冲区一样,动态常量缓冲区的创建使用D3D11_USAGE_DYNAMIC usage标志,并结合D3D11_CPU_ACCESS_WRITE标志,以允许CPU在运行时更新资源。对于静态内容,使用D3D11_ USAGE_IMMUTABLE usage且不使用任何CPU访问标志。另一种情况是,只有GPU在运行时才更新缓冲区,比如当使用ID3D11 DeviceContext:: copystructu()方法将Append/Consume缓冲区中的元素数量复制到常量缓冲区时。在本例中,我们需要一个默认的usage标志,但是我们不设置任何CPU访问标志。这允许在GPU上使用时优化创建的资源。几个需要注意的地方:第一,应用程序通常定义一个c++结构,该结构反映HLSL中常量缓冲区的所需内容。这允许将应用程序更新应用于此结构的系统内存实例,然后可以将该实例直接复制到缓冲区中。第二,必须使用字节宽度(ByteWidth是16字节的倍数)创建常量缓冲区。这一要求允许使用GPU的4元组寄存器类型高效地处理缓冲区,并且它只作为常量缓冲区的要求出现。这必须在C/ c++的结构声明中说明。第三,缓冲区描述不允许包含除D3D11_BIND_C0NSTAI\IT_BUFFER之外的任何其他绑定标志。并不是一个很大的限制,因为通常不需要将常量缓冲区绑定到管道中的另一个位置。
Resource view
尽管常量缓冲区绑定到可编程着色器阶段,并且可以通过HLSL访问,但是它们的内容不会以任何方式用资源视图解释。它们被精确地指定为应该在HLSL中可用,因此不需要使用资源视图。
HLSL常量缓冲资源对象
在HLSL中,常量缓冲区是用cbuffer关键字声明的资源对象。
cbuffer Transforms
{
matrix WorldMatrixj
matrix ViewProjMatrix;
matrix SkinMatrices[26];
};
cbuffer LightParameters
{
float3 LightPositionWS;
float4 LightColor;
};
cbuffer ParticlelnsertParameters
{
float4 EmitterLocation;
float4 RandomVector;
};
在这个cbuffer结构中声明的每个变量都可以在HLSL着色器程序中直接使用,就像在全局范围中声明一样。主机应用程序使用常量缓冲区的名称来按名称标识缓冲区,并将适当的内容加载到缓冲区中。但是,在HLSL中不使用缓冲区名。与常量缓冲区名称一样,常量缓冲区的各个元素的名称和类型也可以通过着色器反射API访问。这一系列方法可用于确定每个子参数的名称和类型,从而允许应用程序知道在运行时将哪些信息插入缓冲区。
Buffer/Structured Buffer
介绍
接下来的资源有两个名称,这取决于它包含的数据类型。standard buffer resource是指其元素是内置数据类型之一的缓冲区。通过这种方式,标准缓冲区资源类似于值数组。每个值都存储在一个惟一的数组位置,并且可以由其位置的索引引用。这使得GPU上着色器程序的许多不同实例可以同时轻松地访问资源。由于每个元素都是唯一标识的,开发人员可以轻松地构造程序以避免任何内存冲突。
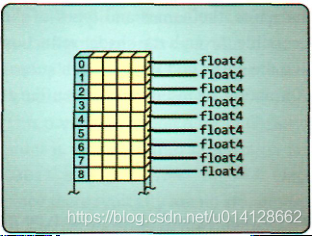
与缓冲区资源非常相似的是结构化缓冲区资源。两者之间的唯一区别是,结构化缓冲区允许用户将结构定义为基本元素,而不是内置的数据类型之一。这使得将特定处理问题的数据映射到资源相对简单。如果开发人员可以在c++中定义一个合适的结构,那么可以在HLSL中定义一个相应的结构,并且缓冲区将包含这些结构的数组,这些结构可以被可编程着色器阶段用作资源对象。
结构化缓冲区旨在为简化自定义算法开发提供灵活的内存资源。由于结构中的数据格式可以使用HLSL中的任何可用类型,因此可以定制它来适应特定的场景。可用的结构形式与常量缓冲区非常相似,只是结构化缓冲区提供了所需结构的数组,而不是常量缓冲区这样的单个实例。
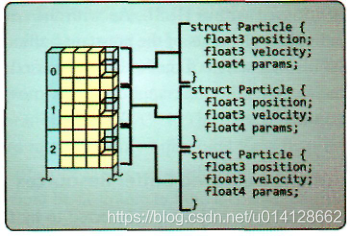
这里我们看到粒子结构使用多个变量,完整的粒子系统包含在结构化缓冲区中。这类缓冲区可以用于可编程管道阶段的编写和读取。
使用buffers/structured buffers
由于能够提供大量的结构化数据,对于可编程着色器阶段要访问的较大数据结构,缓冲区和结构化缓冲区是很好的选择。这些缓冲区是附加到管道的第一个资源,带有资源视图,而不是直接绑定。这些缓冲区可用于对所有可编程管道阶段的读访问,根据使用的资源视图,还可以在像素和计算着色器阶段进行读/写访问。这意味着这些资源可能提供了不同管道阶段之间以及同一管道阶段内的各个处理元素之间通信的方法。
管道阶段的资源访问功能由用于将资源绑定到管道的资源视图类型决定。与常量缓冲区不同,缓冲区/结构化缓冲区必须通过资源视图绑定到管道,这意味着必须使用适当的绑定标志创建它,以便与着色器资源视图、无序访问视图或两者都绑定。着色器资源视图允许绑定到所有可编程管道阶段,而无序访问视图只允许绑定到像素和计算着色器阶段。由于执行对资源的写访问需要无序访问视图,因此UAV的可用绑定位置可以有效地确定这些写访问可以在哪里执行。着色器资源视图和无序访问视图的可用连接点如图所示。与常量缓冲区一样,当用于只读用途时,缓冲区/结构化缓冲区可以绑定到多个位置。这是通过使用着色器资源视图将其绑定到管道来实现的。然而,当使用无序访问视图时,它可能只绑定到一个位置。这是由运行时强制执行的,如果将资源绑定到多个位置进行写入,运行时将打印错误消息。无序访问视图的使用还排除了同时使用着色器资源视图,因为它可能会带来read-after-write的问题。
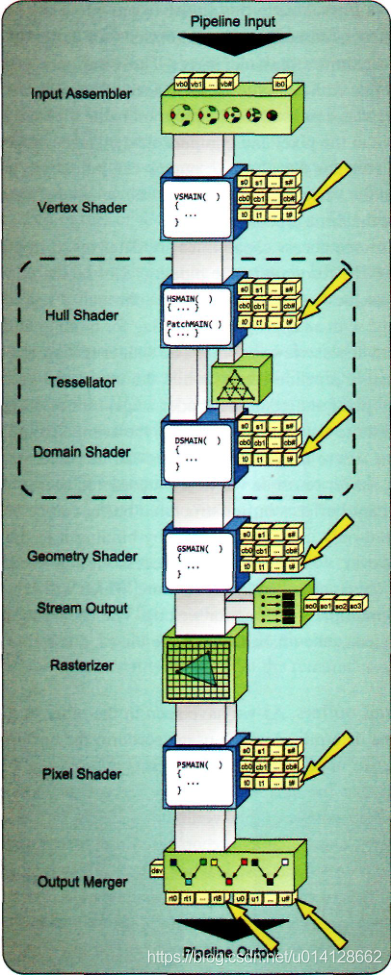
创建buffers/structured buffers
正如我们在其他缓冲区资源创建讨论中看到的,必须确定缓冲区/结构化缓冲区将经历哪种使用场景。这些资源通常有三种不同类型的使用模式。第一种情况是缓冲区中的数据在应用程序的整个生命周期内都是静态的。例如,使用缓冲区/结构化缓冲区资源来保存预计算的数据,例如预计算 radiance transfer data或其他形式的查找表。第二种情况是CPU需要周期性地将数据加载到缓冲区中。在许多通用计算系统中,这是一种可能的场景,其中GPU被用作CPU的协处理器,并不断向GPU提供要处理的新数据。在这两种情况下,GPU只允许读取缓冲区数据,而不能写入资源。
最后一种情况是,当缓存内容以某种方式由GPU本身更新时。一个常见的例子是,GPU正在执行某种类型的物理模拟,稍后将用于渲染模拟结果的表示。在这种情况下,GPU将需要对缓冲区进行读写访问,以便读取内容、执行一些更新,然后将结果写回缓冲区。这三个场景中的每一个都需要不同的设置,用于创建缓冲区时使用的使用、CPU访问和绑定标志。
除了这些标志之外,我们还必须在使用结构化缓冲区时提供一些额外的大小信息。所有类型的缓冲区都要求指定ByteWidth参数,该参数以字节为单位指示缓冲区的期望大小。结构化缓冲区还要求我们指定正在使用的结构元素的大小。当资源被可编程管道阶段之一访问时,此信息用作步骤大小。使用结构化缓冲区的另一个要求是表明缓冲区资源确实将用作结构化缓冲区。这是通过设置D3D11_RESOURCE_MISC_BUFFER_STRUCTURED杂项标志实现的。
ID3DllBuffer* CreateStructuredBuffer( UINT count, UINT structsize, bool CPUWritable, bool GPUWritable, D3D11_SUBRES0URCE_DATA* pData )
{
D3D11_BUFFER_DESC desc;
desc.ByteWidth = count * structsize;
desc.MiscFlagS = D3D11_RES0URCE_MISC_BUFFER_STRUCTURED;
desc.StructureByteStride = structsize;
// Select the appropriate usage and CPU access flags based on the passed in flags
if ( !CPUWritable && IGPUWritable )
{
desc.BindFlagS = D3D11_BIND_SHADER_RES0URCE;
desc.Usage = D3D11_USAGE_IMMUTABLE;
desc.CPUAccessFlags = 0;
}
else if ( CPUWritable && IGPUWritable )
{
desc.BindFlagS = D3D11_BIND_SHADER_RES0URCE;
desc.Usage = D3D11_USAGE_DYNAMIC;
desc.CPUAccessFlags = D3D11_CPU_ACCESS_WRITE;
}
else if ( ICPUWritable && GPUWritable )
{
desc.BindFlagS = D3D11_BIND_SHADER_RES0URCE |
D3D11_BIND_UN0RDERED_ACCESS;
desc.Usage = D3D11_USAGE_DEFAULT;
desc.CPUAccessFlags = 0;
}
else if ( CPUWritable && GPUWritable )
{
// Handle the error here...
// Resources can't be writable by both CPU and GPU simultaneously!
}
// Create the buffer with the specified configuration
ID3DllBuffer* pBuffer = 0;
HRESULT hr = g_pDevice->CreateBuffer( &desc, pData, &pBuffer );
if ( FAILED( hr ) )
{
// Handle the error here...
return( 0 );
}
return( pBuffer );
}
我们将大小信息分割为要包含在缓冲区中的结构数量的计数,并使用structsize参数以字节表示每个结构的大小。然后,这些参数用于计算缓冲区的总字节宽度。此外,上面讨论的三个使用场景中的每一个都在代码清单中表示;它们通过CPU访问、使用和绑定标志将它们区分开来。
Resource view
惟一可以与缓冲区或结构化缓冲区一起使用的资源视图是着色器资源视图和无序访问视图。实际上,这是将这些缓冲区绑定到管道的唯一方法。对于标准缓冲区类型,必须在SRV描述结构中直接提供格式。对于结构化缓冲区资源,应该将格式设置为DXGI_F0RMAT_UNKNOWN,因为没有一种DXGI格式可以匹配所有可能的结构类型。格式是从着色器程序中的HLSL结构声明派生出来的,元素的大小由应用程序在创建缓冲区资源时提供。
缓冲区资源的着色器资源视图描述结构要求指定开始元素和视图中包含的元素数量。这可以选择缓冲区中的整个元素范围,也可以用来选择总资源的子集。当从HLSL查看时,这有效地将选择的数据映射到[0,width-1]范围,而所有其他访问都被认为超出界限的。这些值在D3D11_BUFFER_SRV结构中指定。
ID3DllShaderResourceView* CreateBufferSRV( ID3DllResource* pResource )
{
D3D11_SHADER_RES0URCE_VIEW_DESC desc;
// For structured buffers, DXGI_FORMAT_UNKNOWN must be used!
// For standard buffers, utilize the appropriate format,
desc.Format = DXGI_FORMAT_R32G32B32_FLOAT;
desc.ViewDimension = D3D11_SRV_DIMENSI0N_BUFFER;
desc.Buffer.ElementOffset = 0;
desc.Buffer.ElementWidth = 100;
ID3DllShaderResourceView* pView = 0;
HRESULT hr = g_pDevice->CreateShaderResourceView( pResource, &desc,&pView );
return( pView );
}
通过调整ElementOffset和ElementWidth参数,可以使用一个大型缓冲区资源来包含一组较小的数据集,每个数据集都有自己的SRV,以提供对它们的访问。通过使用着色器资源视图来限制对资源的特定子集的访问,并创建适当数量的着色器资源视图,应用程序可以通过使用特定的着色器资源视图有效地控制哪些数据对每次调用着色器程序都可见。也可以使用多个视图同时选择缓冲区的不同范围。
无序访问视图使用相同的元素范围选择和格式规范,还提供了一组额外的标志,可以为特殊使用场景指定这些标志。这些标志允许无序访问视图用于 append/consume缓冲区和字节地址缓冲区,这两者都是通过无序访问视图使用缓冲区资源的特殊方式。下面演示了如何创建无序访问视图。
ID3D11UnorderedAccessView* CreateBufferUAV( ID3DllResource* pResource )
{
D3D11_UN0RDERED_ACCESS_VIEW_DESC desc;
// For structured buffers, DXGI_FORMAT_UNKNOWN must be used!
// For standard buffers, utilize the appropriate format,
desc.Format = DXGI_FORMAT_R32G32B32_FLOAT;
desc.ViewDimension = D3D11_UAV_DIMENSI0N_BUFFER;
desc.Buffer.FirstElement = 0;
desc.Buffer.NumElements = 100;
desc.Buffer.Flags = D3D11_BUFFER_UAV_FLAG_C0UNTER;
//desc.Buffer.Flags = D3D11_BUFFER_UAV_FLAG_APPEND;
//desc.Buffer.Flags = D3D11_BUFFER_UAV_FLAG_RAW;
ID3DllUnorderedAccessView* pView = 0;
HRESULT hr = g_pDevice->CreateUnorderedAccessView( pResource, &desc,&pView );
return( pView );
}
清单显示了D3D11_BUFFER_UAV_FLAG_C0UNTER标志的设置,并注释掉了附加标志和原始标志。此标志用于为可通过HLSL访问的缓冲区资源提供计数器。这个计数器是通过使用HLSL缓冲资源对象的方法来操作的。
HLSL structured buffer resource
结构化缓冲区要求在着色器程序中定义相应的结构。一旦有了合适的结构,就使用类似模板的语法声明结构化缓冲区。
// Declare the structure that represents one fluid column's state
struct GridPoint
{
float Height;
float4 Flow;
};
// Declare the input and output resources
RWStructuredBuffer<GridPoint> NewWaterState : register( u0 );
StructuredBuffer<GridPoint> CurrentWaterState : register( t0 );
在这个代码清单中,我们看到实际上有两种不同的方法来声明结构化缓冲区:StructuredBuffer<>和RWStructuredBuffero。这两种形式分别代表了绑定到管道的结构化缓冲区(使用着色器资源视图(用于只读访问)和无序访问视图(用于读写访问)之间的差异。寄存器语句也指出了这一点,读写资源使用u#寄存器,只读资源使用t#寄存器。声明类型的选择将决定应用程序必须使用哪种类型的资源视图来将资源绑定到可编程着色器阶段,以便在此着色器程序中使用。
一旦对象被声明,我们可以看到有一种简单的方法可以在HLSL中与结构化缓冲区交互。使用类似数组的语法访问各个元素,使用方括号指示要使用哪个索引。这与c++的操作非常相似,可以使用点操作符访问结构的各个成员。当资源与着色器资源视图绑定时,只能读取元素。但是,使用无序访问视图,也可以使用相同的语法将它们写入。当使用resource视图选择缓冲区资源的一个子集时,它的元素似乎会被重新映射,这样子范围中的第一个元素就会被索引0访问,随后的每个元素都会被索引递增的索引访问。
这些HLSL资源对象还提供GetDimensions()方法,该方法返回缓冲区的大小,或者缓冲区的大小和结构化缓冲区的结构元素大小。这些可以被着色器程序用来实现范围检查。如果UAV使用D3D11_BUFFER_UAV_FLAG_C0UNTER标志创建,也可以使用内置在RWStructuredBuffer中的计数器变量。如果使用这个标志集创建UAV, HLSL程序可以使用IncrementCounter()和DecrementCounter()方法。通过提供存储在结构化缓冲区中的元素的总数,可以使用这些元素实现定制的数据结构。使用此功能需要将UAV格式设置为DXGI_FORMAT_R32_UNKNOWN。














 5521
5521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









