






以下是对Pandas document其中的10 Minutes to pandas的简单翻译
具体原文见:http://pandas.pydata.org/pandas-docs/version/0.18.0/10min.html
===========================分割线================================
好,我们开始
这是一篇关于pandas的简要介绍,主要是为新手准备的。在Cookbook中有关于pandas
较为复杂的例子,链接如下:
http://pandas.pydata.org/pandas-docs/version/0.18.0/cookbook.html#cookbook
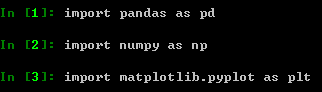
首先在库的导入中,习惯性约定如下:
1、对象创建
请看数据结构部分:http://pandas.pydata.org/pandas-docs/version/0.18.0/dsintro.html#dsintro
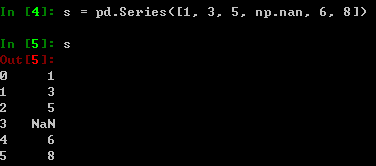
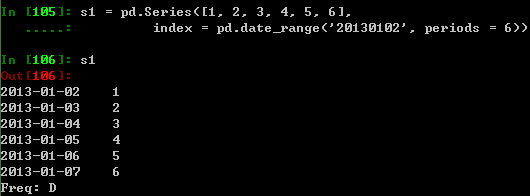
创建一个Series:由一系列值组成,索引为默认整型
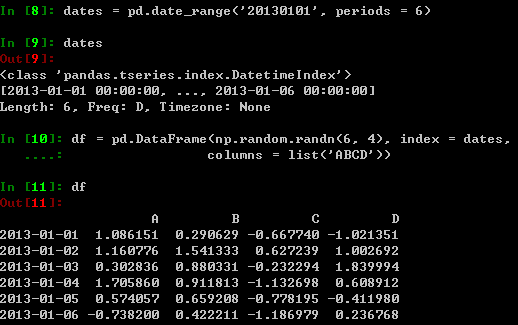
创建一个DataFrame:由一个numpy数组组成,日期作为索引,且有列标签
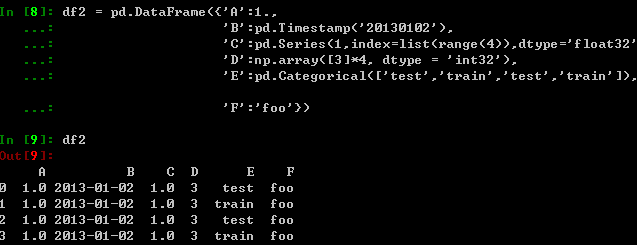
创建一个DataFrame:通过字典形式创建,并且可以转换成类似Series的形式:
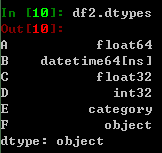
其特定的数据类型:
如果您正在使用IPython,那么Tab键就具有较强的索引功能,它会将当前对象可能的属性都罗列出来。下面您看到的
就是其一部分属性(实际上很多)。
2、审视数据
可以参见Basics section
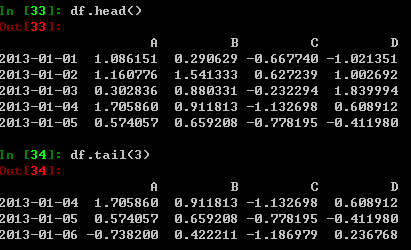
查看frame的首行及尾行内容:
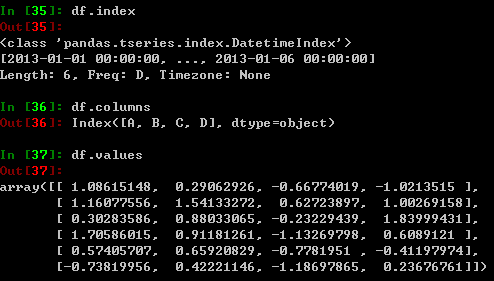
显示索引值,列以及相关的numpy数据
describe方法:展示数据统计的相关结果,非常便捷
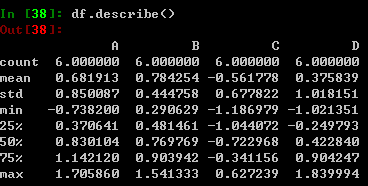
对数据形式进行转置:
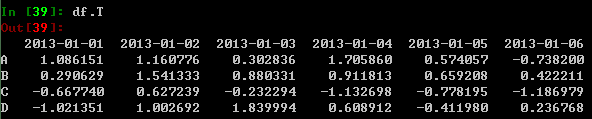
根据某一轴进行排序:
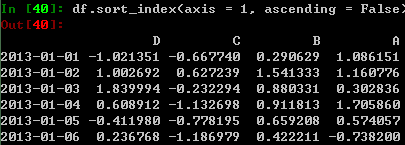
根据数值进行排序:
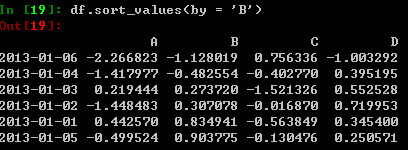
3、选取
注意:尽管标准的Python/Numpy表达式在数据的选取及设置方面较为直观,并且在交互式工作及
代码生成方面也很便利。但我们还是推荐最优化的pandas数据存取方法,如.at, .iat, .loc, .iloc和.ix。
具体可参见索引文档:Indexing and Selecting Data和MultiIndex/Anvanced Indexing.
获取
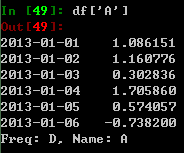
选取单列,即相当于产生一个Series;这等价于df.A
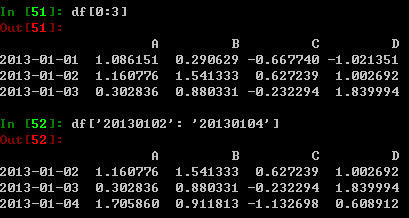
通过[]选取数据,相当于对行切片处理
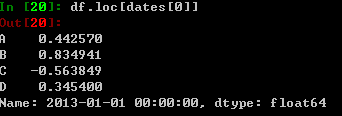
根据标记值进行选取数据:
利用标记值获得一组数据:
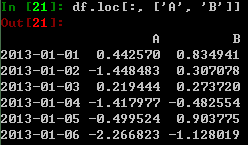
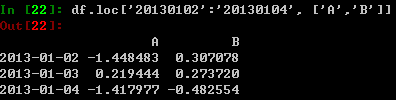
根据标记值选取多个轴上的数据:
显示标记值的切片功能,选取域包括端点
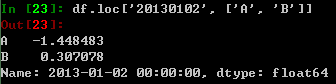
减少数据维度大小:
获取标量数值(可理解为内部元素):

快速获得一标量值(与前一方法等价):

通过位置选取
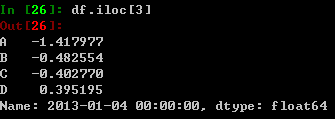
通过所在位置整数大小选取
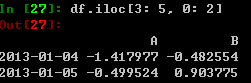
对整数进行切片,与numpy/python类似
通过一串整数列表进行位置选取,与numpy/python风格类似
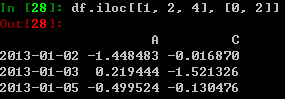
对行进行切片:
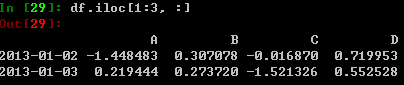
对列进行切片:
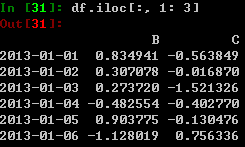
获得DataFrame中的一个值(可理解为元素):

快速获取一个标量(元素)值(与上述等价):

布尔型相关索引:
用单列数值进行数据选取:
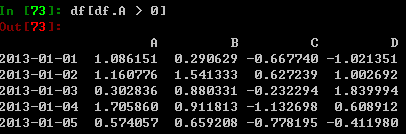
where操作方法进行数据选取:

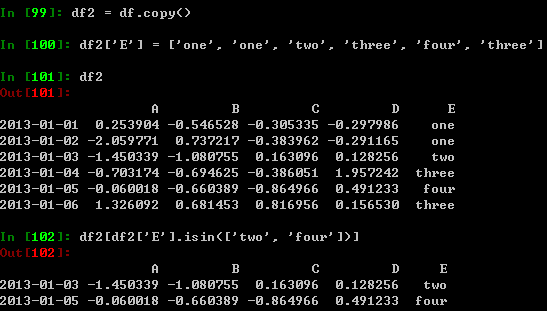
利用isin()方法过滤数据:
创建一个新列,使其数据能根据索引值自动排序:
通过标签号设置值的大小:
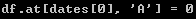
通过位置值的大小:

通过指定一个numpy数组:
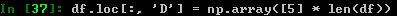
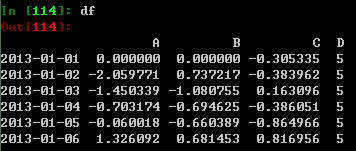
之前操作结果最终显示如下:
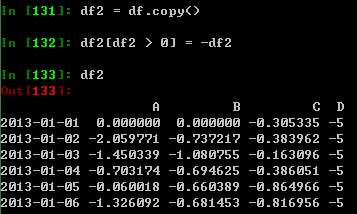
利用where操作方法进行设置:
4、数据缺失
pandas主要利用np.nan代替缺失的数据,它默认参加数据的计算,详参见:
Missing Data Section
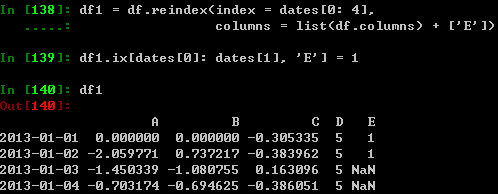
reindexing允许改变、添加及删除特定轴上的索引,其返回数据的抄本。
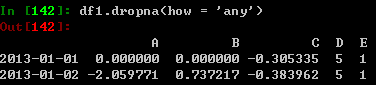
丢掉含有数据缺失的行:
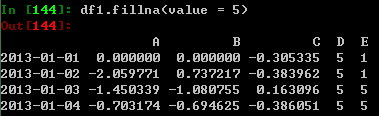
填充缺失的数据:
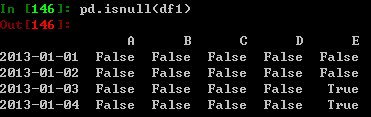
在nan值处获得布尔值:
5、操作符
详参见:Basic section on Binary Ops
操作符一般不包括缺失数据
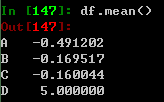
进行描述性地统计:
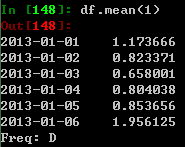
其他轴的相同操作:
操作多维数据,并且实现数据对齐。除此之外,pandas能够自动在特定的维度进行广播:
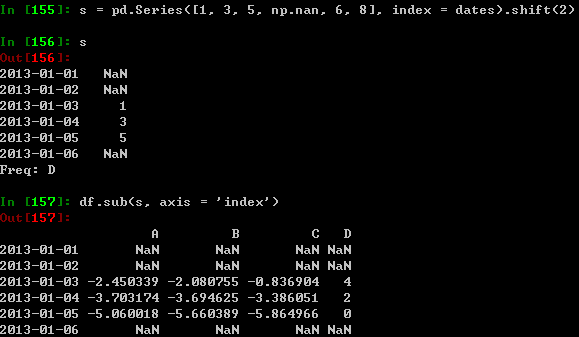
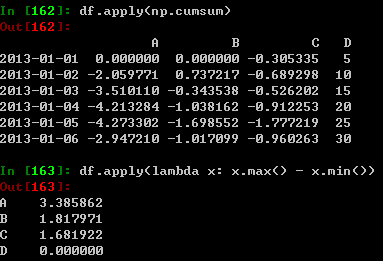
应用
将函数运用到数据中:
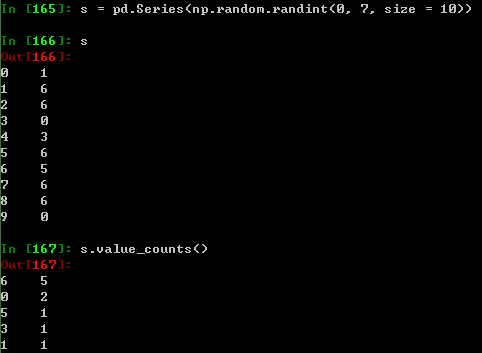
直方图
详参见:Histogramming and Discretization
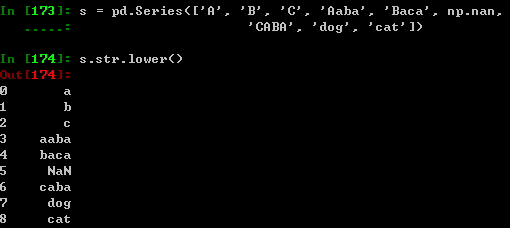
字符串方法
Series的str属性中集成了一整套的字符串处理方法,使得其能够很方便的操作数组里的每一个元素,
正如下面代码段所示。str方法中经常的方法都有其常用的使用格式(在某些情况下我们经常这样使用)。
合并
合并多个字符串或数组等多种对象
在连接或合并数据的运算中,pandas提供很多种方便的方法去将Series,Dataframe和panel对象结合在一起。
对于索引及相关代数功能提供不同的操作逻辑。
详参见:Merging section
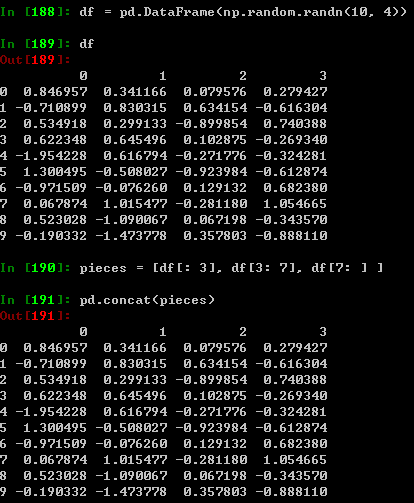
用concat()将pandas对象对象聚合在一起:
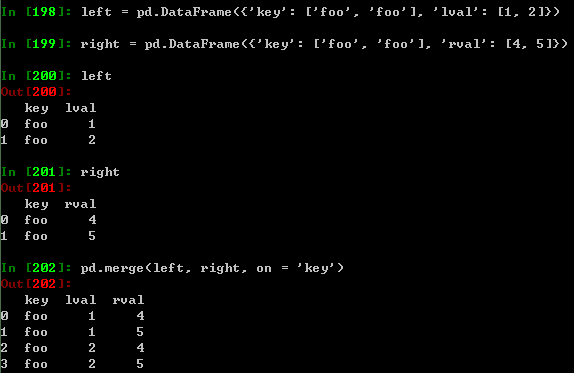
连接
SQL合并格式。详参见:Database style joining
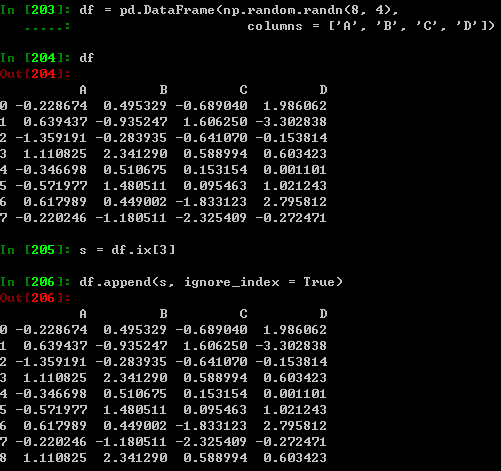
添加
在DataFrame加入一行
详参见:Appending
6、分组/分类
按组进行涉及到以下一些或者更多的过程:
按某种标准将数据分组
对各个组进行相关函数处理
将结果以合适的结构展示
详参见:Grouping Section
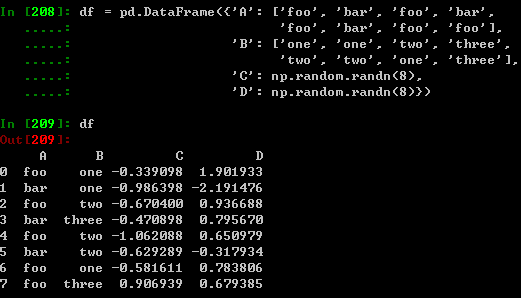
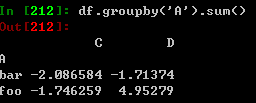
将数据分类后,对其运用sum方法:
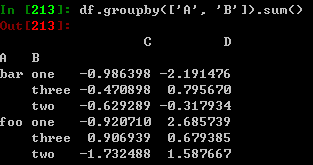
按多个列进行分类,组成层次化索引,然后运用sum方法:
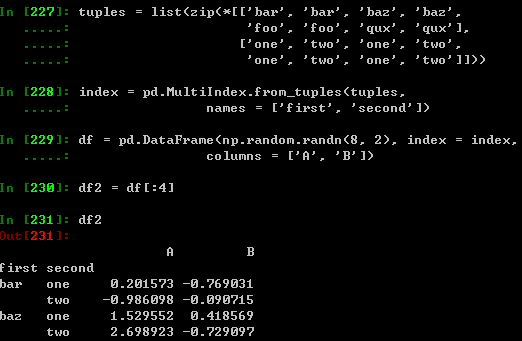
7、改变维度
详参见:Hierarchical IndexingandReshaping
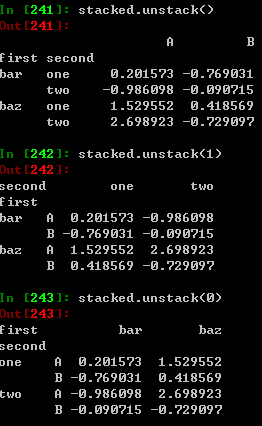
堆栈
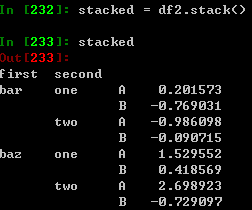
stack()方法精简了DataFrame的列:
对于DataFrame或Series,stack()方法的相反操作为unstack(),默认unstack到)的上一个状态
pivot表格
详参见:Pivot Tables
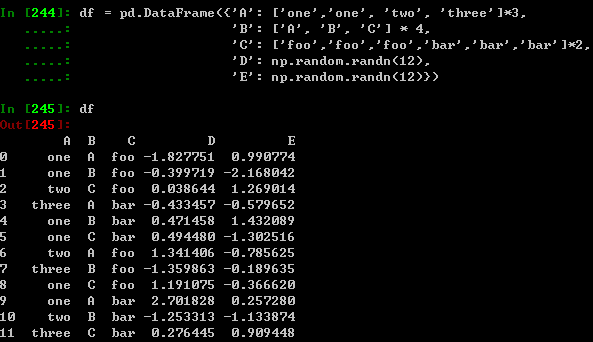
我们可以很容易从上述数据中得到pivot表格:
注:由于pandas版本问题,无法实现
时间序列
pandas对于频率变换中重采样的实现方面,简单且高效(如下面的操作)。这在金融方面非常常见,但并不仅限于此。
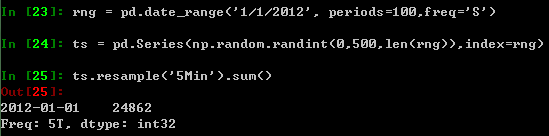
时间域表示
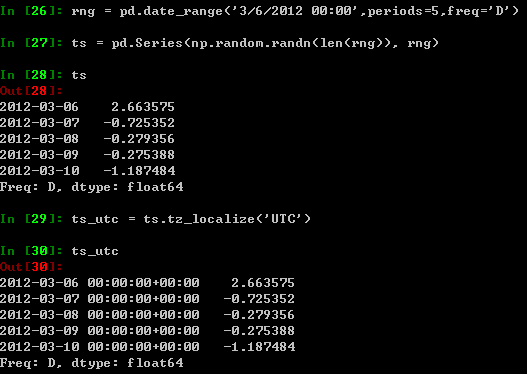
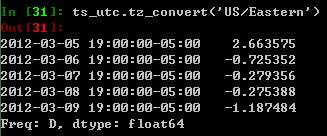
转换成另一种时间域表示
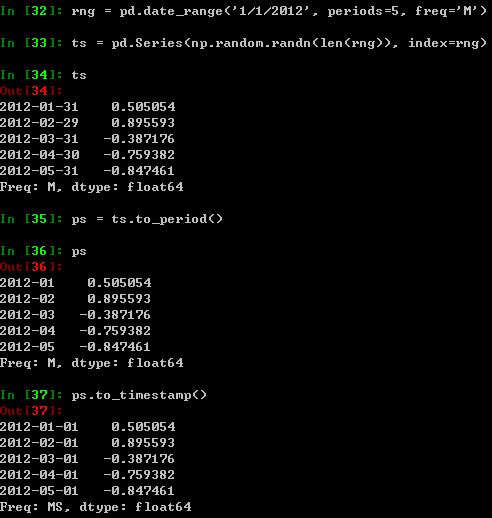
时间跨度表示之间的转换:
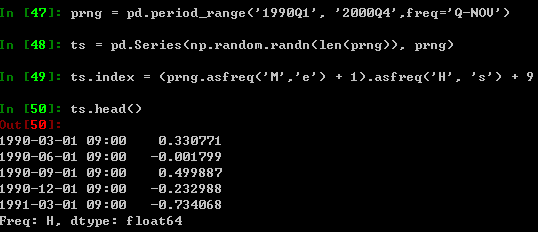
可以用一些便利的函数实现日期及时间戳间的转换。在下面的例子中,将年的季度域分隔转换成
以各个季度最后一个月的后一天早上9点作为时间域分隔:
8、分类属性
自pandas 0.15版本,在DataFrame中就开始包括分类属性。
详参见:categorical introduction 和API documentation

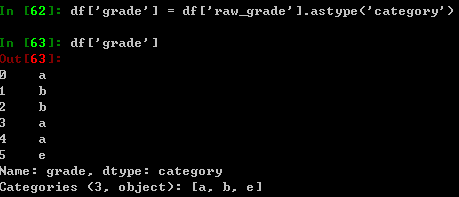
将raw grades 转换成一般数据类型:
使用更多有意义的名字作为分类名,以 Series.cat.categories 实现:
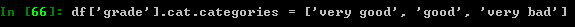
记住分类属性,同时加入一些缺少的属性( Series.cat方法返回一个新的Series ):

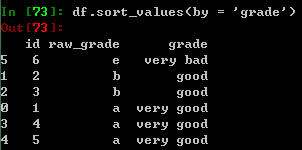
Categories里的排序是按照属性顺序,并不是类似字典的排序规则:
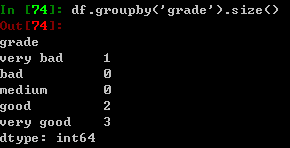
通过列的属性分组,则属性不显示:
9、绘图
详参见:Plotting
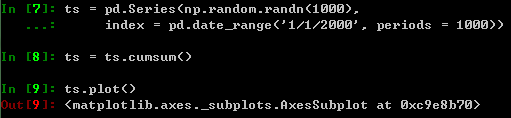
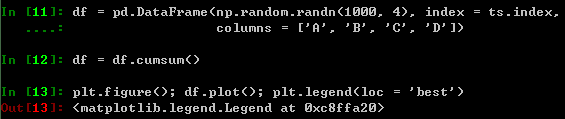
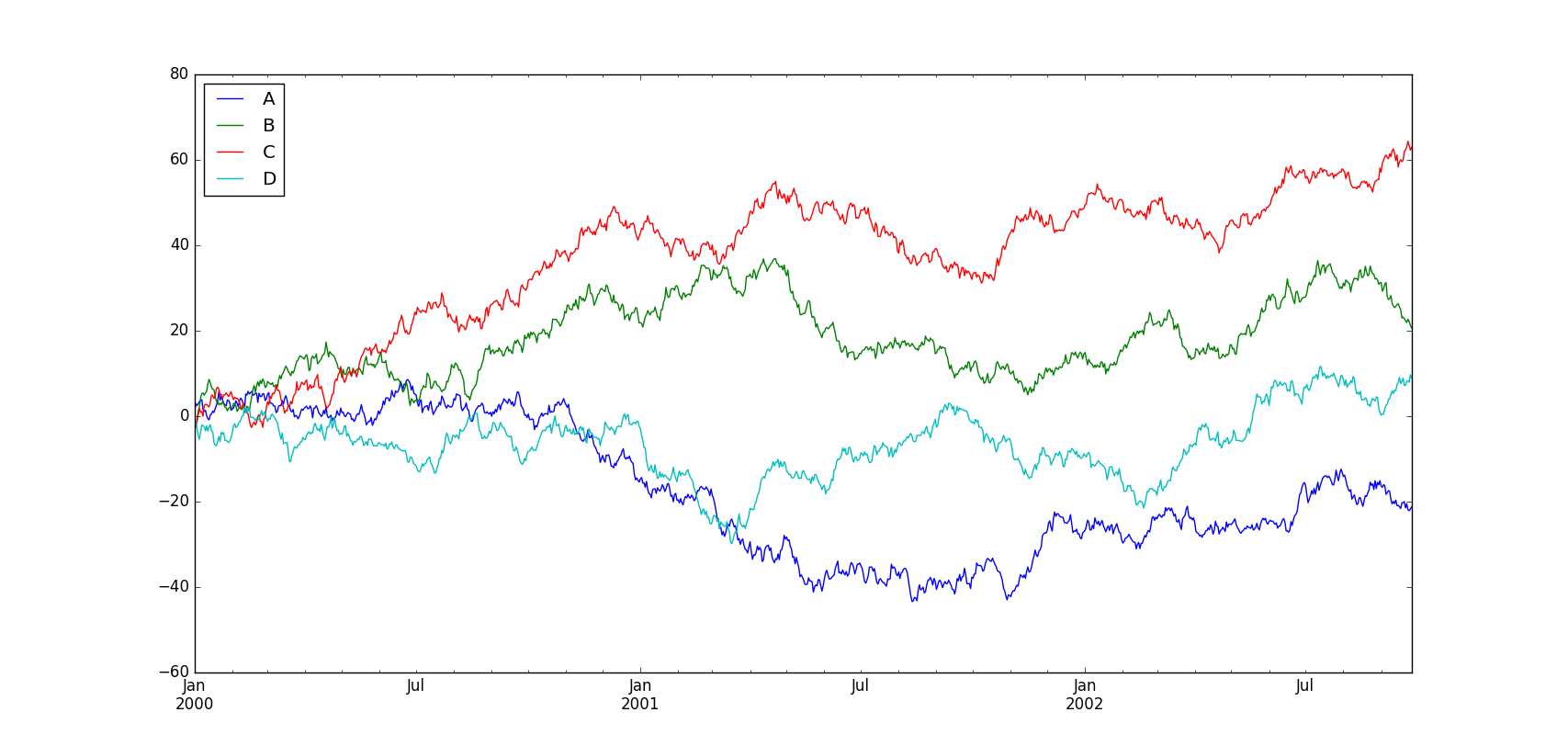
在DataFrame中,plot( )方法能够方便地根据列标签绘图:
10、数据的输入输出
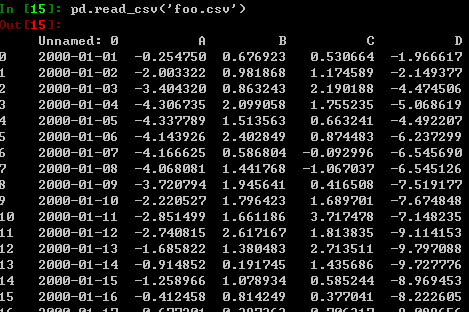
csv格式

读写层次性资料格式数据
详参见:HDFStores
写入数据:
读取数据:
Excel
详参见:MS Excel
向excel表中写数据:
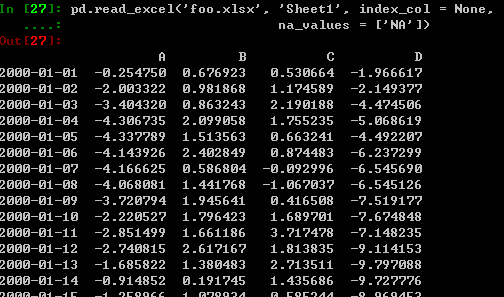
从excel表中读数据:
11、Gotchas
如果你在操作时遇见异常:
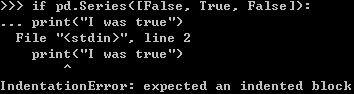
遇到这些情况,可以参见:Comparisons 和Gotchas。
注:操作环境
笔记本系统: win7 64位旗舰版
使用软件:Canopy
Version:1.7.4.3384(64bit)
附下载链接:https://store.enthought.com/downloads/#default















 674
674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









