







 So-vits-svc 基于端到端架构的VITS和soft-vc,用户只需准备几十分钟到几个小时不等的语音或歌声数据,就能制作(训练)属于自己的 AI 声库 (前提是你的显卡足够给力),将一段语音或歌声转换为你想要的音色。
So-vits-svc 基于端到端架构的VITS和soft-vc,用户只需准备几十分钟到几个小时不等的语音或歌声数据,就能制作(训练)属于自己的 AI 声库 (前提是你的显卡足够给力),将一段语音或歌声转换为你想要的音色。
So-vits-svc 基于端到端架构的VITS和soft-vc,用户只需准备几十分钟到几个小时不等的语音或歌声数据,就能制作(训练)属于自己的 AI 声库 (前提是你的显卡足够给力),将一段语音或歌声转换为你想要的音色。

模型下载
项目下载后需要下载模型放入文件夹中
下载 checkpoint_best_legacy_500.pt放到hubert文件夹
下载模型文件: G_0.pth D_0.pth,把他们放到 logs/44k 文件夹
三个模型文件链接在文章后面
修改config文件
把configs_template文件夹下的configs_template.json 复制到configs文件下,修改名字为 config.json。
config.json几个注意点
“log_interval”: 200,每200步输出 log
“eval_interval”: 800,每800步输出一个模型文件
“epochs”: 10000,训练1万轮
“learning_rate”: 0.0001,学习率
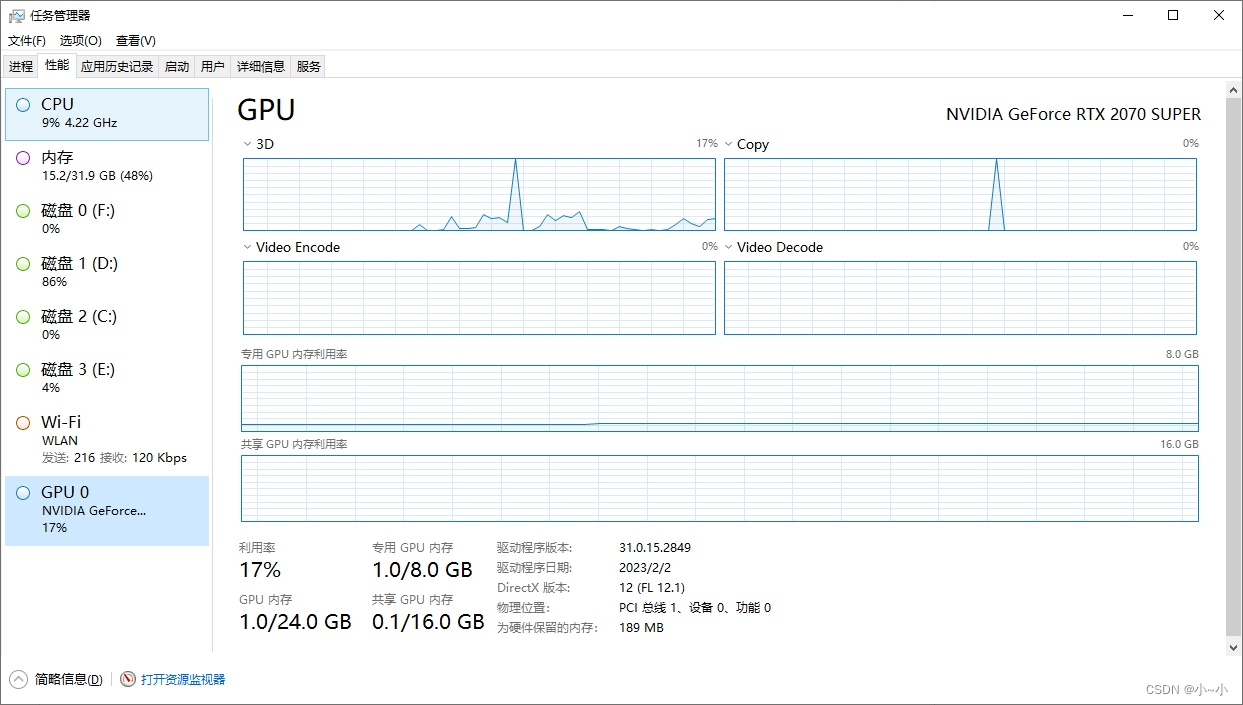
“batch_size”: 6,让机器同时学习多少个数据,越多占用显存就越多,要看看自己的显存多少来进行修改。可以在任务管理器查看 GPU 的内存,下面截图的显存为8G
 <
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2431
2431











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











