








引言
一个进程,包括代码、数据和分配给进程的资源。fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就是两个进程可以做完全相同的事,但如果初始参数或者传入的变量不同,两个进程也可以做不同的事。
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
#include <iostream>
#include <unistd.h>
using namespace std;
int main(){
pid_t fpid = fork();
int cnt = 0;
if (fpid < 0){
cout << "开启进程失败! "<< endl;
}else if(fpid == 0){
cout << endl << "子进程 pid : " << getpid() << endl;
cnt++;
cout << "cnt = " << cnt << endl;
}
else{
cout << endl << "父进程 pid : " << getpid() << endl;
cnt++;
cout << "cnt = " << cnt << endl;
}
cout << "Finally, 进程 pid : " << getpid();
cout << ", cnt = " << cnt << endl;
return 0;
}父进程 pid : 3500
cnt = 1
Finally, 进程 pid : 3500, cnt = 1
子进程 pid : 3501
cnt = 1
Finally, 进程 pid : 3501, cnt = 1
如何判断父/子线程?
pid_t fpid = fork()会有返回值,会返回两次,通过判断fpid的值,可以知道是父/子线程。
fpid<0
线程开启失败fpid==0
子线程其他(实际上是子进程的pid)
父进程
要知道:fpid只是一个判断的标志,但是值得注意的是pid与fork返回的fpid就像链表一样,连接着父/子进程,子进程没有创建其他进程,所以子进程的fpid==0,如上例中,

fork进阶
#include <iostream>
#include <unistd.h>
#include <stdio.h>
using namespace std;
int main()
{
int i = 0;
// ppid指当前进程的父进程pid
// pid指当前进程的pid,
// fpid指fork返回给当前进程的值
cout << "i\tson/pa \tppid\tpid\tfpid" << endl;
for (i = 0; i<2; i++){
pid_t fpid = fork();
if (fpid == 0)
printf("%d \tchild \t%4d \t%4d \t%4d\n", i, getppid(), getpid(), fpid);
else
printf("%d \tparent \t%4d \t%4d \t%4d\n", i, getppid(), getpid(), fpid);
}
return 0;
}i son/pa ppid pid fpid
0 parent 3176 3604 3605
1 parent 3176 3604 3606
1 child 1252 3606 0
0 child 1252 3605 0
1 parent 1252 3605 3607
1 child 1252 3607 0上面的结果什么意思?且看下图,

再看一份代码:
#include <unistd.h>
#include <stdio.h>
int main(void)
{
int i=0;
for(i=0;i<3;i++){
pid_t fpid=fork();
if(fpid==0)
printf("son\n");
else
printf("father\n");
}
return 0;
}她的结果是,
father
father
father
son
son
father
son
father
father
son
son
son
father
son实际上和上面那个图有点类似,简单来说就是一次fork就会产生一个parent和一个child,产生的parent和当前进程的pid是一样的,子进程则是在这个基础上加上一个偏移。
for i=0 1 2
father father father
son
son father
son
son father father
son
son father
son其中每一行分别代表一个进程的运行打印结果。
总结一下规律,对于这种N次循环的情况,执行printf函数的次数为 2×(1+2+4+……+2N−1) 次,创建的子进程数为 1+2+4+……+2N−1 个.数学推理见http://202.117.3.13/wordpress/?p=81(该博文的最后)。
同时,大家如果想测一下一个程序中到底创建了几个子进程,最好的方法就是调用printf函数打印该进程的pid,也即调用printf(“%d\n”,getpid());或者通过printf(“+\n”);来判断产生了几个进程。有人想通过调用printf(“+”);来统计创建了几个进程,这是不妥当的。具体原因我来分析。
老规矩,大家看一下下面的代码:
#include <unistd.h>
#include <stdio.h>
int main() {
pid_t fpid;//fpid表示fork函数返回的值
//printf("fork!");
printf("fork!\n");
fpid = fork();
if (fpid < 0)
printf("error in fork!");
else if (fpid == 0)
printf("I am the child process, my process id is %d\n", getpid());
else
printf("I am the parent process, my process id is %d\n", getpid());
return 0;
} 执行结果如下:
fork!
I am the parent process, my process id is 3361
I am the child process, my process id is 3362
如果把语句printf(“fork!/n”);注释掉,执行printf(“fork!”);则新的程序的执行结果是:
fork!I am the parent process, my process id is 3298
fork!I am the child process, my process id is 3299
程序的唯一的区别就在于一个/n回车符号,为什么结果会相差这么大呢?
这就跟printf的缓冲机制有关了,printf某些内容时,操作系统仅仅是把该内容放到了stdout的缓冲队列里了,并没有实际的写到屏幕上。但是,只要看到有/n 则会立即刷新stdout,因此就马上能够打印了。
运行了printf(“fork!”)后,“fork!”仅仅被放到了缓冲里,程序运行到fork时缓冲里面的“fork!” 被子进程复制过去了。因此在子进程度stdout缓冲里面就也有了fork! 。所以,你最终看到的会是fork! 被printf了2次!!!!
而运行printf(“fork! /n”)后,“fork!”被立即打印到了屏幕上,之后fork到的子进程里的stdout缓冲里不会有fork! 内容。因此你看到的结果会是fork! 被printf了1次!!!!
所以说printf(“+”);不能正确地反应进程的数量。大家看了这么多可能有点疲倦吧,不过我还得贴最后一份代码来进一步分析fork函数。
fork了多少次
#include <stdio.h>
#include <unistd.h>
int main(int argc, char* argv[])
{
fork();
fork() && fork() || fork();
fork();
printf("+\n");
}运行结果为20次,还有19个进程,为什么是还有19个进程?
第一个fork和最后一个fork肯定是会执行的,主要在中间3个fork上,可以画一个图进行描述。
这里就需要注意&&和||运算符:
A&&B,如果A=0,就没有必要继续执行&&B了;A非0,就需要继续执行&&B。
A||B,如果A非0,就没有必要继续执行||B了,A=0,就需要继续执行||B。
fork()对于父进程和子进程的返回值是不同的,按照上面的A&&B和A||B的分支进行画图,可以得出5个分支。
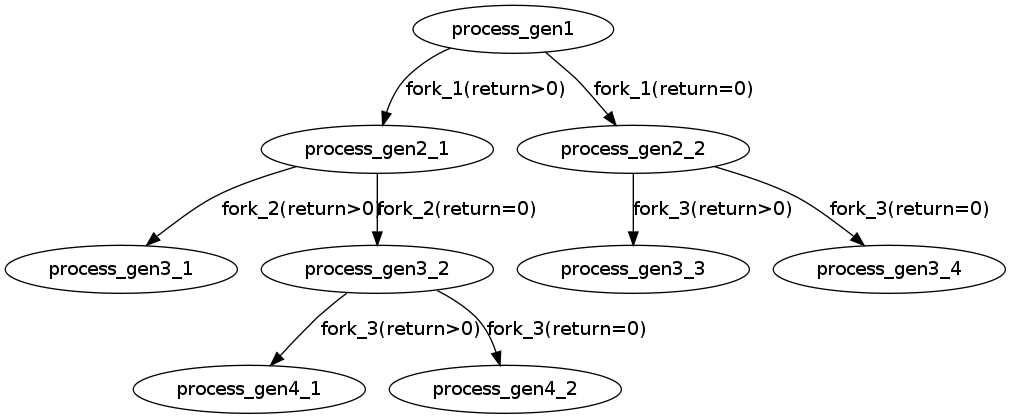
加上前面的fork和最后的fork,总共4*5=20个进程,除去main主进程,就是19个进程了。















 2922
2922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









