







本文转载至http://blog.csdn.net/yzheately/article/details/51164441。
之前介绍了EM算法在混合高斯模型中的应用,现在让我们来看看问什么EM算法可以用于这类问题。
首先介绍一下Jensen 不等式
Jensen 不等式
我们知道,如果设 f 是凸函数。
显然我们的样本x的 hessian 矩阵 H 是半正定的( H ≥ 0)。
关于矩阵的正定性参考知乎https://www.zhihu.com/question/22098422?sort=created。
begin-补充-hessian矩阵
对于一个实值多元函数f(x1,x2,...,xn)
其中 D_i表示对第i,上式展开成矩阵形式如下:
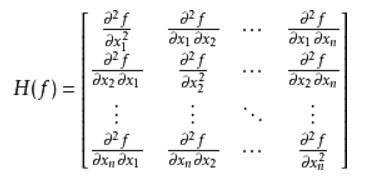
可见如果hessian矩阵存在那么它必然是对称的因为求偏导数时的求导顺序并不影响最终结果:
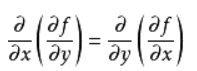
利用hessian进行多元函数极值的判定:
如果实值多元函数f(x1,x2,...,xn)二阶连续可导,我们可以利用某个临界点M处的hessian矩阵判断该临界点是否为极值:
如果H(M)是正定矩阵,则临界点M处是一个局部的极小值。
如果H(M)是负定矩阵,则临界点M处是一个局部的极大值。
如果H(M)是不定矩阵,则临界点M处不是极值。
end-补充-hessian矩阵
如果f′′(x)≥0的二阶导数。
下面给出jensen不等式定理:
如果 f 是凸函数, X 是随机变量,那么
特别地,如果 f 是常量时。
为了便于理解咱们先看下面:
凸函数的概念:
【定义】如果函数f(x)为凸函数。
注意哦开口向下的是凸,开口向上的是凹。
如果不等式中等号只有 时才成立,我们分别称它们为严格的凹凸函数.
推广下就是:
对于任意的凹函数f(x)
对于任意的凸函数f(x)
如果上面凹凸是严格的,那么不等式的等号只有x1=x2=...=xn才成立.
其实上面的结论就是我们的jensen不等式,相信大家都见过。
可将jensen用图形表示如下:
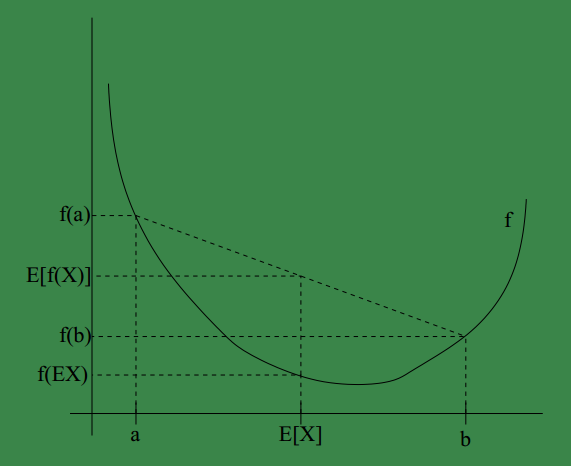
其中E(X)。
另外, f 是(严格)凸函数。
Jensen 不等式应用于凹函数时,不等号方向反向,也就是E[f(X)]≤f(E[X]).
EM算法
假如我们有训练样本集{x(1),x(2),...,x(n)的参数的方式是利用似然值:
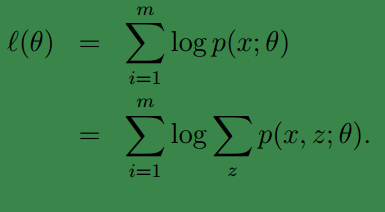
但是在上一篇中我们提到由于z(i) 后,求解就容易了。
EM 是一种解决存在隐含变量优化问题的有效方法。其思想是:不断地建立ℓ 步)。这就话没看懂吧!看不懂正常,下面来详细介绍EM算法:
对于每一个样例 i是概率密度函数,需要将求和符号换做积分符号)。
这样我们可以得到:
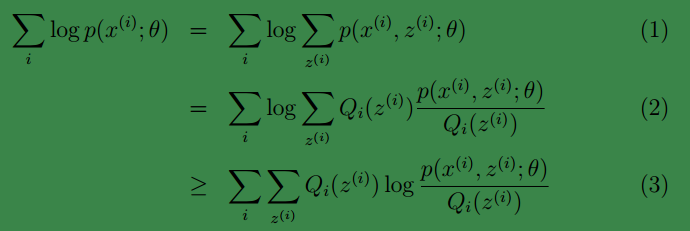
注:
1、(1)到(2)比较直接,就是分子分母同乘以一个相等的函数。
2、(2)到(3)利用了 Jensen不等式;首先log函数是凹函数。其次根据lazy Statistician规则,可知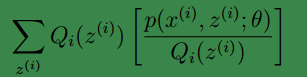
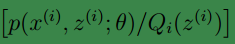
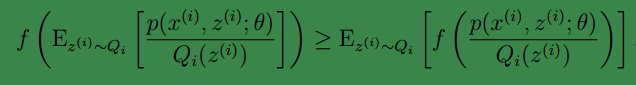
begin-补充-Lazy Statistician规则
设 Y 是连续函数),那么
(1) X绝对收敛,则有
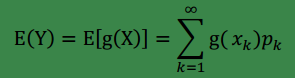
(2) X,若∫∞−∞g(x)f(x)dx∫^∞ _{−∞}g(x)f(x)dx 绝对收敛,则有
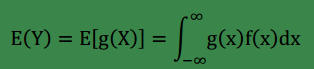
end-补充
因此,对于任何一种分布Qi的选择,有多种可能,那种更好的?
(我们知道,在EM算法中的E步中,我们的θ
其中c.
进而可得:
Qi(z(i))=p(x(i),z(i);θ)c=p(x(i),z(i);θ)∑zp(x(i),z(i);θ)=p(x(i),z(i);θ)p(x(i);θ)
再利用条件概率公式可得:Qi(z(i))=p(z(i)|x(i);θ)
上面的推导有点乱,现在把他们压缩下就是:
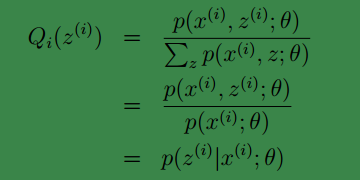
现在我们知道Qi(z(i)).
这一步就是E算法的步骤如下:
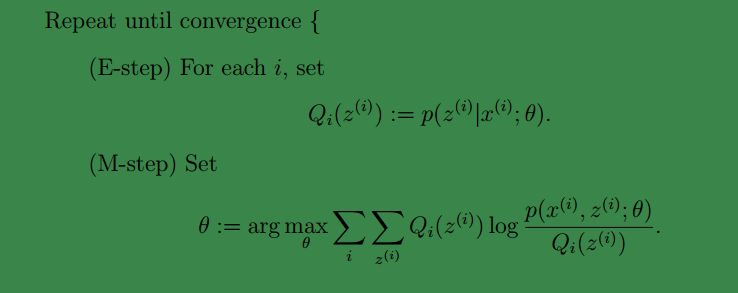
下面让我们来证明EM算法的收敛性:
假定θ(t)和θ(t+1)是 EM 第 t 次和 t+1 次迭代后的结果。 如果我们证明了ℓ(θ(t)) ≤ ℓ(θ(t+1)),也就是说极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。 下面来证明,选定θ(t)如下:
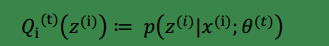
进而等号满足:
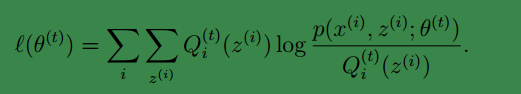
然后我们通过最大化上面等式的式右面获得了新的参数θt+1.
此时必然有:
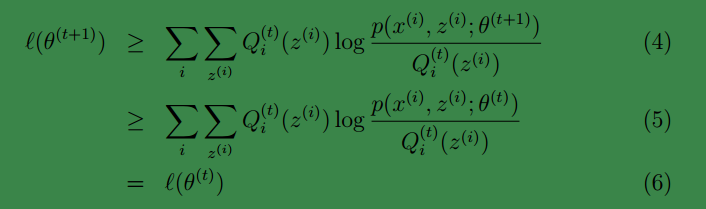
上面第一行是由式(3)得到,即基于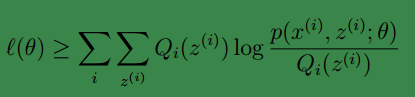
第( 5)步利用了 M 步的定义。第( 5)步利用了 M 步的定义, M 步就是将θ(t)调整到θ(t+1),即θ(t+1)的选择是基于:
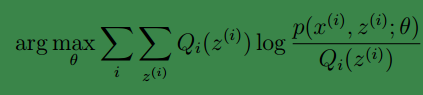
这样就证明了ℓ(θ)会单调增加。因此EM算法是收敛的。
如果我们定义:
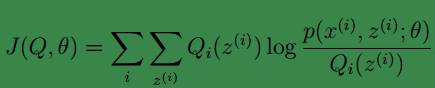
从前面的推导中我们知道ℓ(θ) ≥ J(Q, θ), EM 可以看作是 J 的坐标上升法, E 步固定θ,优化Q, M 步固定Q优化θ。
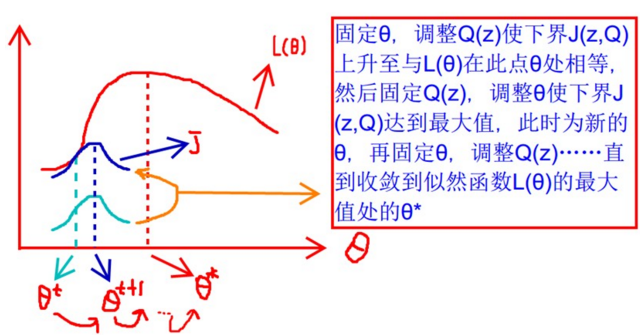
下面从别人那偷了张图,很好的说明了EM算法的优化过程:















 757
757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









