









Python中3+版本运行2+版本程序出现TypeError: a bytes-like object is required, not 'str'问题之提取PDF中的图片程序
问题1. 本文中出现这一问题的场景(还有套接字的编程也有这一问题)
本文中是因为在3.5的Python版本中使用了2.7版本的程序,在一定的修改后出现open(“filename”,"rb")读取的结果在使用find函数的时候出现的上述错误。这种错误是因为以“rb”方式读取的的数据是byte数据,是二进制的方式读取的,所以在使用find的函数的时候也一定要使用相同的数据类型的数据,即也要使用比特数据。具体的操作只修要在find函数要查找的字符串的前面加上一个字符b即可。
问题2. 提取PDF中的图片的例子
原程序是用Python2.7编写的,网址:https://stackoverflow.com/questions/43212573/textract-cannot-read-a-jpegimagefile-stringio-objects/43317792#43317792,更改过后的程序如下
pdf = open('E:GET201506.pdf', "rb").read()
startmark = "\xff\xd8"
startfix = 0
endmark = "\xff\xd9"
endfix = 2
i = 0
njpg = 0
while True:
istream = pdf.find(b"stream", i)
if istream < 0:
break
istart = pdf.find(b"\xff\xd8", istream, istream+20)
if istart < 0:
i = istream+20
continue
iend = pdf.find(b"endstream", istart)
if iend < 0:
raise Exception("Didn't find end of stream!")
iend = pdf.find(b"\xff\xd9", iend-20)
if iend < 0:
raise Exception("Didn't find end of JPG!")
istart += startfix
iend += endfix
print("JPG %d from %d to %d" % (njpg, istart, iend))
jpg = pdf[istart:iend]
jpgfile = open("jpg%d.jpg" % njpg, "wb")
jpgfile.write(jpg)
jpgfile.close()
njpg += 1
i = iend
运行的结果如下
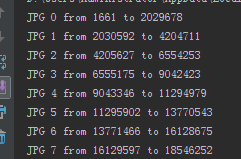

程序的关键是找到“stream”和“endstream”,以及以下两个字段的位置,startmark就是图片数据开始,endmark就是图片数据的结束。
startmark = "\xff\xd8"
endmark = "\xff\xd9"
这是因为对于JPEG文件有固定的文件头和文件尾:
Start Marker | JFIF Marker | Header Length | Identifier 0xff, 0xd8 | 0xff, 0xe0 | 2-bytes | "JFIF\0"

尾部数据如下图:
















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









