







RDF介绍
- 任何的实体都可以被认为是一个节点
- 命名空间可用于限定名称的范围
- 资源的属性可以被定义
- 资源之间的关系可以被定义
- 资源可以由不同的人或组织提供,并且可以位于语义网上的任何位置
RDF示例

利用现有的关系数据库系统存储RDF数据
将SPARQL语句重写转换成SQL查询语句,并执行这些SQL语句从而得到答案
示例

缺点
SPO三列表规模比较大时,存在大量的self-join操作,复杂度比较高
属性表(Property Tables)
属性表简介
在知识图谱中,不同类型的实体的数据都在同一张大表当中。属性表为了更好地去存储知识图谱数据,将原始数据进行聚类,即将所有同一类别的实体放到同一张表当中
聚类的两种方法
1、属性类表(Property-class Table):对每个实体定义一个类别标签(rdf:type),将具有相同属性类型的实体聚集到一个属性表中
2、聚类属性表(Clustered Property Table):有些实体并没有严格定义属于哪个类别,根据实体所具有的属性,属性相似的聚类到一张表里
示例
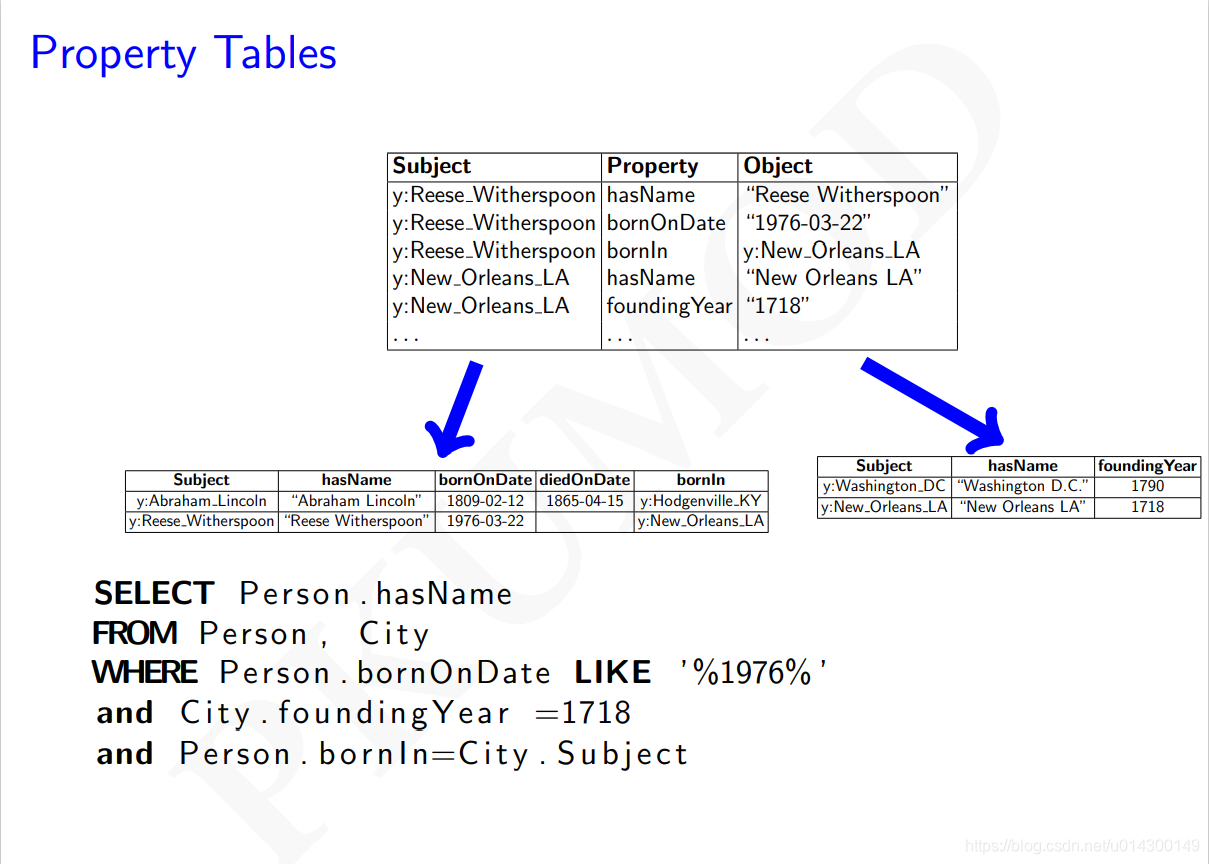
优点
1、减少join的次数,简化了查询
2、当数据的结构性更强的时候,更适合用这种关系数据库的方法来存储
缺点
1、会产生大量的空值(NULL),即属性表中的每一个实体不一定在每个属性下面都有值
2、对多值属性而言,属性表非常难以解决
二列表(Binary Tables)
二列表简介
对SPO三列表中实体的每一种属性都建立一个二列表,有多少种属性就建立多少张表,每张表有两列,一列是主语(subject),一列是宾语(object),然后从属性中做join连接
示例
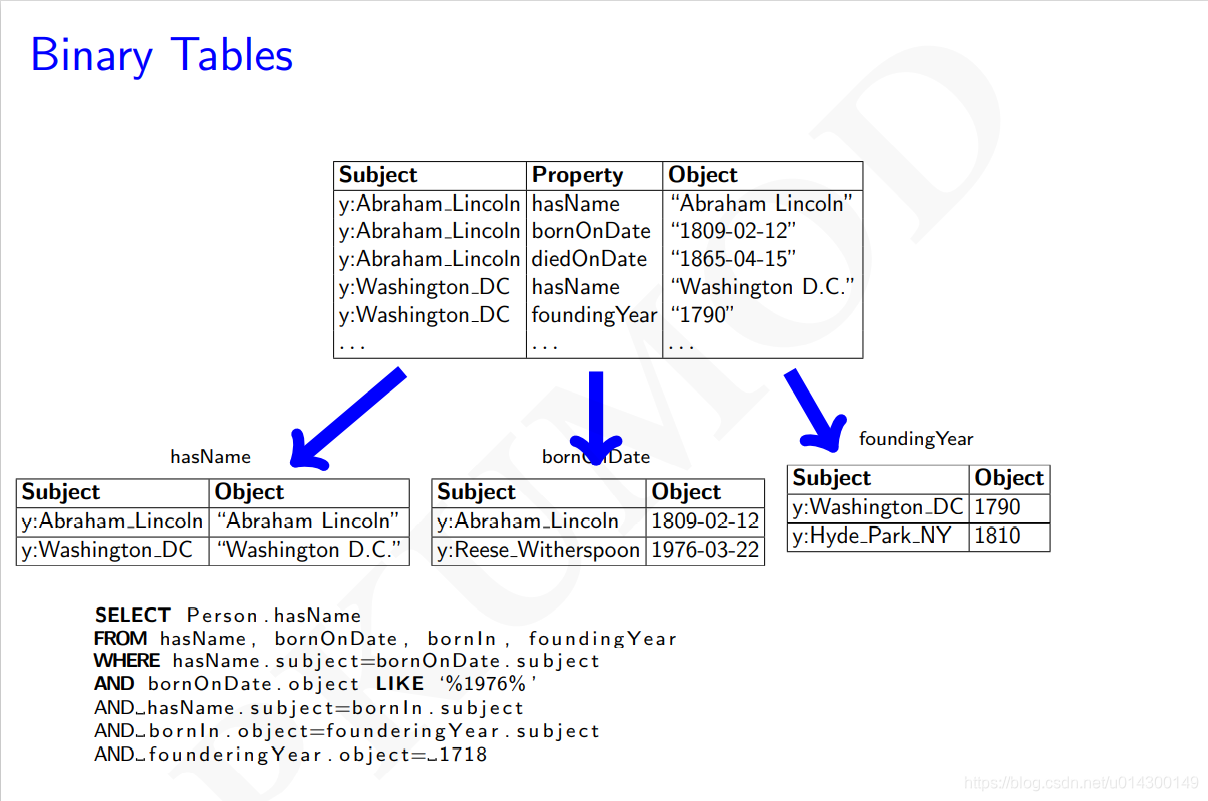
优点
1、支持多值属性的表的建立
2、不会存在空值(NULL)
3、对主体与主体(subject-subject)的join连接操作友好
4、没有聚类(clustering)
5、只读取所需要的属性,减少了输入输出操作
缺点
1、对客体与客体(object-object)、主体与客体(subject-object)的join连接是不友好的
2、没有做排序,插入代价比较大
全索引(Exhaustive Indexing)
全索引简介
对SPO三列表中的所有主语(subject)、谓词(property)、宾语(object)的排列组合进行一个排序。使用映射表将字符串映射成一个ID,对ID的所有可能的排列组合进行排序,节省存储空间;三元组按字典序在一个聚类B+树中建立索引。SPO三列表的所有排序为:SPO,SOP,PSO,POS,OPS,OSP
示例


优点
1、每一个triple pattern都被一个范围查询所替代
2、triple pattern之间做自然连接时可以做merge join操作
缺点
空间消耗比较大,数据更新比较麻烦
基于图的方法
核心思想
基于子图匹配的方法来回答SPARQL的查询
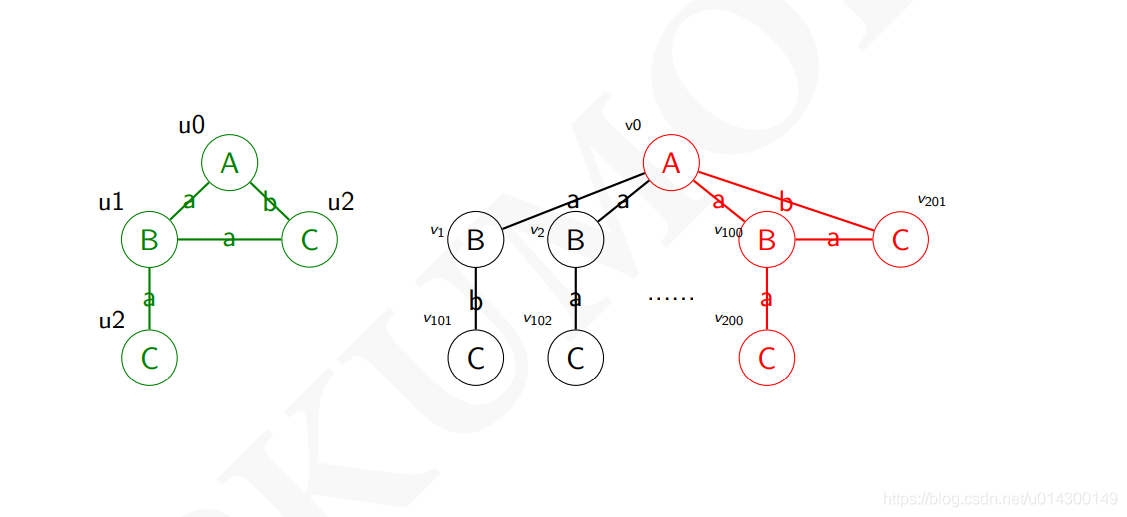
子图匹配的概念
给一个查询图q和一个比较大的图Q,找到q在Q中所匹配的位置,即存在一对一的方式,得到一个图匹配(Subgraph Isomorphism)
示例:
子图匹配的方法
最核心的方法:树搜索
示例:
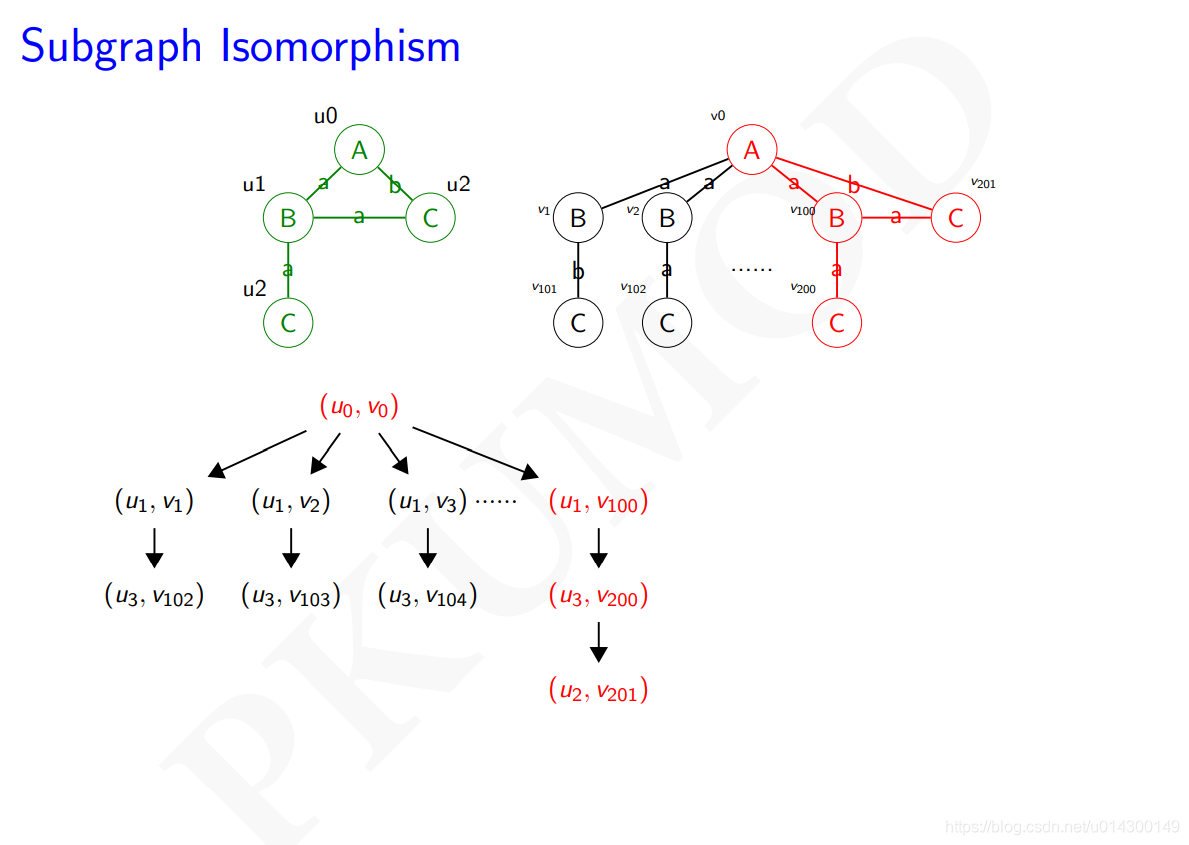
树搜索的两种方法:深度搜索(DFS)、宽度搜索(BFS)
BFS搜索方法的两种策略
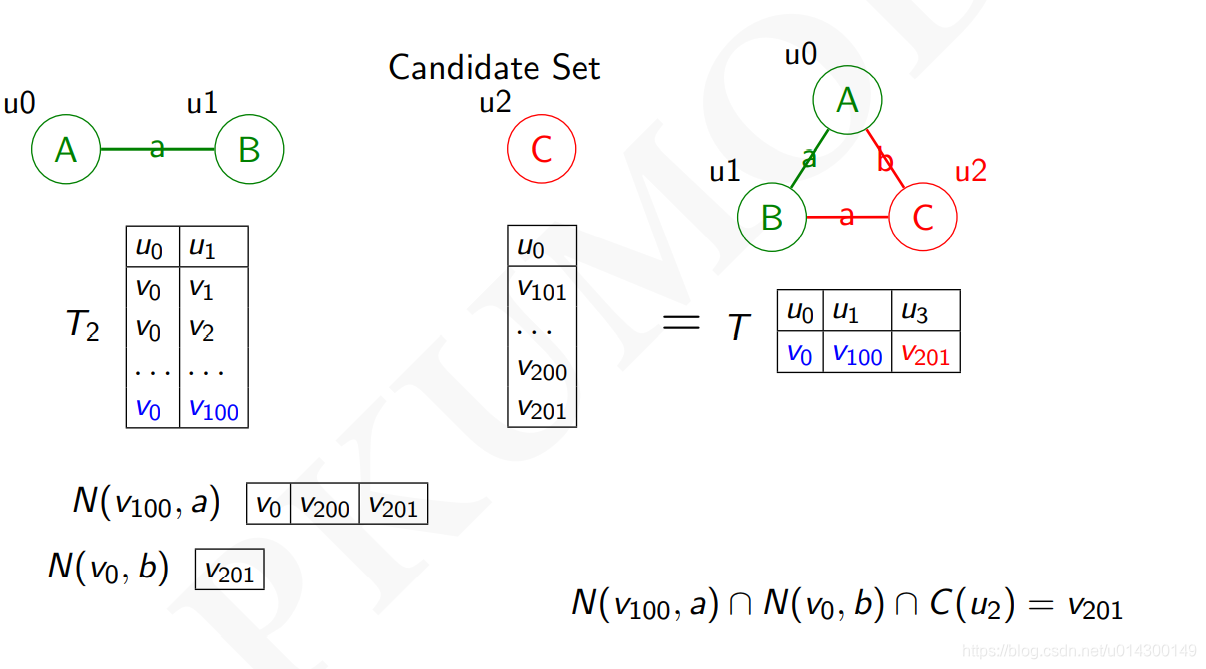
1、基于边的自然连接(Edge-Join):最开始得到每条边的匹配,然后对某两条边做自然连接(Join)

2、基于节点的自然连接(Vertex-Join):最开始得到一个节点的点表,假设在上一步已经得到子图的一部分,得到边表,如果点表有一个点能加到边表的匹配结果中来时,则说明该节点是子图的那一部分的节点的邻居
示例:














 8722
8722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









