







在MapReduce中,map和reduce函数的输入和输出都是键/值对。
MapReduce的函数一般遵循以下常规格式:
<span style="font-size:14px;">map:(K1, V1)—> list(K2,V2)
combine:(K2,list(V2))—> list(K2,V2)
partition:(K2,V2)—> integer
reduce: (K2,list(V2))—> list(K3,V3)</span>
map:对数据进行抽取,组织key/value等操作。
combine:为了减少集群内部的数据传输带宽和reduce输入,在map端进行了合并的预处理。combine与reduce函数的作用和形式相同,不同的是,combine函数的输出类型是中间过程的键值对(K2,V2)。
partition:将中间过程的键值对划分到相应的reduce分区,并返回分区索引号。实际上,分区只由键决定。
reduce:对map的输出结果进行统计合并操作,并把结果输出到共享文件系统(例如:HDFS)。
2. 输入格式
从一般的文本文件到数据库,Hadoop可以处理多种类型的数据格式。
2.1 输入分片
一个输入分片(input split)就是由单个map处理的输入块。每个分片由多条记录组成,每条记录就是一个键值对。输入分片和记录都是逻辑的,不必将他们对应到文件上。注意,分片不包含数据本身,而是指向数据的引用。
分片包含的信息有:分片数据的长度(以字节为单位统计),以及分片数据的存储位置。长度用于排序分片,以便优先处理最大分片,减小作业运行时间;存储位置可以使JobTracker把map任务放在分片数据附近,减小网络传输负载。
2.2 InputFormat
InputFormat创建输入分片并将它们分割成记录,步骤如下:
<1>JobClient调用InputFormat接口的getSplit方法,计算分片的数量,并把分片数量发送到JobTracker。
<2>JobTracker根据其位置存储信息,调度map任务的执行。
<3>在TaskTracker上,map任务把输入分片作为参数传给InputFormat的createRecordReader方法,该方法返回RecordReader。map任务使用RecordReader来生成记录的键/值对,然后再把记录传给map函数。
InputFormat的类层次结构如下所示:
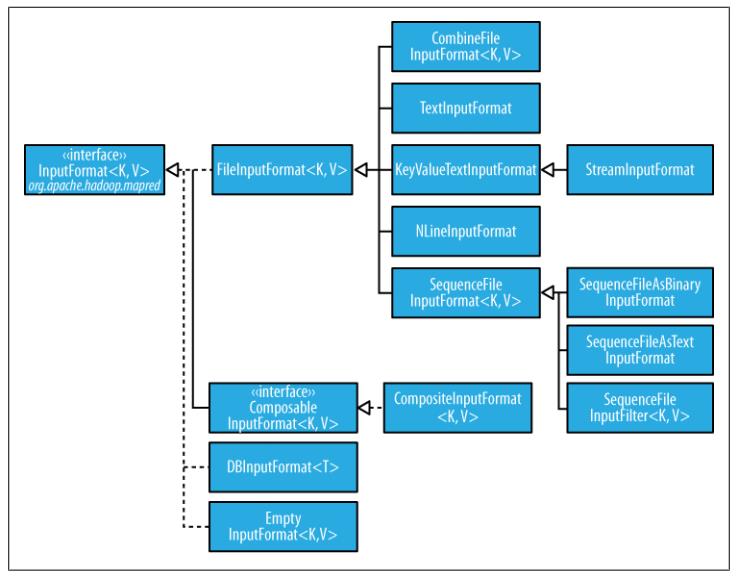
2.3. FileInputFormat类
- 作用:
FileInputFormat是所有以文件作为数据源的InputFormat实现类的基类。它提供了两个功能:
<1>定义哪些文件包含在一个作业的输入中;
<2>为输入文件生成分片。另外,将分片分割成记录的过程由其子类完成。
- 设定输入路径:
FileInputFormat提供了四种静态方法来设定Job的输入路径,其中下面的addInputPath()方法addInputPaths()方法可以将一个或多个路径加入路径列表,setInputPaths()方法一次设定完整的路径列表(可以替换前面所设路径)。
public static void addInputPath(Job job, Path path);
public static void addInputPaths(Job job, String commaSeparatedPaths);
public static void setInputPaths(Job job, Path... inputPaths);
public static void setInputPaths(Job job, String commaSeparatedPaths);
如果需要排除特定文件,可以使用FileInputFormat的setInputPathFilter()设置一个过滤器:
public static void setInputPathFilter(Job job, Class<? extends PathFilter> filter);
- 输入分片:
给定一组文件,FileInputFormat如何把它们转为分片?其实,FileInputFormat只分割超过HDFS块大小的文件,所以分片大小通常与HDFS块大小相同。
- 避免切分:
有些应用程序希望用一个mapper完整处理每个输入文件,不希望文件被切分。保证输入文件不被切分有两种方法:第一种方法是,将最小输入分片的大小mapred.min.split.size设置为Long.MAX_VALUE(long类型的最大值);第二种方法比较灵活,使用FileInputFormat的子类,重载isSplitable( )方法把返回值设置为false。
- 把整个文件作为一条记录处理:
有时,mapper需要访问一个大文件的全部内容,即把整个文件当做一条记录来处理。此时,可以使用WholeFileInputFormat。
A. CombineFileInputFormat
由上述可知,FileInputFormat只分割大于HDFS块的文件。如果作业中有大批量的小文件,hadoop的运行时间就会非常缓慢。因为每个文件都需要使用一个map操作,而每次map操作都会带来额外开销(线程的调度、启动等)。解决方法是,使用CombineFileInputFormat把多个小文件合并成一个大的分片。很重要的一点是,CombineFileInputFormat在决定哪些文件放入同一个分片时,会考虑节点和机架的因素,所以MapReduce作业的处理速度并不会下降。
B. TextInputFormat
TextInputFormat是默认的InputFormat,每条记录是一行输入。键是LongWritable类型,存储该行在整个文件中的字节偏移量;值是Text类型,存储该行的内容(不包括任何终止符:换行符或回车符)。例如,包含以下文本的文件将被切分为4条记录:
On the top of the Crumpetty Tree
The Quangle Wangle sat,
But his face you could not see,
On account of his Beaver Hat.
每条记录表示为以下的键/值对:
(0, On the top of the Crumpetty Tree)
(33, The Quangle Wangle sat,)
(57, But his face you could not see,)
(89, On account of his Beaver Hat.)
C. KeyValueTextInputFormat
通常情况下,文件中的每一行是一个键/值对,使用某个分界符(比如制表符)进行分隔。例如,Hadoop默认的OutputFormat(即,TextOutputFormat)产生的中间输出:
line1→On the top of the Crumpetty Treeline2→The Quangle Wangle sat,line3→But his face you could not see,line4→On account of his Beaver Hat.
经KeyValueTextInputFormat处理后转换为:
( line1,On the top of the Crumpetty Tree )
( line2,The Quangle Wangle sat )
( line3,But his face you could not see )( line4,On account of his Beaver Hat )
D. NLineInputFormat
使用TextInputFormat和KeyValueInputFormat,每个mapper收到的输入行数是不同。行数依赖于输入分片的大小和行的长度。如果希望mapper收到固定行数的输入,则使用NLineInputFormat。与TextInputFormat一样,键是LongWritable类型,存储该行在整个文件中的字节偏移量;值是Text类型,存储该行的内容。
N表示每个mapper收到的输入行数,默认值是1。以刚才的输入为例:
On the top of the Crumpetty TreeThe Quangle Wangle sat,But his face you could not see,On account of his Beaver Hat.
如果把N设置为2,则每个mapper收到两行记录,第一个mapper收到:
(0, On the top of the Crumpetty Tree)(33, The Quangle Wangle sat,)
第二个mapper收到:
(57, But his face you could not see,)(89, On account of his Beaver Hat.)
E. SequenceFileInputFormat
MapReduce不仅可以处理文本信息,还可以处理二进制格式的数据。Hadoop的顺序文件格式存储二进制的键/值对序列。如果用顺序文件数据作为MapReduce的输入,则使用SequenceFileInputFormat,键和值是由顺序文件决定。
SequenceFileInputFormat可以读MapFile和SequenceFile。如果在处理顺序文件时遇到目录,它会把目录当成MapFile并使用其数据文件。
该类有两个重要的子类:
<1>SequenceFileAsTextInputFormat:可以把顺序文件中的键和值转换为Text对象(调用toString方法实现转换)。
<2>SequenceFileAsBinaryInputFormat:把顺序文件的键和值转为二进制对象(BinaryWritable对象)。
F. 多种输入
默认情况下,所有文件都由一个InputFormat和同一个Mapper来解释。 一个MapReduce作业的输入可能包含多种格式的输入文件,需要多种InputFormat;而且数据格式往往会时间变化,需要另外编写mapper来处理应用中遗留的数据格式。为了解决这个问题,可以使用MultipleInputs类,调用如下方法:
<1>指定多种输入格式和多个Mapper的方法:
public static void addInputPath(JobConf conf, Path path,
Class<? extends InputFormat> inputFormatClass,
Class<? extends Mapper> mapperClass);
<2>如果有多种输入格式,而只有一个Mapper,则使用:
public static void addInputPath(JobConf conf, Path path,
Class<? extends InputFormat> inputFormatClass) ;
3. 输出格式
OutputFormat的类层次结构如下所示:
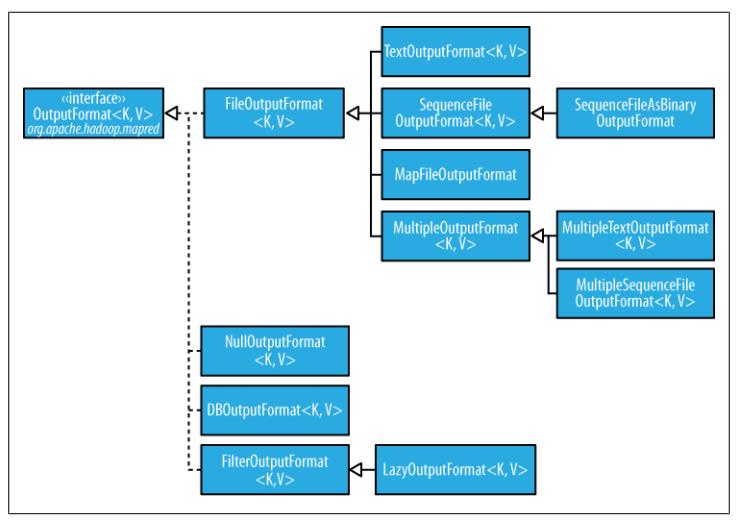
A. 文本输出
默认的输出格式是TextOutputFormat,它调用toString方法把每条记录转换成字符串,因此它的键和值可以是任意类型。键/值对由制表符分隔,也可以用mapred.textoutputformat.separator属性设置其他的分隔符(比如箭头 "—>")。与TextOutputFormat对应的输入格式是KeyValueTextInputFormat。另外,可以用NullWritable来省略输出的键或值。
B. 二进制输出
<1> SequenceFileOutputFormat:将它的输出写成一个顺序文件,这种输出格式紧凑,容易被压缩。
<2> SequenceFileAsBinaryOutputFormat:与SequenceFileAsBinaryInputFormat相对应,将键/值作为二进制格式写到SequenceFile容器中。
<3> MapFileOutputFormat:将输出写成MapFile。MapFile的键必须顺序添加,所以必须确保reducer输出的键已经排好序。
C. 多个输出
有时需要一个reducer输出多个文件,或者对输出的文件名进行控制,则使用MultipleOutputs类。
MultipleOutputs根据输出的key和value来命名文件。如果是map输出的文件,则文件命名格式为“name-m-nnnnn”;如果是reduce输出的文件,则命名格式为“name-r-nnnnn”。其中,“name”是由MapReduce程序决定的,“nnnnn”是part从0开始的整数编号。part编号确保从不同分区生成的文件名字不重复。
D. 延时输出
FileOutputFormat的子类可以输出空文件,但如果不想创建空文件,则可以使用LazyOutputFormat。它是一个封装输出格式,保证指定分区的第一条记录输出时才真正创建文件。















 2081
2081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









