






关注公众号,发现CV技术之美
本篇文章总结CVPR 2021 中的遥感与航拍影像处理识别相关论文,包含航空图像分割、检测,无人机检测,以及用于无人机的人类行为理解研究的数据集等等。共计 7 篇。
大家可以在:
https://openaccess.thecvf.com/CVPR2021?day=all
按照题目下载这些论文。
如果想要下载所有CVPR 2021论文,请点击这里:
数据集
UAV-Human: A Large Benchmark for Human Behavior Understanding with Unmanned Aerial Vehicles
UAVHuman 数据集,对无人机图像的人类行为进行理解解析,包含 67,428 个多模式视频序列和 119 个用于动作识别的目标,22,476 帧用于姿势估计,41,290 帧和 1,144个用于人员重识别的身份,以及 22,263 帧用于属性识别。它由一架飞行的无人机在三个月内的白天和夜晚在多个城市和农村地区收集的,因此涵盖了广泛的多样性,包括对象、背景、光照、天气、遮挡、相机运动和无人机飞行姿态。这样一个全面的、具有挑战性的基准将能够促进基于无人机的人类行为理解研究,包括动作识别、姿势估计、重识别和属性识别。
此外,该文还提出一种基于鱼眼的动作识别方法,该方法通过学习校正的 RGB 视频所引导的无界变换来减轻鱼眼视频的失真。实验结果也证明了该的方法在UAV-Human 数据集上的有效性。
作者 | Tianjiao Li, Jun Liu, Wei Zhang, Yun Ni, Wenqian Wang, Zhiheng Li
单位 | 新加坡科技设计大学;山东大学
论文 | https://arxiv.org/abs/2104.00946
代码 | https://github.com/SUTDCV/UAV-Human

无人机图像+检测+跟踪+计数
Detection, Tracking, and Counting Meets Drones in Crowds: A Benchmark
通过提出 STNNet 方法来共同解决无人机拍摄的拥挤场景中的密度图估计、定位和跟踪。值得注意的是,作者设计了相邻上下文损失来捕捉连续帧中相邻目标之间的关系,对定位和跟踪是有效的。为了更好地评估无人机的性能,作者还收集并标记了一个新的数据集:DroneCrowd。
作者称这是迄今为止最大的数据集,其中包含了用于密度图估计、人群定位和无人机跟踪的头部标注轨迹。并称希望这个数据集和提出的方法能够促进无人机上人群定位、跟踪和计数的研究和发展。
作者 | Longyin Wen, Dawei Du, Pengfei Zhu, Qinghua Hu, Qilong Wang, Liefeng Bo, Siwei Lyu
单位 | JD金融美国公司&纽约州立大学奥尔巴尼分校&天津大学
论文 | https://arxiv.org/abs/2105.02440
代码 | https://github.com/VisDrone/DroneCrowd

卫星图像+移动目标对齐
SIPSA-Net: Shift-Invariant Pan Sharpening with Moving Object Alignment for Satellite Imagery
韩国科学技术院学者提出一个新的框架:用于移动目标对齐的 shift-invariant pan-sharpening(SIPSA-Net),是第一个考虑到移动目标区域的这种大的错位来进行 pan-sharpened 方法。通过实验表明,与最先进的方法相比,SIPSA-Net 可以生成 pan-sharpened 图像,在视觉质量和对齐方面有显著的改善。
作者 | Jaehyup Lee, Soomin Seo, Munchurl Kim
单位 | 韩国科学技术院
论文 | https://arxiv.org/abs/2105.02400
代码 | https://github.com/brachiohyup/SIPSA

航空图像分割
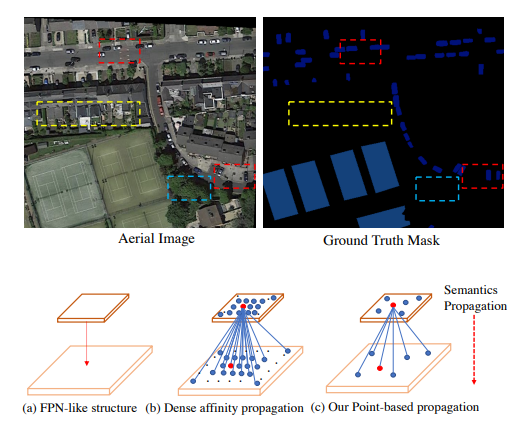
PointFlow: Flowing Semantics Through Points for Aerial Image Segmentation
航空图像分割是一个特殊的语义分割问题,具有一般语义分割所不具备的几个挑战性特点。其中有两个关键问题:前后景分布不均衡;复杂背景下的多个小物体。过度引入背景上下文使得模型性能下降。
针对上述问题,基于 FPN 提出 PointFlow,用 sparse affinity 替换 dense affinity,保持效率的同时还可以减少背景噪声。设计 dual point matcher 来匹配 salient 区域和 boundary 区域。
在三个不同的航空分割数据集上的实验结果表明,所提出的方法比最先进的一般语义分割方法更加有效和高效,并实现了最佳的速度和准确性的权衡,以及还证明了该方法的泛化性更好。
作者 | Xiangtai Li, Hao He, Xia Li, Duo Li, Guangliang Cheng, Jianping Shi, Lubin Weng, Yunhai Tong, Zhouchen Lin
单位 | 北大;中科院;国科大等
论文 | https://arxiv.org/abs/2103.06564
代码 | https://github.com/lxtGH/PFSegNets
航空影像检测
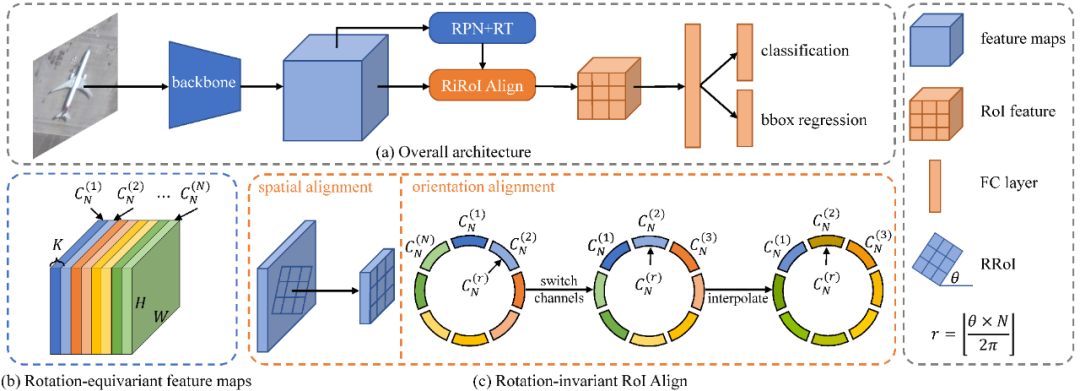
ReDet: A Rotation-equivariant Detector for Aerial Object Detection
ReDet,全称 Rotation-equivariant Detector,用于航空目标检测,可以明确编码 rotation equivariance 和 rotation invariance。具体来说,将 rotation-equivariant 网络纳入检测器中提取 rotation-equivariant 特征,可以准确预测方向,使模型尺寸大大减小。基于该特征,提出 Rotation-invariant RoI Align(RiRoI Align),它根据 RoI 的方向,从等值特征中自适应地提取 rotation-invariant 的特征。
在 DOTA-v1.0、DOTA-v1.5 和 HRSC2016 几个具有挑战性的航空图像数据集上进行的大量实验表明,所提出方法在航空目标检测任务上可以达到最先进的性能。与之前的 SOTA 相比,ReDet 在 DOTA-v1.0、DOTA-v1.5和HRSC2016 上分别获得了 1.2、3.5 和 2.6 的 mAP,同时减少了 60% 的参数数量(313 Mb vs. 121 Mb)。
作者 | Jiaming Han, Jian Ding, Nan Xue, Gui-Song Xia
单位 | 武汉大学
论文 | https://arxiv.org/abs/2103.07733
代码 | https://github.com/csuhan/ReDet
无人机检测
Dogfight: Detecting Drones from Drones Videos
本文试图从其他飞行无人机中解决检测无人机的问题。源和目标无人机的不稳定运动、小尺寸、任意形状、大强度变化和遮挡使得该任务具有相当的挑战性。在此情况下,基于 region-proposal 的方法无法很好捕获前景-背景信息。以及由于源无人机和目标无人机的尺寸极小且运动复杂,基于 feature aggregation 的方法也不能得到很好的效果。
为此,文章提出采用了 spatio-temporal attention cues 的 two-stage segmentation-based 方法。在第一阶段,鉴于重叠的帧区域,详细的上下文信息通过使用金字塔池的卷积特征图被捕获。之后,在特征图上执行像素和通道的注意力,以确保无人机的准确定位。在第二阶段,对第一阶段的检测进行验证,并探索新的可能的无人机位置。
作者 | Muhammad Waseem Ashraf, Waqas Sultani, Mubarak Shah
单位 | Information Technology University;中佛罗里达大学
论文 | https://arxiv.org/abs/2103.17242

多视角卫星摄影测量
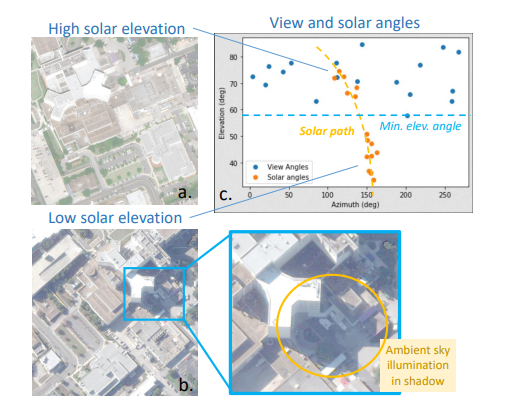
Shadow Neural Radiance Fields for Multi-view Satellite Photogrammetry
S-NeRF,全称 Shadow Neural Radiance Field,用于地球观测场景阴影感知的多视角卫星摄影测量,它遵循近期隐性的 volumetric 表征学习。对于每个场景,使用从已知视角拍摄的非常高的空间分辨率光学图像来训练 S-NeRF。这种学习不需要标签或形状先验:它是由图像重建损失自监督的。为了适应来自定向光源(太阳)和漫射光源(天空)的不断变化的光源条件,作者以两种方式对 NeRF 方法进行扩展。首先,来自太阳的直接光照是通过局部光源可见度场来模拟的。第二,来自漫射光源的间接照明被学习为一个非局部颜色场,作为太阳位置的函数。从数量上看,与 NeRF 相比,这些因素的结合减少了阴影区域的高度和颜色误差。S-NeRF 方法不仅可以进行新的视图合成和全三维形状估计,还可以进行阴影检测、反照率合成和瞬时物体过滤,而无需任何明确的形状监督。
作者 | Dawa Derksen, Dario Izzo
单位 | 欧洲航天局
论文 | https://arxiv.org/abs/2104.09877
- END -
编辑:CV君
转载请联系本公众号授权
入群????备注:遥感
















 2032
2032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









