







相关资料
论文:Learnable Prompt for Few-Shot Semantic Segmentation in Remote Sensing Domain
代码:https://github.com/SteveImmanuel/OEM-Few-Shot-Learnable-Prompt
摘要
小样本分割是一项任务,它要求在只有少量标注示例的情况下,对图像中新类别的对象或区域进行分割。在一般设置中,任务扩展到同时分割基础类别和新类别。主要挑战在于如何训练模型,以便新增新类别不会损害基础类别的性能,这也被称为灾难性遗忘。为了缓解这个问题,我们使用SegGPT作为我们的基线模型,并在基础类别上对其进行训练。然后,我们使用独立的可学习提示来处理每个新类别的预测。为了处理通常在遥感领域出现的多种对象大小,我们执行基于补丁的预测。为了解决补丁边界处的不连续性问题,我们提出了一种通过重新构建问题为图像修复任务的补丁和拼接技术。在推理过程中,我们还利用图像相似性搜索在图像嵌入上进行提示选择和新类别过滤,以减少误报预测。根据我们的实验,我们提出的方法将简单微调的SegGPT在小样本OpenEarthMap数据集的验证集上的加权mIoU从15.96提升到35.08。
引言
目前解决广义小样本分割问题的战略主要围绕两种方法:1)单独预测每个新类别,然后使用融合技术合并结果;2)重新学习分类器,使其能够同时预测基础类别和新类别。我们的方法遵循第一种方法,但与现有方法不同,我们只使用基础类别的数据对模型进行一次训练。对于新类别的分割,我们仅通过仅在支持集上训练获得的每个类别的提示。
我们选择这样做的原因是由于具有强大泛化能力的新型基础模型的出现。**每个新类别的提示作为适应层,以处理特定新类别的特征。**因此,我们的方法能够处理任意数量的新类别,而不会降低基础类别的性能。这种方法既简单直接,又高度适用于现实生活场景。此外,这项挑战呈现了遥感中常见的特点,尤其是变化的对象大小。
方法
训练

我们遵循图像掩码建模(MIM)方法,目标是重建输入图像的掩蔽区域。为此,模型接收一对图像而不是单个图像。提示图像 X p X^p Xp 和目标图像 X t X^t Xt,以及它们对应的语义图 Y p Y^p Yp 和 Y t Y^t Yt 被提供,其中语义图的某些补丁被掩蔽,如图1所示。所有 X p , X t , Y p , X^p, X^t, Y^p, Xp,Xt,Yp, 和 Y t Y^t Yt 需要具有相同的维度 H × W × 3 H \times W \times 3 H×W×3。因此,语义图通过使用颜色映射 M : R → R 3 M : \mathbb{R} \rightarrow \mathbb{R}^3 M:R→R3 将每个类别标签映射到颜色来转换到图像空间。对于每个数据样本,颜色是随机的。目的是迫使模型学习上下文信息以重建掩蔽区域,而不是利用颜色。这在小样本设置中特别有用,因为它防止了对基础类别的过拟合。
基础类别
基础类别遵循标准的MIM方法进行训练。每个数据样本包括 X p , X t , Y p , X^p, X^t, Y^p, Xp,Xt,Yp, 和 Y t Y^t Yt。为了选择 X p X^p Xp 和 X t X^t Xt,我们最初生成训练集中所有可能的图像对组合。然后,我们根据每张图像中出现的类别采用不同的掩蔽策略。如果 X p X^p Xp 和 X t X^t Xt 至少包含一个不同类别,我们随机掩蔽 Y p Y^p Yp 和 Y t Y^t Yt 的 α \alpha α 部分补丁,如图1a所示。或者,如果 X p X^p Xp 和 X t X^t Xt 包含完全相同的类别,我们掩蔽整个 Y t Y^t Yt ,如图1b所示。如果 X p X^p Xp 和 X t X^t Xt 包含相同类别,那么给定 Y p Y^p Yp,模型应该能够预测整个 Y t Y^t Yt。相反,如果它们的类别不同,模型应该通过利用未掩蔽区域的上下文信息来重建掩蔽的补丁。
新类别
由于样本数量有限,新类别不能以与基础类别相同的方式进行训练。SegGPT通过将 k k k 个样本作为分割上下文输入,具有强大的小样本能力。然而,正如我们在表1中所示,这仍然不足以应对这一挑战。小样本设置中的主要障碍是如何使模型能够在只有少量样本的情况下预测新类别,同时保持对基础类别的性能。
推理
推理与训练中的半掩蔽策略类似。图像
X
p
X^p
Xp 及其语义图
Y
p
Y^p
Yp 作为提示提供上下文信息。然后,给定目标图像
X
t
X^t
Xt,模型预测
Y
^
t
\hat{Y}^t
Y^t。我们生成一个固定的颜色映射
M
M
M 并使用它将
Y
p
Y^p
Yp 转换到图像空间,以及它的逆
M
−
1
M^{-1}
M−1 将预测
Y
^
t
\hat{Y}^t
Y^t 转换回类别标签空间。
Y
^
t
\hat{Y}^t
Y^t 中第
i
,
j
i,j
i,j 个像素的类别可以按如下方式确定:
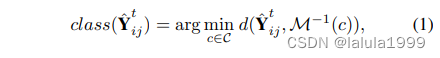
其中
c
c
c 在类别标签集合
C
C
C 上迭代,
d
d
d 是余弦相似度距离。图像相似性搜索。提示
X
p
X^p
Xp 和
Y
p
Y^p
Yp 的质量极大地影响预测结果
Y
^
t
\hat{Y}^t
Y^t。通常,
X
^
p
\hat{X}^p
X^p 和
X
^
t
\hat{X}^t
X^t 越相似,结果越好。此外,SegGPT可以结合多个提示以生成更准确的结果。我们利用CLIP-ViT [23]提取训练集中每个图像的嵌入。然后,我们使用余弦相似度检索与
X
t
X^t
Xt 最相似的前
l
l
l 个图像,并将其用作提示。
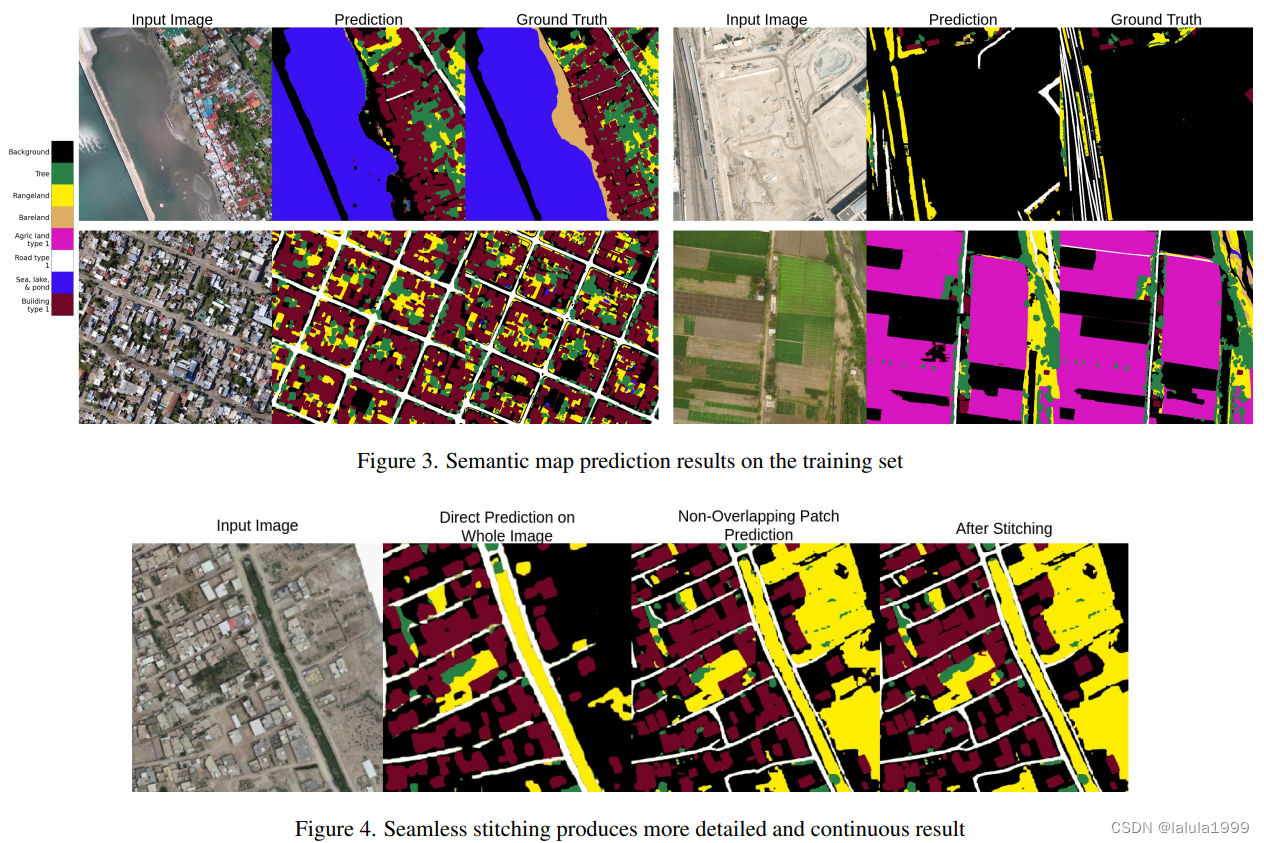
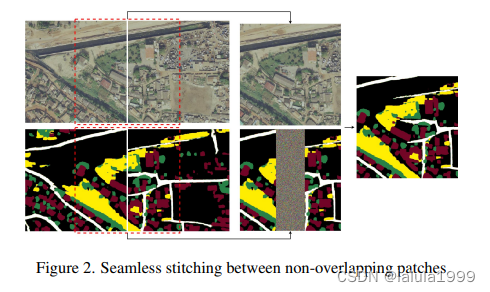
补丁和拼接。在遥感领域,对象通常较小且分散在图像中。直接处理整个图像通常会导致对象未被检测到。因此,我们将图像分割成2x2个相等的不重叠补丁,并独立地对这些补丁进行预测。要获得整个图像的结果,我们可以直接组合这些补丁上的预测结果。然而,补丁边缘可能会有一些不连续性导致的伪影(见图4第3列)。为了缓解这个问题,我们执行额外的预测,预测相邻补丁重叠的中间区域,如图2所示。我们不是预测整个重叠区域,而是仅专注于预测中间部分,而其余区域则使用来自非重叠补丁的先前预测填充,以提供更多上下文。这个过程有效地将任务构建为图像修复任务,实现了不重叠补丁预测的无缝集成。
要获得包含基础类别和新类别的最终预测,我们首先对基础类别进行预测。对于每个新类别,我们不使用图像相似性搜索来获取相似的图像作为提示,因为提示本质上被 Z Z Z 替换。相反,我们计算目标图像 X t X^t Xt 与给定的 k k k 个样本之间的相似性,类似地使用CLIP-ViT和余弦相似度距离。如果相似性不超过某个阈值,我们就完全跳过处理目标图像对应的新类别。这个想法是,如果 X t X^t Xt 与给定的 k k k 个样本不相似,那么它不太可能包含新类别。这种方法有助于进一步减少新类别的误报预测。随后,我们简单地将新类别的预测叠加在基础类别预测之上。

















 108
108

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









