






这篇文章适合哪些人
- 想了解旋转位置编码,但是很多都是晦涩难懂的公式定理。
- 了解ROPE原理,想找个代码,自己修改一些参数。
- 懂原理,懂代码,看看有没有什么更好玩的思路。
看文章之前,需要的前置条件
- 高等数学三件套学过,不一定要精通,不一定分数要很高,相比于只会背公式,自己有一些数学思维上的理解
- 懂得神经网络的原理,懂得embedding,token,维度,attention等知识
- 有一些空间想象力
- 准备好python解释器,pycharm,vscode等,无论你喜欢哪一种,需要的库只有torch,matplotlib
请确认以上步骤,确认完毕,可以开始阅读本篇文章。
免责声明:本篇文章仅供个人学习分享交流用,不代表权威级学术文献。
有一个字符串:
锄禾日当午,汗滴禾下土。谁知盘中餐,粒粒皆辛苦。算上标点符号一共24个字符
该字符串,经过tokenizer转换成一个token序列,又经过了embedding嵌入,接下来经过注意力机制层展开成Q,K,V。
以上是这个字符串经历的前期“艰难险阻”,之所以一笔带过,因为上面的那些并不在本文讨论范围内。
我们的字符串,被attention层展开成了Q,K,V。现在要对Q加入旋转位置编码。
到这里,应该会有人觉得:这前面乱七八糟的什么玩意。
别急,接下来开始。
因为省略了之前的过程(加载模型,加载词典,token转换,embedding嵌入,attention的QKV计算)
所以,现在用随机数创建一个形状相同的伪数据。这个矩阵代表了原字符串,经过Q展开后得到的结果矩阵,现在要对这个矩阵加入位置编码。(因为,embedding太吃配置了)
import torch
import numpy
from matplotlib import pyplot as plt
# 设置张量的形状和数据类型
shape = (24, 128)
dtype = torch.float16
# 生成张量
Q_data = torch.randn(*shape, dtype=dtype)
print(Q_data)于是我们得到了一个24*128的矩阵。
现在我们假设这个矩阵代表着之前的“锄禾日当午,汗滴....”经过embedding和注意力机制层的Q计算,得到的。
此处暂停了解一下位置编码
(砸瓦鲁多!)
绝对位置编码与相对位置编码
绝对位置编码和相对位置编码,思路和绝对路径与相对路径很相似
绝对位置编码
对于每个token指定一个编码。
['锄', '禾', '日', '当', '午', ',', '汗', '滴', '禾', '下', '土', '。', '谁', '知', '盘', '中', '餐', ',', '粒', '粒', '皆', '辛', '苦', '。']
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]对于transformer使用的sin函数,因为是周期变化,所以会出现如下的情况:

对于序列中不同位置的token,编码值相同的情况(y的值为编码的值,x轴为序列,可以理解为0为第一个字,1为第二个字.....),如果恰好这两个字,或者说这两个token是一样的,那么位置编码直接失效,在概率上,这种情况几率很小,但是,即使是百万分之一的可能性,在千亿万亿级的token下,这种错误甚至可以影响模型训练效果。
如果使用单调函数呢?
以下面一个最简单的单调函数为例,y=x

确实有对于每一个字都有其独一无二的编码了:第一个字位置编码为0,第二个字为1,第100个字为99......
但是出现了另一个问题,如果序列很长,编码要编到几万几十万,这个时候第一个字的位置编码0,与最后一个字的几十万。 在做归一化或者标准化的时候,小的值几乎可以被忽略,变成无效编码。 权重分布并不能很好的分布于整个字符串中。但是好处是,编码唯一,位置信息清晰。
相对位置编码
为了解决上面的问题的问题,出现了相对位置编码。 我们知道,相对路径是相对于某个文件夹的路径。 那么相对位置编码就是某个token相对其他token的位置编码。
将复杂模型简化一下,就是某个token相对于其他位置token的距离。 比如上面的字符串,“谁知盘中餐”的'谁'字,与'餐'字。其相对距离为4。
再递进一下,诗中有两个“禾”字,分别在第一句和第二句,如果以“日当午”的“午”字为参照。 那么第一个“禾”的位置编码为-3,第二个禾的位置编码为4。
注意:以上只是举简单的例子,并不是实际的算法,只是为了方便理解,简化的数学模型。
虽然相对位置编码解决了绝对位置编码的周期函数出现重复,单调函数出现权重分布问题。 但是相对位置编码也有劣势:因为要计算大量的相对位置信息,如每个token相对的欧式距离,曼哈顿距离,空间向量角度差值等。如果文本很长,计算量超级大。
(时间开始流动!)
旋转位置编码ROPE
回到旋转位置编码,刚刚我们的《悯农》,现在展开成了一个24*128的向量矩阵,24代表token数量,128代表embedding后经过attention的Q计算得到的信息。 为了方便理解,记住这是一个24行128列的数据,每一行代表一个token,128列就是它的数值型的特征信息。
旋转位置编码,用极坐标系表示向量位置的相对信息,如下图:

总的来说,就是这样的。
但是具体是如何实现的,下面开始代码实现。
在我们的Q_data的下面可以执行下述代码:
Q_data_token_split_into_pairs = Q_data.float().view(Q_data.shape[0], -1, 2)
print(Q_data_token_split_into_pairs.shape)
# 输出
# torch.Size([24, 64, 2])解释:Q_data是24*128的矩阵,现在将128个特征数值,两两成对,将数据形状变成三维。 Q_data.shpe应该是token数量24个, 将后面的两两成对,变成64*2的形状。
因为大学的线性代数基本都是以二维矩阵进行学习的。 为了方便理解,我们想象一下形状:24个64行2列的矩阵竖向排开。(动用想象力啊!!!)之所以不横向排开,是因为每一行是一条数据,每一列是特征。
这里带一下view()这个方法:修改矩阵的形状,里面的参数分别代表了维度,如果哪个维度设置为-1,代表着该维度自动适应其他维度。 在代码中,指定了第一维的值为24,也就是我们token的数量,指定了最后一维为2, 那么中间的第二维会自动调整数值排布,最终得到了(24,64,2)。 此时24依旧是24个token,原本的128列特征,两两组合。
(如果维度的形状想象确实很难,就该多熟悉一下了)
继续在下面增加代码:
zero_to_one_split_into_64_parts = torch.tensor(range(64))/64
print(zero_to_one_split_into_64_parts)
# 输出:
# tensor([0.0000, 0.0156, 0.0312, 0.0469, 0.0625, 0.0781, 0.0938, 0.1094, 0.1250,
0.1406, 0.1562, 0.1719, 0.1875, 0.2031, 0.2188, 0.2344, 0.2500, 0.2656,
0.2812, 0.2969, 0.3125, 0.3281, 0.3438, 0.3594, 0.3750, 0.3906, 0.4062,
0.4219, 0.4375, 0.4531, 0.4688, 0.4844, 0.5000, 0.5156, 0.5312, 0.5469,
0.5625, 0.5781, 0.5938, 0.6094, 0.6250, 0.6406, 0.6562, 0.6719, 0.6875,
0.7031, 0.7188, 0.7344, 0.7500, 0.7656, 0.7812, 0.7969, 0.8125, 0.8281,
0.8438, 0.8594, 0.8750, 0.8906, 0.9062, 0.9219, 0.9375, 0.9531, 0.9688,
0.9844])解释:代码没有复杂的方法。仅仅是创建一个从1数到64,再除以64,组成的一维张量。但是其作用为初始化旋转编码器,将编码器初始化一个绝对位置编码器。对24个token,每个token的64个特征值按照顺序编码。
rope_theta=100000
freqs = 1.0 / (rope_theta ** zero_to_one_split_into_64_parts)
print(freqs)
# 输出:
# tensor([1.0000e+00, 8.3536e-01, 6.9783e-01, 5.8294e-01, 4.8697e-01, 4.0679e-01,
3.3982e-01, 2.8387e-01, 2.3714e-01, 1.9810e-01, 1.6548e-01, 1.3824e-01,
1.1548e-01, 9.6466e-02, 8.0584e-02, 6.7317e-02, 5.6234e-02, 4.6976e-02,
3.9242e-02, 3.2781e-02, 2.7384e-02, 2.2876e-02, 1.9110e-02, 1.5963e-02,
1.3335e-02, 1.1140e-02, 9.3057e-03, 7.7737e-03, 6.4938e-03, 5.4247e-03,
4.5316e-03, 3.7855e-03, 3.1623e-03, 2.6416e-03, 2.2067e-03, 1.8434e-03,
1.5399e-03, 1.2864e-03, 1.0746e-03, 8.9769e-04, 7.4989e-04, 6.2643e-04,
5.2330e-04, 4.3714e-04, 3.6517e-04, 3.0505e-04, 2.5483e-04, 2.1288e-04,
1.7783e-04, 1.4855e-04, 1.2409e-04, 1.0366e-04, 8.6596e-05, 7.2339e-05,
6.0430e-05, 5.0481e-05, 4.2170e-05, 3.5227e-05, 2.9427e-05, 2.4582e-05,
2.0535e-05, 1.7154e-05, 1.4330e-05, 1.1971e-05])解释:**代表平方应该没什么需要解释的,但是这个theta关系到ROPE编码器的频率,也就是变量值freqs。当然,有的人叫它旋转角度。其实如果以周期函数来看,角度和频率实际上是相互影响的因素,具体理解都可以,就像数学问题,有的人对数字公式敏感,有的人对图形敏感,理解的角度看个人喜好。
这个频率 ,可以想象一下,自行车轮的车条,车条越多,对应着频率越大,频率越大,车条与车条之间的夹角越小。

你甚至可以带入一下三角函数的频率,如果你了解一些傅里叶变换,那就太轻松了。
该步执行的操作为旋转位置编码器的编码频率。 该步执行计算的时候是对每一个数值进行计算,先对第一个数,求theta的该数次方,再做倒数,然后是第二个数,求theta的该数次方,再做倒数.....直到64个数都算完,得到更新后形状为:1行64列的张量矩阵。
接下来就是重要的部分了,从前你的数学老师可能说过:“请注意同学们,我要变形啦!” 其实也差不多,因为咱们的位置编码器要开始旋转了
freqs_for_each_token = torch.outer(torch.arange(24), freqs)
freqs_cis = torch.polar(torch.ones_like(freqs_for_each_token), freqs_for_each_token)
print('---------------freqs_cis.shape------------')
print(freqs_cis.shape)
# 输出:
# torch.Size([24, 64])解释: 先看torch.outer()这个方法执行的计算,做外积,如果用大学学的线性代数,还记得A矩阵乘以B矩阵,A矩阵横向每个元素,乘以B矩阵竖向每个元素,然后相加,得到新的矩阵C的第一行第一列的元素,然后A矩阵第二行,B矩阵第一列,再然后A矩阵第三行,B矩阵第一列。(不知道行不行得通,如果我没解释通,可以查一下这个计算方法,如果学过线性代数,这个计算并不是很复杂,几乎和主副对角线一样属于基础知识。)
作用的话,还记得咱们的24个字符,也就是24个token吗?
咱们把旋转位置编码器的频率应用到每一个token上。再联想一下外积的计算, 还记得3*4的二维矩阵,乘以4*3的二维矩阵,得到的是什么形状的吗?
是4*4的矩阵。
也就是说,这种外积的方式可以重新定义矩阵的形状。 注意要提一下,torch.outer外积,会自动做转置,因此在torch.outer()时候,实际上计算的是1行24列的矩阵,乘以64行一列的矩阵。得到的是24*64的矩阵,这个矩阵将旋转位置编码器的频率应用到每一个token上。
接下来这个torch.polar()比较重要,相当于核心部分。在说这个之前让咱们回忆一下极坐标系和复数
极坐标系、复数
我想起:大学时代,我的高数老师,在讲台上,对着下面一脸懵逼的我们,讲述高斯公式........

如上所示是球坐标系.......
还是太复杂了,我们不使用这玩意讲。 我只是单纯怀念一下高数老师,毕竟是个大美女。
用平面的极坐标系。
平面的极坐标系如下:

加上加上公式:
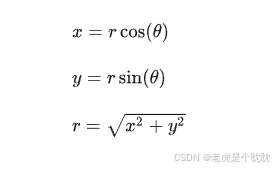
复数:
![]()
极坐标系和复数都回忆起来了,那么再加一个重要的概念:
极坐标是有复数形式的!
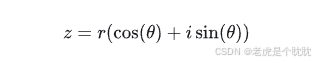
其中:
![]() ,是z这个极坐标数据的实部
,是z这个极坐标数据的实部
![]() ,是z这个极坐标数据的虚部
,是z这个极坐标数据的虚部
俗话说的好,如果想让某件事变得有逼格,或者提升某个人的逼格,只需要把一个有逼格的人或事扯进来。比如诸位跟朋友聊天的时候说:“我跟埃隆·马斯克一起吃过饭。”,这句话说出来是不是觉得自己气质唰唰上涨。
因此,咱们把这个文章变得有逼格一些。

著名的欧拉公式!上帝的公式!
欧拉欧拉欧拉欧拉!

暂时先知道这些足矣,总之目前只是提升逼格。
torch.polar 是 PyTorch 中的一个函数,用于将极坐标形式的实数转换为复数。它接受两个输入,一个是幅值 (magnitude),另一个是相位角度 (angle),并将其转换为对应的复数表示。
其中,幅值就是极坐标圆的半径r,相位角度就是θ。
因此,回到代码中
freqs_cis = torch.polar(torch.ones_like(freqs_for_each_token), freqs_for_each_token)
torch.ones_like(freqs_for_each_token):创建一个形状为24*64值都为1的矩阵,这个矩阵中每一个元素都为1,并且每一个1都是幅值,也就是极坐标半径r。
freqs_for_each_token:每个token的位置编码,形状也是24*64,每一个元素都是相位角θ。
使用torch.polar()将原本的笛卡尔坐标(平面直角坐标系)数据转换为复数表示的极坐标,x的值为实部,y的值为虚部。计算方法为两个矩阵对应位置元素一一计算,得到形状不变,但是转换成复数表示的极坐标。
对于圆,或者某些抽象形状的方程,其在笛卡尔坐标系下的计算,非常繁琐,但是如果转换成极坐标系下,会简化很多。并且由于ROPE是以相对位置的角度去衡量位置信息的,因此极坐标下会更方便
加个分割线,喘口气,记得喝水,上厕所,活动活动腰。
完成了笛卡尔坐标系到复数复数表示的极坐标系的转换,接下来看一下旋转成了什么样。
# freqs_cis一共24个token,可以自行查看任意token的位置编码形状,这里查看第二条
value = freqs_cis[2]
# 瞄一眼是不是还是64列的,每个token原本128列特征,两两成对,变成了64个
print(value.shape)
# 下面都是画图啦
plt.figure()
for i, element in enumerate(value):
plt.plot([0, element.real], [0, element.imag], color='blue', linewidth=1, label=f"Index: {i}")
plt.annotate(f"{i}", xy=(element.real, element.imag), color='red')
plt.xlabel('Real')
plt.ylabel('Imaginary')
plt.title('Plot of one row of freqs_cis')
plt.show()freqs_cis一共24个token,可以自行查看任意token的位置编码形状,这里查看第二条。当然你可以查看任意一条(注意别超过索引),你会发现每个旋转位置编码都是不一样的。
第二个token:

第7个token:

第20个token:

(很好的图像,使我脑筋旋转)
实际上旋转位置编码,并不局限于360度。
这里是一个token的特征,图里的1,2,3,4代表的可不是token!而是每个token的128个特征!
接下来,我们要操作之前的数据,那个将原本128个特征两两组成一对的数据,因为它还在笛卡尔坐标系呆着呢,把它也拉进复数表示的极坐标系里:
q_per_token_as_complex_numbers = torch.view_as_complex(Q_data_token_split_into_pairs)
print(q_per_token_as_complex_numbers.shape)
# 看看是不是变成复数表示了
print(q_per_token_as_complex_numbers[:2])
# 输出
# torch.Size([24, 64])
# tensor([[ 8.4033e-01-0.5352j, 7.5635e-01-0.8086j, -2.2051e+00-0.1042j,
7.6465e-01+0.9790j, -5.6006e-01+0.2360j, -1.6738e+00+1.5381j,
4.8779e-01-0.9370j, 5.2490e-01+0.8340j, -5.8252e-01-1.3594j,
1.2334e+00+0.7598j, 1.1758e+00-1.2100j, -1.3604e+00+0.1980j,
9.9219e-01-0.6567j, 1.0840e+00+0.6353j, 3.9624e-01+1.6318j,
1.8835e-01-0.7803j, 2.4316e+00+1.2529j, 1.1436e+00+0.4734j,
-4.8071e-01+1.4482j, -7.8955e-01-0.5664j, 9.6436e-01+0.1118j,
-4.6313e-01-0.0660j, 8.0078e-01-2.4941j, -9.2822e-01+1.6299j,
1.3564e+00+0.2128j, -1.3789e+00+1.2432j, -1.4023e+00-0.5620j,
8.1396e-01+0.3223j, -2.0020e-01+0.8179j, -3.9093e-02+0.0687j,
1.0010e+00+0.5586j, -1.1416e+00-0.7358j, -1.5210e-01-1.2158j,
-1.9577e-02+1.2832j, 2.0105e-01+0.3049j, -8.4033e-01+0.5078j,
-2.2461e-01+0.1131j, -1.1465e+00-1.7549j, -7.0679e-02-0.6680j,
-6.0254e-01+0.2252j, -8.9746e-01+2.1523j, -6.9531e-01-0.1771j,
-8.6719e-01-0.2250j, -7.1729e-01-0.2612j, -1.1816e+00-1.7197j,
-4.1309e-01-2.0215j, -1.7930e+00+0.7661j, -1.1250e+00-1.2109j,
1.1670e+00-0.2529j, 1.8350e+00-1.1719j, 2.2168e+00+0.1423j,
2.4207e-01-1.2451j, 4.0576e-01+2.0527j, -9.0723e-01+1.0469j,
5.9180e-01+0.3054j, 2.9861e-02-0.3245j, 5.4395e-01-0.6597j,
1.1709e+00-1.1553j, -4.6777e-01+0.6006j, 1.6748e+00+0.2004j,
4.9927e-01+0.6426j, 2.5131e-02+0.5645j, 1.0830e+00-0.9004j,
-1.0156e+00-0.3218j],
[ 8.5400e-01+0.4685j, -1.5784e-01+0.2203j, 3.8965e-01+0.0899j,
-8.1104e-01-0.5283j, 3.3862e-01-1.7051j, 2.1118e-01-1.0996j,
-1.0358e-01+0.9136j, 6.3574e-01-0.1190j, -1.3262e+00+0.3823j,
-7.0117e-01+1.4189j, 6.7578e-01-0.4006j, -1.5771e+00-0.0767j,
-6.4795e-01+0.5723j, 5.9326e-01-0.4492j, -2.5220e-01+0.8530j,
1.6541e-01+2.4902j, 1.0361e+00+0.7490j, 5.7861e-01-1.6211j,
1.1436e+00+0.4060j, -8.9893e-01-0.2900j, 1.3193e+00+0.6182j,
1.6641e+00-0.3523j, -6.7480e-01-0.3738j, -3.0746e-02+0.0276j,
3.0566e-01-0.5913j, 1.9229e+00+0.3086j, -3.5400e-01+0.0959j,
8.9722e-02+0.3511j, -7.8906e-01+1.0732j, -1.8994e+00+0.2076j,
-1.2002e+00+0.5850j, 4.8218e-01+0.5396j, -9.2578e-01-1.0576j,
-6.1914e-01+0.0041j, -8.2861e-01+1.4404j, -3.6890e-01+0.3245j,
-8.7061e-01-1.8770j, -1.2178e+00+0.4463j, -4.4507e-01+0.2273j,
8.6084e-01+0.5371j, 3.8135e-01+0.7002j, -1.7715e+00+0.6372j,
2.1716e-01+1.1045j, -4.1138e-01+0.5078j, 2.0488e+00+0.1304j,
9.3848e-01+0.9727j, -5.2393e-01+0.5859j, -2.7246e+00-1.1123j,
-7.9932e-01+0.9717j, -4.0967e-01-0.5425j, 1.2910e+00-1.2305j,
-6.0205e-01-0.4749j, -1.2637e+00+2.1914j, 3.3569e-01+0.8467j,
1.4961e+00-0.0638j, 4.4159e-02+0.6558j, -2.4941e+00+0.3494j,
1.8906e+00+1.7568j, -1.9763e-01+0.2054j, -1.2500e+00-1.8633j,
-3.0039e+00-0.1576j, 7.4219e-01-0.9375j, -1.3438e+00-0.0651j,
1.2093e-03-0.7271j]])有了旋转位置编码的数据,有特征两两成对的数据,因为他们的形状完全一样,都是24*64的。现在,我们要将旋转位置编码加入到两两成对的数据里面:
q_per_token_as_complex_numbers_rotated = q_per_token_as_complex_numbers * freqs_cis
print(q_per_token_as_complex_numbers_rotated.shape)
# 输出
# torch.Size([24, 64])q_per_token_as_complex_numbers * freqs_cis :有关于两个由复数组成的向量矩阵,他们直接做相乘,就是对应位置相乘,(a+bi)*(c+di),这个不需要解释吧,高考好像都考吧。
这两个矩阵在极坐标空间完成了位置编码与原Q的融合,成为了带有位置编码的Q。
再将这个数据转换回笛卡尔坐标系(还记得原始数据是啥不,“锄禾日当午.....”)
q_per_token_split_into_pairs_rotated = torch.view_as_real(q_per_token_as_complex_numbers_rotated)
print(q_per_token_split_into_pairs_rotated.shape)
# 偷瞄一眼是不是转换回了笛卡尔坐标系,而不是实部虚部的复数表示
print(q_per_token_split_into_pairs_rotated[:2])
# 输出(太长了,截一部分吧)
# torch.Size([24, 64, 2])
tensor([[[-2.1606e-01, -1.9788e-01],
[ 9.9268e-01, 1.0869e+00],
[-1.2598e+00, -9.5154e-02],
[ 1.0322e+00, 8.3154e-01],
[-2.3594e+00, -8.3789e-01],
[-1.0195e+00, 1.5645e+00],
....略....看上面输出的结果,又变成了最初的 24个token,每个token拥有64个特征对。
现在只需要将其变回原本的样子------->24个token,每个token拥有128个特征
q_per_token_rotated = q_per_token_split_into_pairs_rotated.view(Q_data.shape)
print(q_per_token_rotated.shape)
# 输出
# torch.Size([24, 128])至此,对于attention的Q的矩阵,增加旋转位置编码结束,当然也只是Q的。而K的矩阵增加位置编码,与Q的只有一点细微的差别,要考虑注意力的头权重共享。毕竟本文没写attention的计算过程,K的旋转位置编码就不做了。
总之,用Q矩阵增加位置编码,去理解旋转位置编码的原理以及过程。
当然,最终的旋转位置编码的应用,也要将K矩阵融合旋转位置编码,再将Q和K做内积。
本篇只分析计算方法部分,完全理解旋转位置编码,必须要深刻理解attention的计算,因为QK做点积后,会变换成相对位置。 其编码与QK的值还有token之间的位置距离有关。
接下来是一个有意思的“巧合”
傅里叶变换
我想起:大学时代,复变函数与积分变换的老师,对着一脸蒙逼的我们,手舞足蹈的将傅里叶变换与傅里叶逆变换,他一脑袋汗,我们也一脑袋汗,他怕我们听不懂,很急,然而我们真听不懂,也很急.........

傅里叶变换

傅里叶逆变换
之所以想起了复变老师,并不是复变的老师也是大美女,只是这玩意太抽象啦,我当时恨傅里叶恨得牙痒痒,我怀疑他的出现就是为了挂大学生的。
然而,当抽象到一定程度,这个东西就变成了艺术,不是说看不懂就觉得艺术成分很高,而是说当看懂了才觉得这玩意是艺术。推荐一个傅里叶级数的文章,这个老兄对傅立叶解读,简直帅得掉渣:
Heinrich:傅里叶分析之掐死教程(完整版)更新于2014.06.06
抛开什么周期性函数的傅里叶展开,抛开时域连续信号转换为频域分析(当然了,在图像领域,频域变化可以捕捉到图像变化特征,变化强烈的地方一般代表着图像中更强烈的信息,比如脸部边缘轮廓,稍微挪一点窗口位置,变化就剧烈了,通俗点就是类似于卷积的特征提取)
思路收回来,对于傅里叶级数的问题,不涉及复杂的公式,只想展示一个图

对于上图,极坐标系的圆,转换为三角函数。 有没有觉得这就是sin函数。绕来绕去,这玩意还是绝对位置编码???
实际上,sin函数是有频率的,并且频率是固定的。而在我们上面的旋转位置编码,频率并不固定,因此,可以想象旋转位置编码,在上图的左边即使是一个规整的圆,由于运动频率不同(或者说采样频率不同),而右边也不会是普通的sin函数曲线。
甚至每两个相邻的“车条”夹角都不一样。
看到这,如果能理解,可以尝试加入一些自己的想法
比如:
freqs_cis = torch.polar(torch.ones_like(freqs_for_each_token), freqs_for_each_token) 使用的是幅值(圆半径)为1的,如果修改成其他的会不会有不一样的效果,因为向量除了方向,也有大小。也有可能单纯只跟角度有关,具体可以试一下简单的变换,如根据实部虚部做个勾股定理.。
具体怎么玩,反正试验一下又不会使电脑爆炸。
如果有时间随缘更新(其实就是写这篇文章的人脑子不灵光,还没完全整明白)
先写到这。
下一篇会写K的位置编码计算,实际上与Q几乎一模一样,细微差别在注意力机制那里,是很小的差距。
因为对K向量加入位置编码几乎与Q没差别,因此下一篇会着重注意力机制部分计算,但核心依旧是将RoPE原理。
对下一篇抱有兴趣的可以做一下准备工作:
- 注意力机制的计算,重点是QKV的理解,实际上只要会查字典就可以,我是说数据类型那个字典,json!
- 实在等不及的,可以看一下下面的那个代码参考的链接。
- 对于共轭,旋转的问题,请看下面的文章参考,作者给出了很好的思路
- 了解一下内积外积,对向量的几何意义。
-
代码参考:
GitHub - naklecha/llama3-from-scratch: llama3 implementation one matrix multiplication at a time (大佬带你手撕llama3)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









