







图像生成模型原理简析
你有没有好奇过,AI图像生成模型是怎么学会“绘画”的吗?人工智能(Artificial Iitelligence)这个概念是在1956年的达特矛斯会议上提出来的认为机器可以模仿人类的学习以及其他方面的智能,后世也将实现人工智能的方式统称为机器学习,我们将提供数据、引导机器学习的过程成为模型的训练(Train)训练的结果是得到了一系列让AI可以表现得更好地“知识”,也就是模型(Models)。而后续运用模型解决问题的过程就叫做推理(Inference)。
在AI绘画这个领域,我们塞给AI的学习资料就是研究者们通过互联网抓取下来的海量图片,这些图片连同用于描述他们的文字信息构成了用来学习的数据集(Dataset)。这下我们应该就能理解了:当我们通过提示词告诉模型一个想要画的东西时,AI就可以很轻松的从它那庞大的“知识储备”里找到对应的图片,再将里面的东西组合在一起一副“AI生成”的画作就诞生了,是这样的吗?当然不是,这样通过提示词匹配再将图片拼在一起的事情我们大多数人都能做,哪用得着AI。
言归正传,数据量所存储的其实不是这些图片本身,而是图片里蕴含的“像素分布规律”,我们在电脑屏幕上的每一张图片,其实都是由不同颜色的像素点构成的,每个像素点可以用红、绿、蓝三种颜色的色值(R/G/B)表示

像素分布规律就是解释这些不同颜色的点是如何排列组合形成各种事物的,这种事情在人类的世界里并不常见,去“认识”一个东西似乎是我们与生俱来的天赋。像现在,让人类来做一道连线题,把这些图片和它们对应的含义匹配到一起,你不用想就可以做出来对吧?

但对AI来说并不容易,因为在它的世界里,这些图片长这样,一堆像素数据的排列组合。

那只能靠猜了吗?事实上AI最开始确实就是靠猜的,但我们会通过学习算法的设计,引导它记住那些正确的选择,这个过程重复成千、上万甚至数亿次,
它就会在不断的试错中变得越来越“聪明”,从而总结出各种形象对应的像素分布规律。
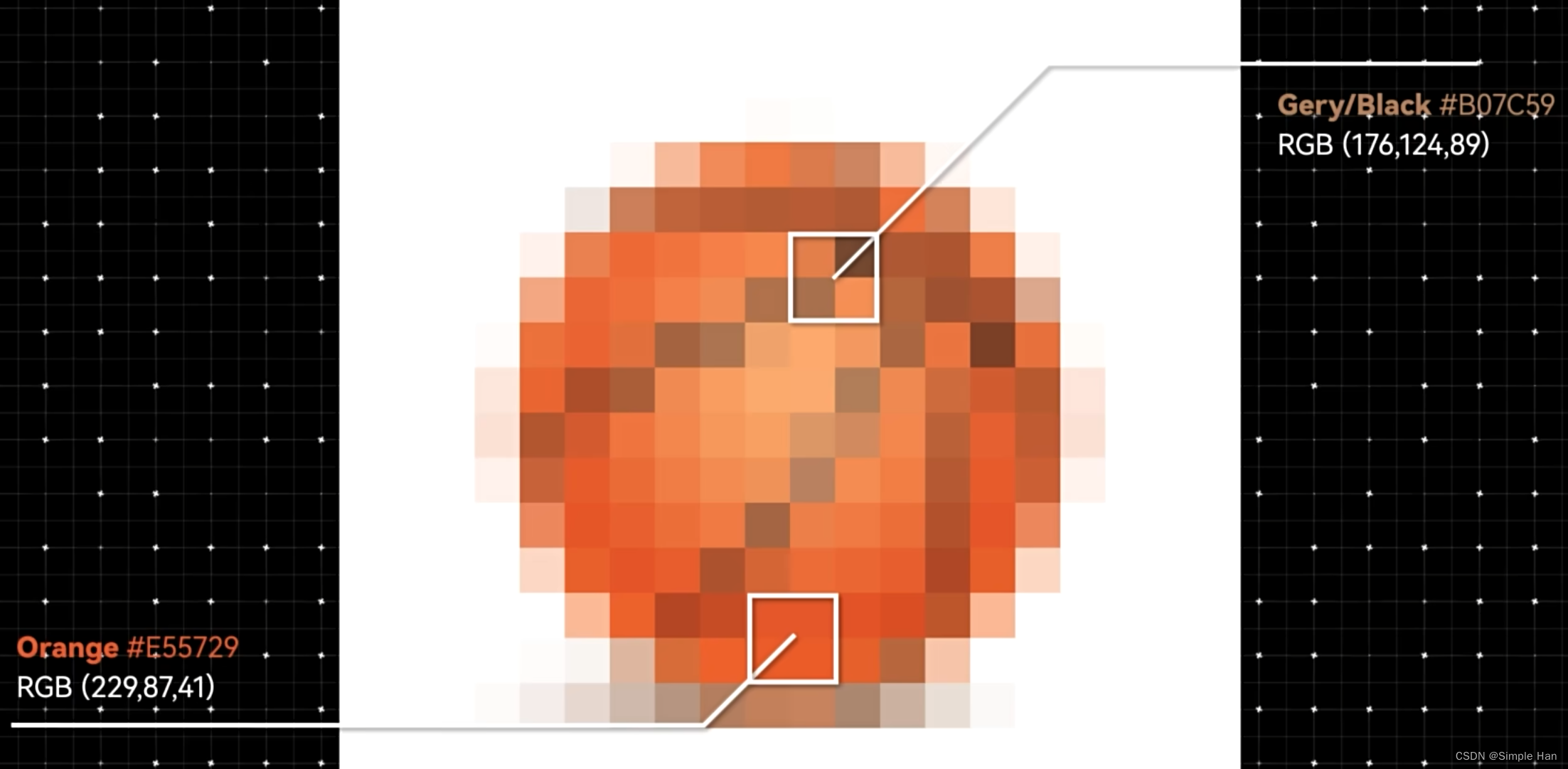
例如篮球,大概就是一堆代表橙色的像素数据汇聚成一个圆形,中间夹杂着一些黑色的点排列成线条
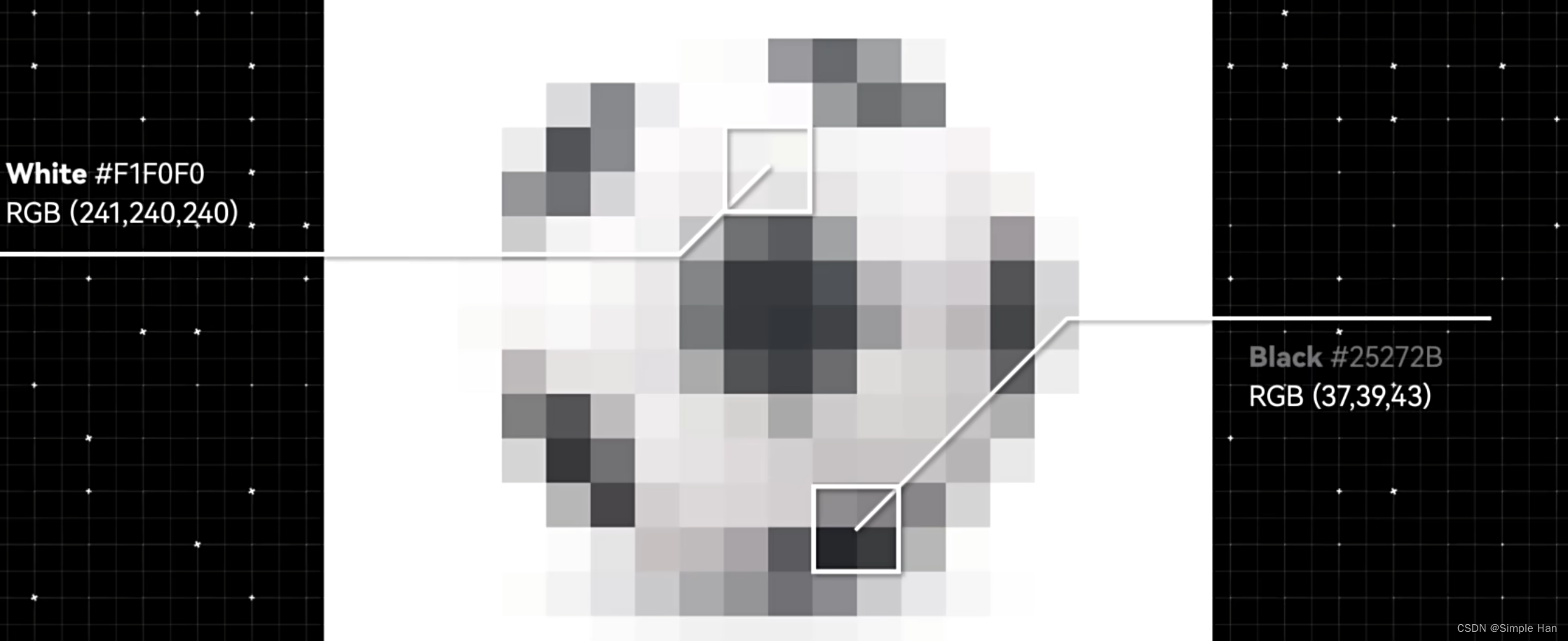
而足球,则是一个白色的圆形,中间有黑色的点聚集成大块的正五边形
这也是计算机视觉的“本质”,这些规律会被通过一些数学的手段转换为一种叫做嵌入向量(Vector Embeddings)的东西存储在模型里,它的本质是一串很长的数字序列,每个数字对应一个维度(Dimensions),用于描述某一种向量空间里的“特征”
在初中课本里,向量指一个同时具有大小和方向的量,不同的“规律”输入进来会变成不同的向量纸箱这个平面里的各个角落
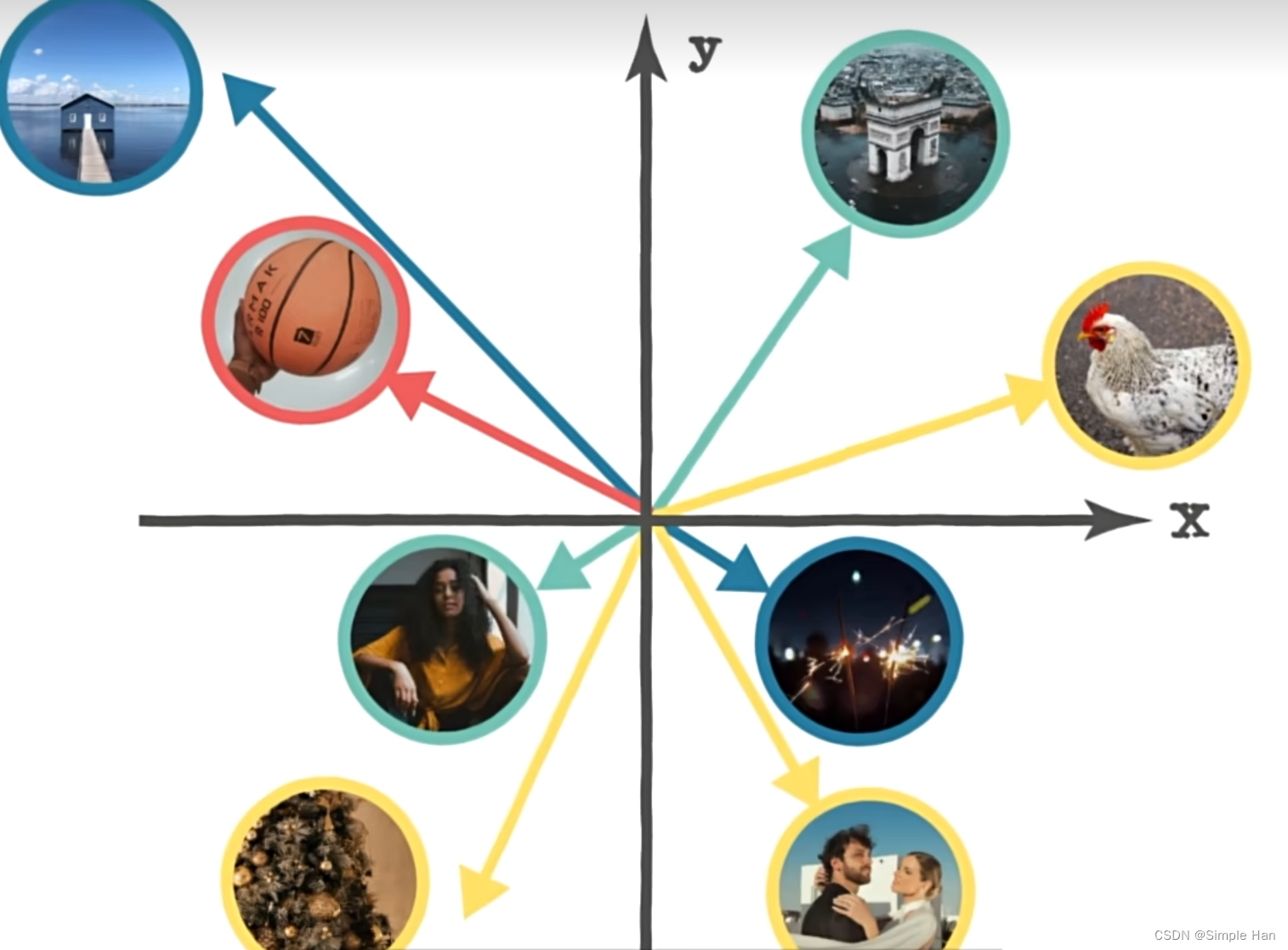
那如何让模型生成一只会打篮球的鸡呢(a chicken playing basketball)?它在做的事情就是将这个提示词(prompt)里的各种描述信息也转换成了一个个向量

然后和训练时掌握的各种规律一一对号入座。如上图所示,假如红色向量代表篮球,黄色向量代表鸡,那将它们合并在一起就会产生一个新的向量,代表我们想要去绘制的一个东西,接着我们就可以通过模型里的一些其他功能把它倒过来“变回”一张符合描述的图片了。
这只是一个最简单的“比喻”,因为二维空间里的向量只记录了两个数值,而机器学习里往往有成百上千个维度,对于我们人类而言非常难以理解的。每个数值也不一定拥有像大小、方向一样的非常确切的含义,但在使用了一些手段将其可视化以后,我们可以看到类似的“聚集性”特征,
也就是代表相似规律的向量总是接近的,和我们在平面上展示的是一样的,这和我们的模型训练又有什么关系呢?
SD模型结构拆解
现在回到Stable Diffusion来看看这个平时用来出图作画的模型是怎么工作的吧,在大家最常用的Stable Diffusion WebUI里要指挥AI绘制一张图片,我们的所有操作可以总结为一套固定流程:
1、选一个风格合适的模型 -> 2、输入一段描述画面的提示词 -> 3、调节一系列的绘制参数 -> 4、点击生成,OK图就会画出来了

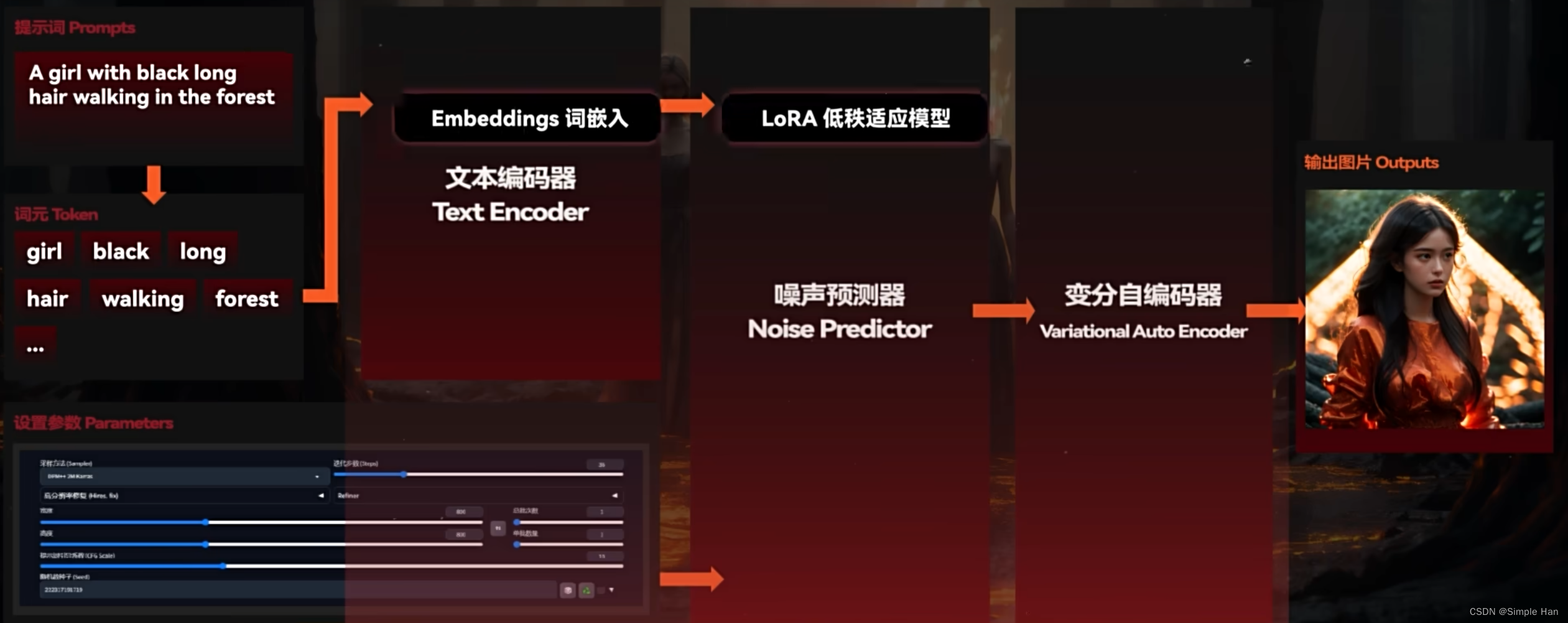
但如果我们掀开WebUI这层“表皮”,下面真实的一个模型工作逻辑是这样的
首先AI会将一大串提示词分解成一个个独立的Token,它可以翻译成“词元”,代表机器学习里的一个最小语义单位,然后我们会使用一个叫做文本编码器(Text Encoder)的东西,将每个Token对应的含义都转换成一组拥有768个维度的词元向量Token Embeddings,它们通过一定的方式“加总”在一起就得到了我们绘制一张新图片所需要的“规律”,与此同时我们输入的参数会进入一个噪声预测器(Noise Predictor)设定好它在生成过程中的工作方式,比如要进行多少步的生成、以什么方式生成并确定这张图片的尺寸、比例一类的初始属性,准备完毕以后Stable Diffusion会经由(设置参数里的)随机种子(Random Seed)计算出一张初始噪声图,然后噪声预测器就会在文本编码器(输出的词元向量)的指导下一步步地“扩散”(也就是去除)上面的噪声,并为图片添加上某些形象,经过了若干次循环以后图片上的大概形象就会显现出来了,在生成环节的最后,我们还需要通过一个变分自编码器也就是VAE(Variational Auto Encoder)把它从“向量形态”转换为我们的肉眼可以分辨的正常图片,OK一张图就被画出来了,现在你了解Stable Diffusion真正的工作原理了吗?如果你理解的差不多了就在下方点个赞吧 ~

那我们的模型跑哪里去了呢?如上图所示其实这里面的“文本编码器”和“噪声预测器”以及最后的“VAE”就是3个可以去训练的人工神经网络(也就是一种机器学习模型),它们受到的“教育”,就决定了我们最后生成出来的图片是什么样的,换一个不同风格的大模型,这几个部分都会发生改变,因而能在完全一致的提示词和参数下产出完全不同的结果。
而一些诸如Embeddings、loRA之类的“小模型”在发挥作用的时候也会像挂件一样挂在这些结构上,部分的修改里面的东西,所以stable diffusion的模型训练落实到操作层面其实就是在训练文本编码器和噪声预测器。
关于微调训练
在上方我们梳理了很多关于模型的技术细节,但有一个很重要的点还没讨论-训练模型用的数据集,Stable Diffusion这么厉害,它用了一些什么样的图片来训练呢?以公开的Stable Diffusion 1.1版本为例,官方的说明是使用了当时世界上最大规模的多模态图文数据集LAION-2B(里面这个B代表Billion即十亿)来训练。
没错,这是一个包含了约23.2亿对图片和对应文本描述的庞大数据集,而官方在这个基础上训练了超过40万步,后面的每一个版本都追加了更多更高质量的图片来进行优化,像目前传播度最广的SD1.5版本模型训练集规模应该在50亿张以上(LAION-5B),这样一个庞大的数据集训练起来的“成本”自然也是非常高的,根据消息stable diffusion团队使用了大约256块英伟达A100 GPU训练了将近12万小时(GPU*时)换算成算力市场里的行价大约是60万美元(人民币400多万),那么我们要学习的“模型训练”是要在自己家里的电脑上手搓一个“百万”级别的大工程吗?当然不可能了,事实上目前AI绘画领域讨论的所有“模型训练”其实都不是从零开始的,而是在这些官方已经花费大成本、大力气训练好又开源出来的模型上做的“二次加工”,这种“二创”有一个更为严谨的称呼叫对模型的微调(Fine-Tuning)做出来的模型就是所谓的微调模型(Fine-tuned Model),而为它们提供了微调基础的这个价值百万的原版开源模型一般被成为预训练模型(Pre-Trained Model),其实也很好理解,如果我们把模型比喻成一个人那这些开源大模型的公司预先帮我们做好了12年义务教育, 到我们手里的已经是一个大学新生了,我们只需要再做一点微小的工作帮他选个专业、安排点必修课它就能毕业出来工作了。也正是因为如此,我们的工作量就减轻了很多,训练也就变成了个人电脑上也能完成的工作了,而我们常常提到的Stable Diffusion模型的版本像刚刚提到的1.1~1.5后面的2.0、2.1以及XL其实指的都是这些由官方提供的预训练模型版本,在微调的时候模型训练者可以选择不同版本的预训练模型作为基底模型(Base Model),也就是微调的起点,当然你不光可以选择官方的模型作底模,也可以选择别人已经微调好的模型来做“三次加工”。
主流模型微调手段
目前开源社区已经涌现出了很多种正对stable diffusion模型做微调的方式(没错,这些方式是各路开发者自行摸索出来的),例如最早的审美梯度(Aesthetic Gradient)由NoveIAI的开发者提供的超网络(Hypernetwork)等,不同的微调方式在原理上作用的部分不一样自然会有效果上的差异。
一些效果没那么好或者是已经被后面的新方法给完美取代掉了的微调手法现在已经没有什么人用了,比如刚刚介绍的Aesthetic Gradient、Hypernetwork。从目前的模型市场现状来看,在今天仍然能发挥比较大作用的主流的微调训练方法一共有三种
| 微调方法 | Dreambooth(梦想亭) | LoRA(低秩适应模型) | Textual Inversion(文本反演) |
| 输出 | Checkpoint大模型 | LoRA | Embeddings |
| 模型大小 | 2~7 GB | 10~144 MB | < 1MB |
| 训练时长 | 非常长(数小时以上) | 非常短(几分钟至几十分钟) | 中等 |
| 训练集要求 | 较高 | 较低 | 非常低 |
| 配置要求(显存) | > 12 GB | > 8 GB | > 10 GB |
| 训练集效果 | 最好的 | 较好 | 一般 |
| 综合推荐指数 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| 说明 | 直接对包括文本编码器到噪声预测器的一个整体来做微调的,但调出来的模型理论上能容纳更多新东西,一般用于制作各种风格化的大模型 | 目前公认综合”性价比“最高的微调方式,通过在噪声预测器的神经网络中嵌入一些额外的”低秩适应层“,实现高质量的微调,经常被用来在生成里植入一些人物角色和特定物体 | 轻量级的微调手段,中文名叫文本反演,可以通过一些文本(词元)向量层面的微小改动起到不错的微调效果,现在多用于一些简单的概念植入或者提高生成图片的质量 |
我猜现在的你肯定已经跃跃欲试,想要自己“炼”一个模型出来体会一下训练的乐趣了吧?敬请期待下章:《Stable Diffusion模型训练之Embeddings》
















 4195
4195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











