







文本反演
提到文本反演你可能会比较陌生,但它产出的模型类型Embeddings(词嵌入)一定是你出图过程里经常会使用到的,它是一种轻量、小巧的微调模型格式,文件名后缀一般为.pt(或.safetensor),每个Embeddings文件的大小在几KB到几百KB左右。为什么Embeddings文件这么小呢?
“词嵌入”这个名字可以在一定程度上揭示它的原理,它会把额外训练集里的图片特征“浓缩”在一起,提取成额外的嵌入向量,并在我们生成图片时加入到提示词生成的那些词向量里共同发挥作用,它被研究出来时曾经引发了轰动,因为当时唯一的微调手段Dreambooth在配置和训练集上的要求都特别高。动辄可能就要几百张图炼上好几天,相比之下,它最少需要3~5张图训练一个小时以内就能起到不错的效果。并且支持无标注文本的“极简”训练方式,可以被用于塑造某个指定形象或者特定风格。
虽然训练效果可能不如后面诞生的LoRA那么完善(感兴趣的同学请期待下章《Stable Diffusion模型训练 — LoRA》),但他仍然以最简单易用以及小巧轻便的特点而广泛传播,目前最大的用途在于提供负面词嵌入(Negative Embeddings)来优化生成质量、修复错手等问题。也可以用于灵活调节年龄、性别、人物表情等画面构成元素,用它来当入门训练的第一站就再合适不过了。
很多人会以为训练一定要配置复杂的程序和环境,捣鼓一大推东西才能开始工作,但其实我们平时出图作画用得最多的Stable Diffusion Web UI里已经集成了Embeddings训练的功能了。
打开Stable Diffusion Web UI -> Train里面就可以帮我们轻松创建一个Embeddings或Hypernetwork(已淘汰,具体可查看上一章)
让Stable Diffusion画一个它从未见过的人
那我们要炼些什么呢?回归训练这件事的本质吧,Stable Diffusion的基底模型本身其实就非常强大,因为它已经预先学习了几十亿张图片,你让它去画一些生活中常见的事物,它都能画的出来。那有没有它画不出来的呢?当然有,如果一个东西它从来没有见过就肯定画不出来。
比如:这位精神抖擞的中年企业家叫黄仁勋英文名Jensen Huang被科技圈和游戏圈的朋友亲切的称呼为“老黄”,也背负着“显卡教父”,“核爆狂魔”、“皮衣刀客”、“服装巨头”等一系列富有特色的外号。

这样一位知名人物原本我以为AI应该是能认识的,直接用他的英文名做提示词来生成一下,不行它不认得。
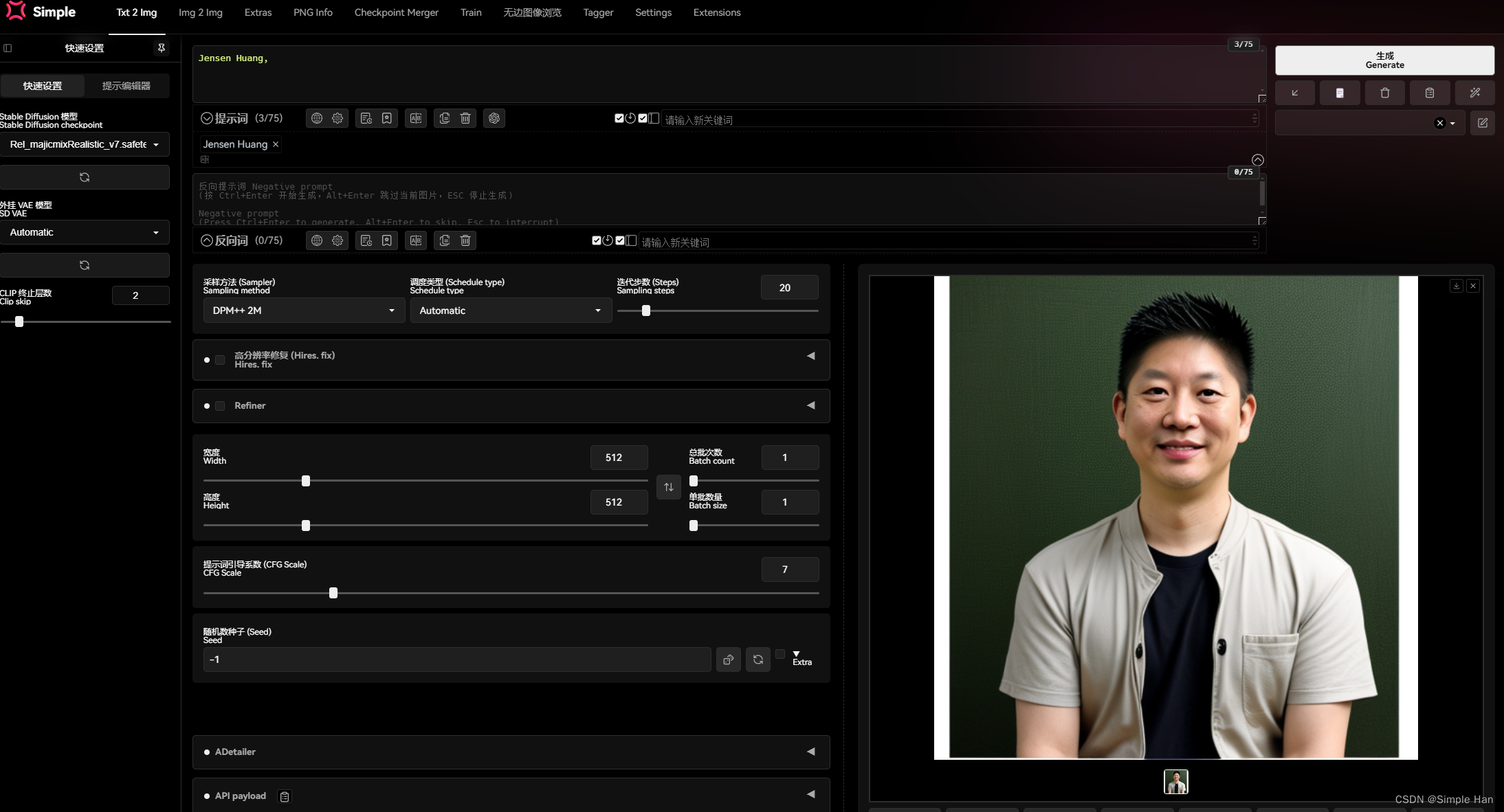
我们进一步丰富描述写清楚他的身份再加上“穿皮衣”、“戴眼镜”等描述性成分AI是大概理解我们的意思了,但这根本不是老黄啊。
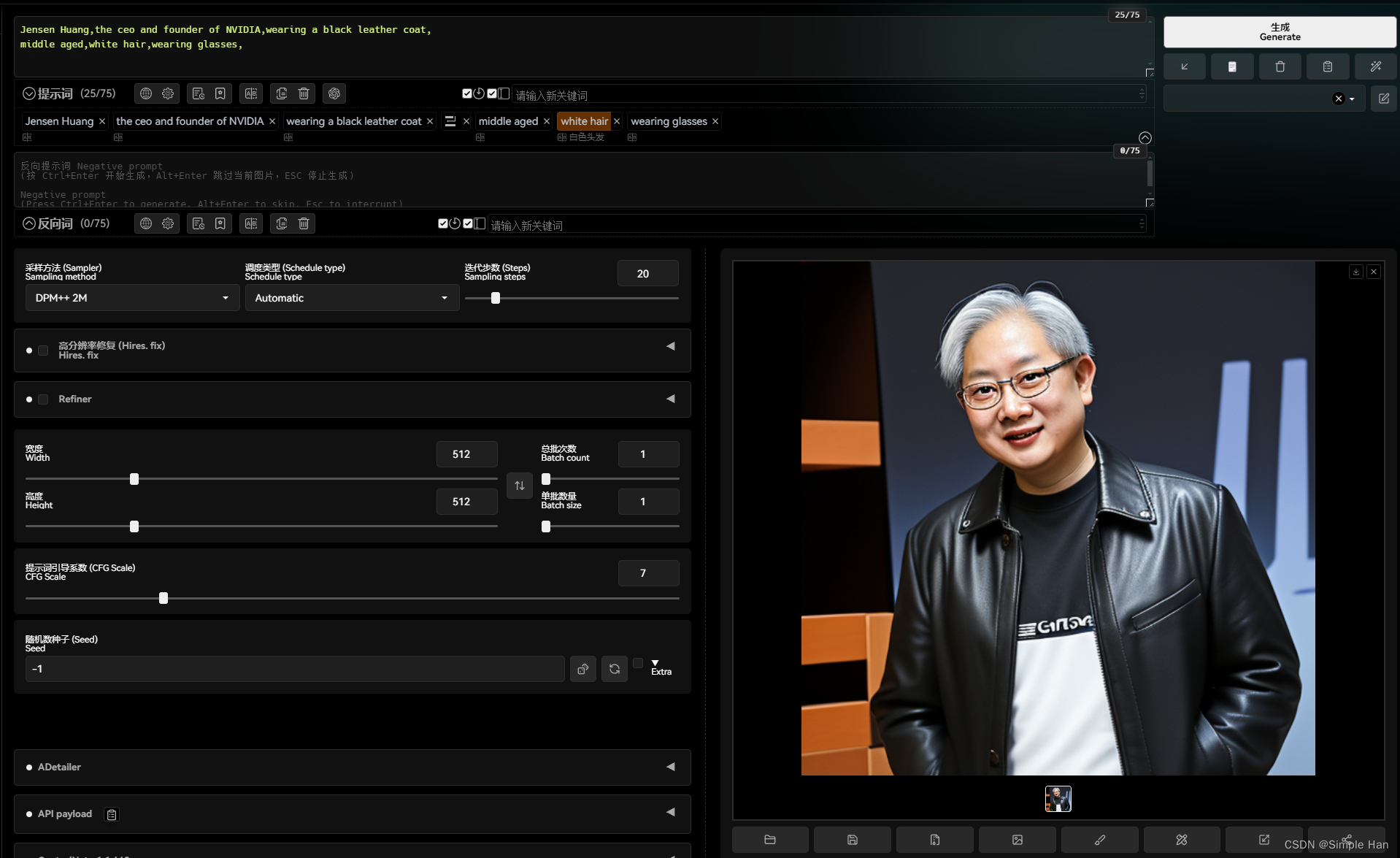
如果你也做过类似的尝试,你会知道提示词能去控制的东西是有限的。一些相对比较新或者比较冷门的角色、概念如果恰好不在预训练模型的数据集里,那你想要通过提示词去实现目的就是几乎不可能的一件事情。此时微调训练的重要性就被凸显出来了。
教Stable Diffusion认识一个人
当你想要让AI画出一个它从来没有见过的东西时,就需要喂给它额外的训练集,并通过这些微调手段引导他进行新的学习,通过接下来这个Embeddings的“炼制”流程你可以洞悉模型微训练的根本逻辑并领略它的实际作用。
在训练一个Embeddings只需要非常简单的三步。
准备训练集
如果你想教AI认识黄先生那就得找一些他的图片作为额外的训练集,炼Embeddings的时候不用多可能10~20张就可以了。常见图片格式(jpg / png / webp等)都可以,把它们装在一个文件夹里。
图片预处理
预处理的意义就是让训练集更符合模型训练本身的“规范”,通常预处理需要做的两件事情分别是给图像做“裁剪”和“打标”,先说说裁剪这些从网上下载下来的图片初始状态下尺寸都是不一样的,我们需要将它们全部缩放、裁剪成512像素的正方形图片。SD(1.5)的预训练模型是用512*512像素的正方形图片进行训练的。
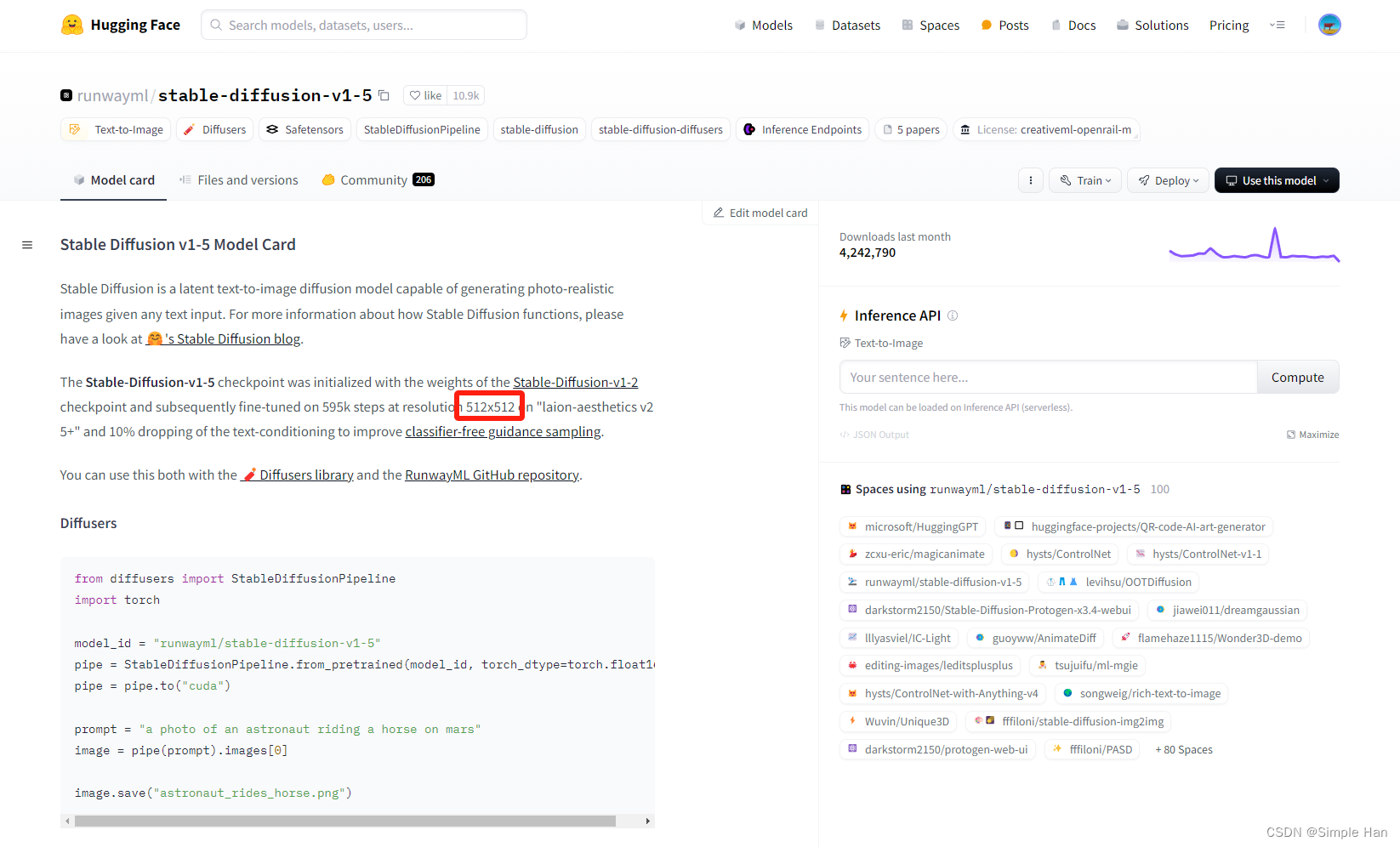
也就是说它之前学习的几十亿张图片都是这个尺寸,因此在利用SD和各种微调模型作图时使用1:1的正方形比例并且把初始尺寸设置为512*512所呈现的画面内容一定是最为“精准”的,
既然我们是在它的基础上去做微调那取的最好效果的方式一定是让新的训练集也符合它之前的这些“经验”,这需要我们自己一张张图去手动操作吗?当然不用,WebUI就为我们提供了一系列“智能裁剪”的功能,我们打开“后期处理”标签,平常我们一般拿它来做一些图片的放大修复,但在更新到最新版本以后下面对多出来一系列非常有用的训练集处理功能,切换到批量处理文件夹模式,先在上方输入装着训练集图片的文件夹目录,下面设定一个新的文件夹,用来接受处理完的图片,将缩放倍数切换为缩放到宽高设置为512像素,并勾选“裁剪以适应宽高比”的选项,如果你为维持一切选项默认,它就会自动居中裁切你的每一张非正方形尺寸的图片。
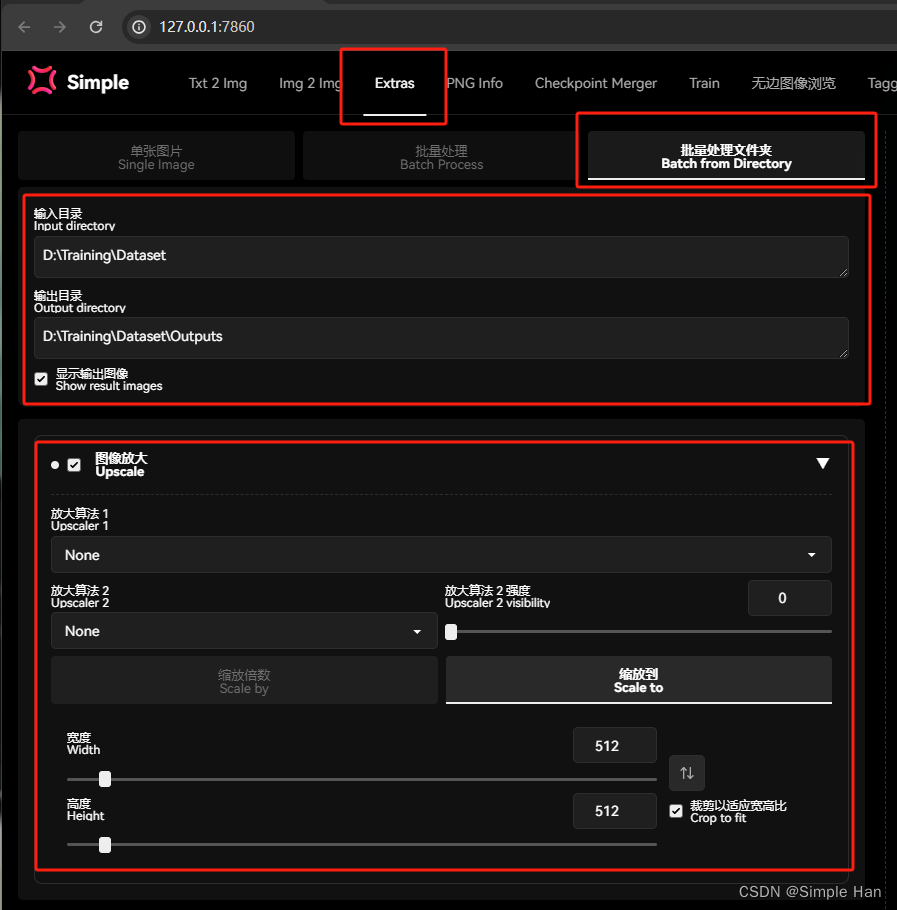
但我会推荐你一并勾选下面这个”自动面部焦点裁切“,它会智能识别图片里的人脸,并以它为中心规范裁切范围。内部的各项参数,可以维持默认。
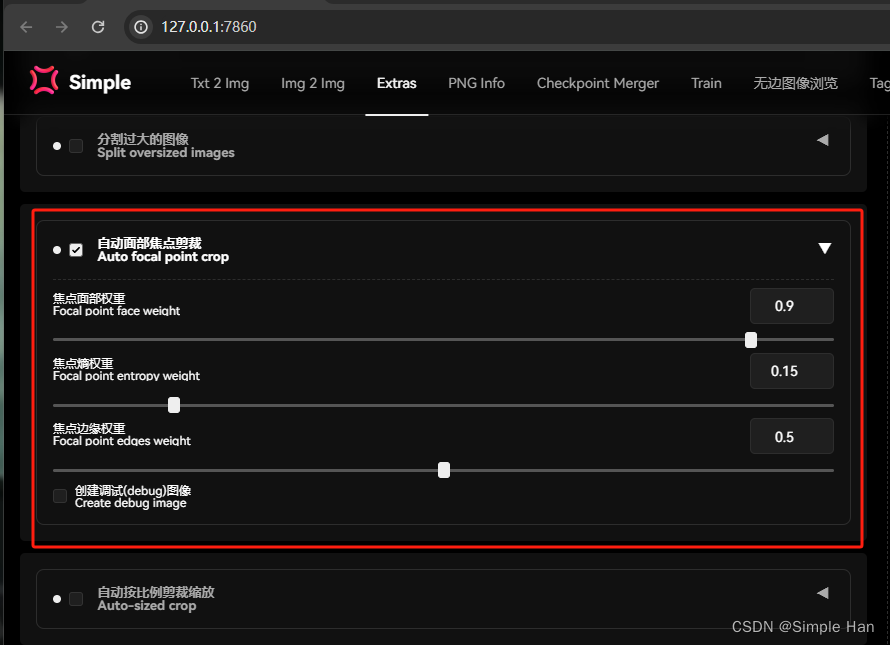
另一件要做的事情就是”打标“了,它的作用也不难理解。要给每一张图片配上文字说明,AI才能去”学习“里面的内容,这个”说明文字“,一般被我们成为训练里的标注(Caption),这也是打标这个名字的由来,打标也有”自动挡“的选项,在这个预处理标签的下方,有一个标注功能,勾选这个”使用BILP生成标签“的选项,它就会智能识别并用自然语言描述你的画面内容,如果你训练的主体对象是偏二次元的,使用旁边的DeepBooru生成标签会更准确,同时也存在比他们效果都要好但稍微复杂一点的打标方式,不防期待下一章的《Stable Diffusion模型训练 — LoRA》,
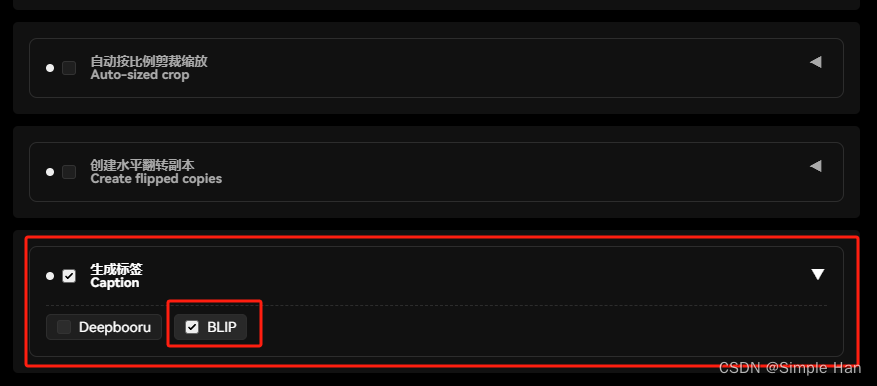
点击进行预处理,过一小会目标文件夹里就会装着已经裁剪好的图片,同时每张图片边上会有一个同名的txt,可以用记事本打开,里面就存着它的描述信息了。
调节训练参数
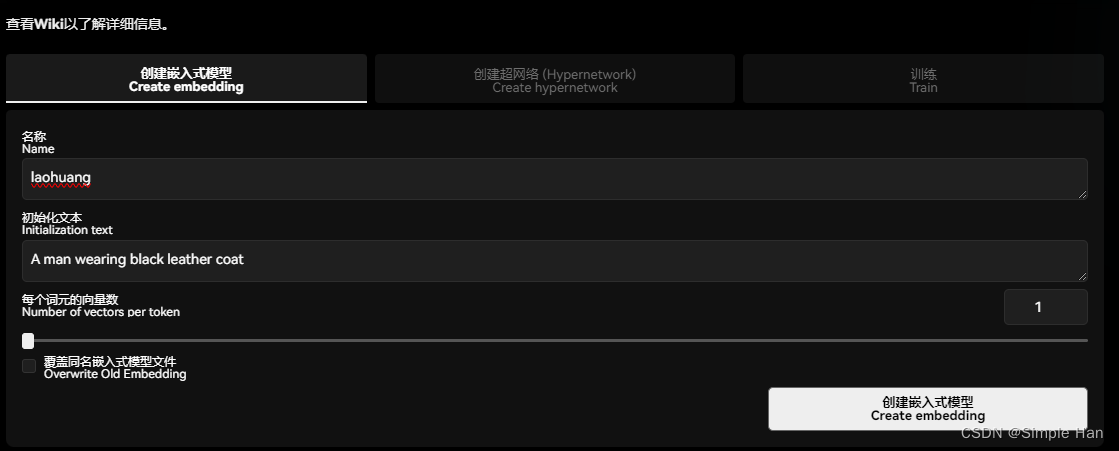
我们先在第一个标签这里创建一个Embeddings,你可以给这个Embeddings起一个好记的名字,因为后续你去用它的方式就是在提示词里输入这个名字(输入什么都可以),这个例子我们就以汉语拼音的”Laohuang“来命名,下方有一个”初始化文字“(Initialization Text)的选项,一般情况下可以维持默认不变,也可以是一个用来描述你想植入的训练主体的文字,比如”一个穿着皮衣的男人“,而这个词元向量数(Number of vectors per token)需要结合文本编码器的作用来理解,即将这个初始化文字拆成最小的Token以后,每个Token对应的嵌入向量个数,向量数越多,它能最终去”描述“的图像内容就越复杂,但根据一些社区训练者的经验以及我自己的实际测试,它对实际训练效果影响不算大,大部分时候设置为1就可以取得不错的效果,可以在效果不好的时候再尝试试着去增大(但最好不要超过12)。
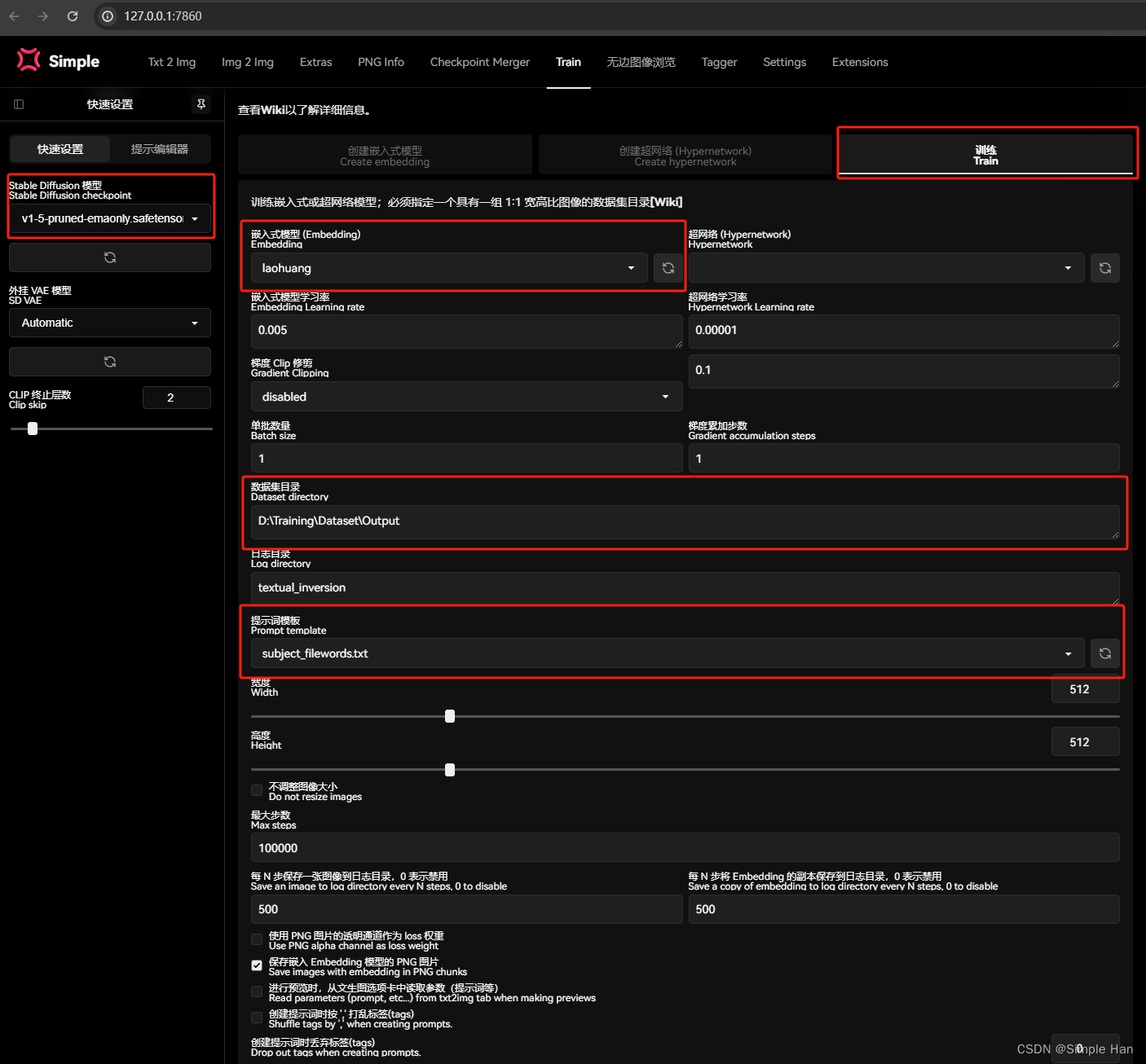
点击创建即可在WebUI根目录Embeddings文件夹内,和你从网上下载下来的其他词嵌入模型放在一起,但它现在还是一个空的模型,不包含任何训练数据,开启训练的地方在最后一个”训练“标签这里。这里面的参数琳琅满目,但目前你只需要关注其中一小部分,首先在上面选择刚刚我们创建好的这个Embeddings,如果没有,点一下右边的刷新按钮再展开列表,随后在下方的”数据集目录“里,填入刚刚预处理的输出文件夹—就是装着裁剪和打标好的图片还有标注的那个文件夹,在训练文本反演的时候,为了增强文本反演的作用WebUI的开发者提供了一系列提示词模板(Prompt Template),它的作用是在向AI输入标注信息时与你提供的标注文本随机结合来强化概念的植入,其中”subject“一般用于训练对象(人物),”Style“用于训练风格,因为我们要训练的是”人“选Subject即可,后面的所有选项你都可以维持默认不变。对了还有一个非常重要的东西,就是训练的”底模“,因为我们这个训练是在WebUI里进行的,所以训练的底模会默认设置成左上角你用来出图的这个Checkpoint,在选择底模时,有一个较为普遍的原则,是尽可能使用最原始的预训练模型进行微调,可以最大程度保证学习效果与模型的泛用性,同样挑选底模的更多门道我们会在后面文章中持续去讨论,请继续关注。
在这里我使用的便是SD 1.5的官方模型,接下来点击”训练嵌入式模型“即可启动模型训练
AI在进行微调训练时的大致逻辑
一个比较科学的描述是,它会先利用我们输入的描述成分(即标注)生成图像,并将它们与训练数据集中的图像进行比较,通过生成的差异程度,引导AI不断微调嵌入向量,让生成的结果越来越接近于训练图像的副本。最终让微调模型能够指向一个完全等同于训练图片的结果。
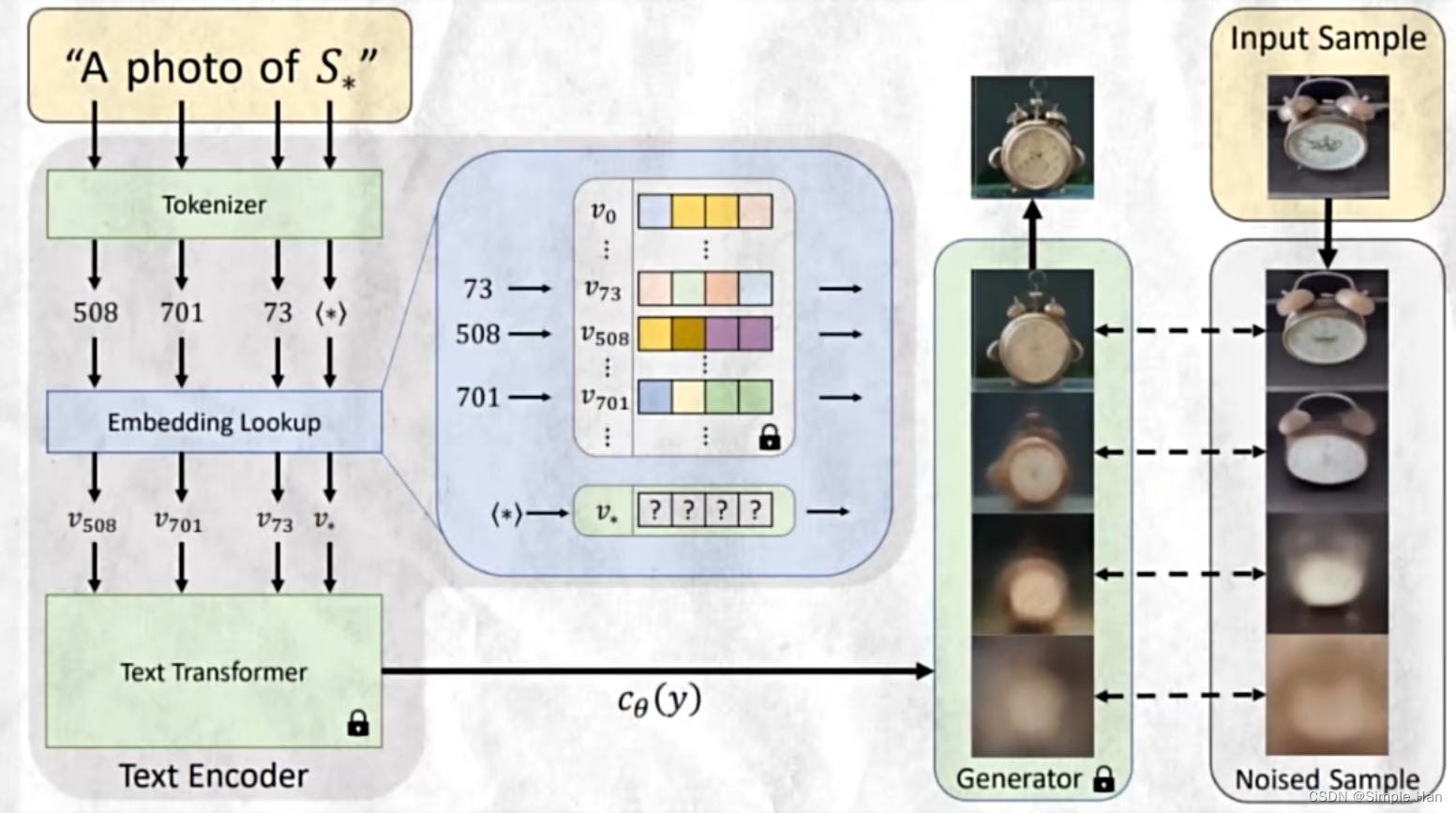
打个好懂的比方,就像是你想让它根据标注信息生成一个叫做”老黄(Laohuang)“的男人,AI一开始完全不认识老黄,所以生成出来的肯定是一个普通的男人。这个时候,我们就给他打”差评“,并且拿训练集里的图片给它看,指出哪里可以更像,让它照着再改。
久而久之AI就会在”Laohuang“这个词组和我们展示的图片之间建立起关联并且画的越来越像,这个基本逻辑在之后的LoRA与大模型的训练里其实都是通用的,在所有训练中,训练的进展一般会以”步数“来衡量,启动Embedding训练以后,右边会开始跑一个进度,总时长可能是几个小时到几天不等。
具体取决于你的设备情况,下方这个steps就是你已经训练的步数,它的头顶上会有一张预览图,就是在这个训练的过程中AI根据我们提供的标注画出来的结果
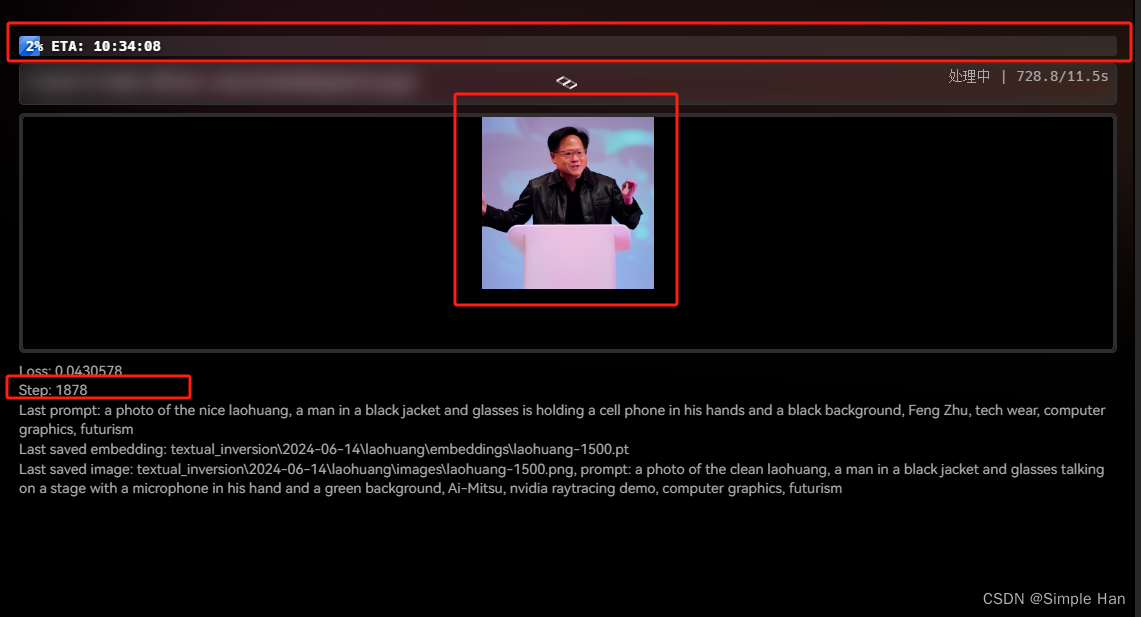
它不会加入任何质量提示词,所以可能画出来会比较粗糙,但你可以通过它判断AI是否在学得”越来越像“,它出现的频率取决于你在下方设置的这个”每N步保存一张图片“,如果你全程观察的话,会发现一开始画的确实很”不像“,因为这个时候它学习的还不多,但随着训练的步数越来越多,AI就会画的越来越像,看在进展到一万多步以后就基本能将黄先生的这个形象给描绘出来了。
训练到什么时候才算可以了呢,按照初始设置训练会在步骤达到10万步的时候自然停止,但一般我们也不用训练这么久,在Embeddings的训练上1~2万步就够了,你也可以用实时的预览图作为参考标准,什么时候觉得AI学会了就可以让它停下了。我们只需要点击标签页最下面的中止,它就会把到目前为止的训练结果保存到Embeddings里啦,
验证自炼的Embeddings效果
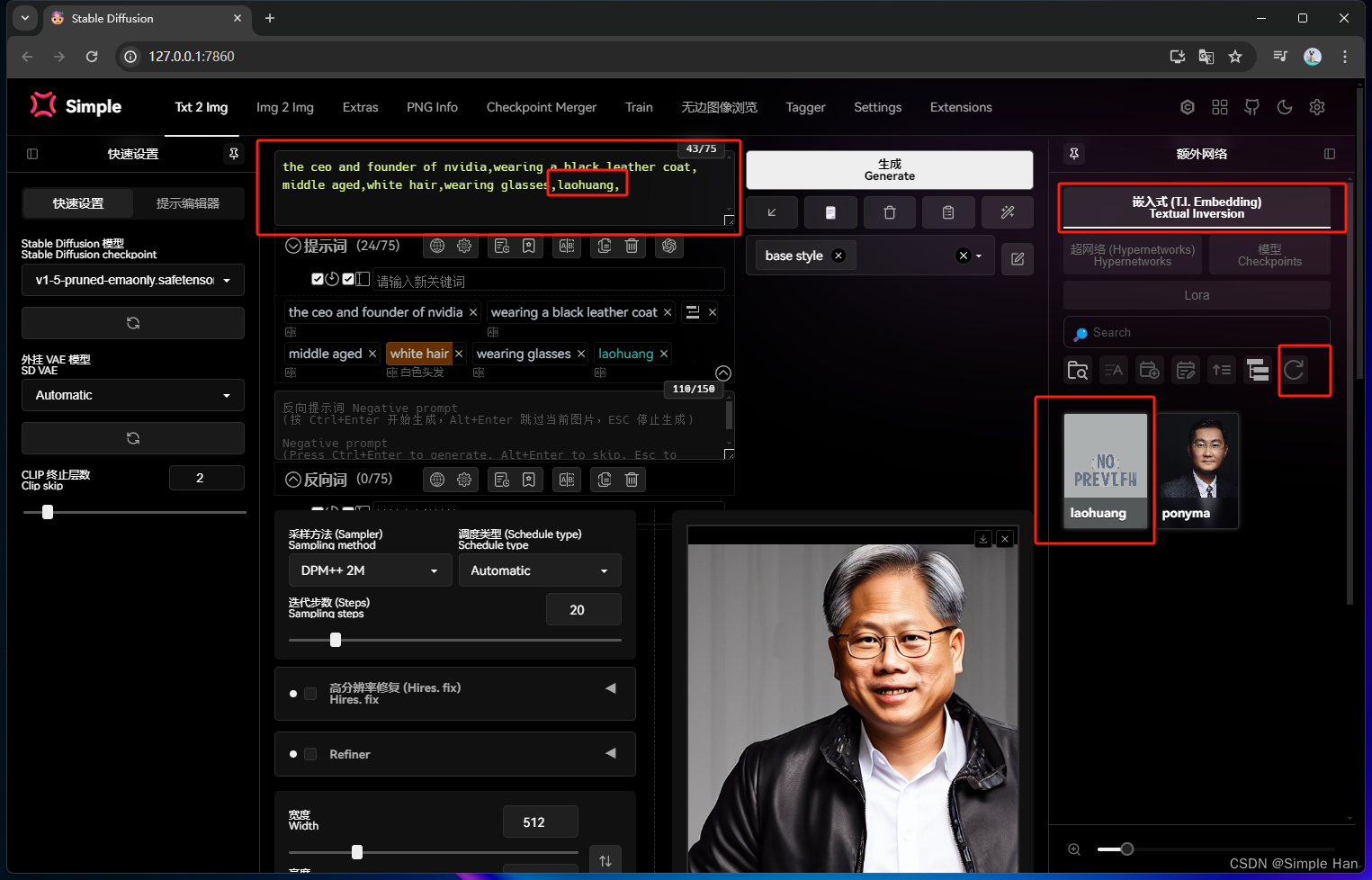
我们回到文生图界面,点开生成标签旁边的Embeddings(嵌入式模型)标签刷新一下它就会将你的模型库里有的Embeddings呈现出来,里面的Laohuang就是我们刚刚炼好的Embeddings模型了,点击一下它会自动将文件名填入提示词框里,如果你记得模型的名字,也可以直接手敲上去效果是完全一样的,我们原来生成的图片是这样的:一个很普通的穿着皮衣的男人,在提示词完全不变的情况下,只需要加入这个新”炼“的小模型,看那个熟悉的”皮衣刀客“就会出现在画面里了,这就是训练一个Embeddings的全过程了。
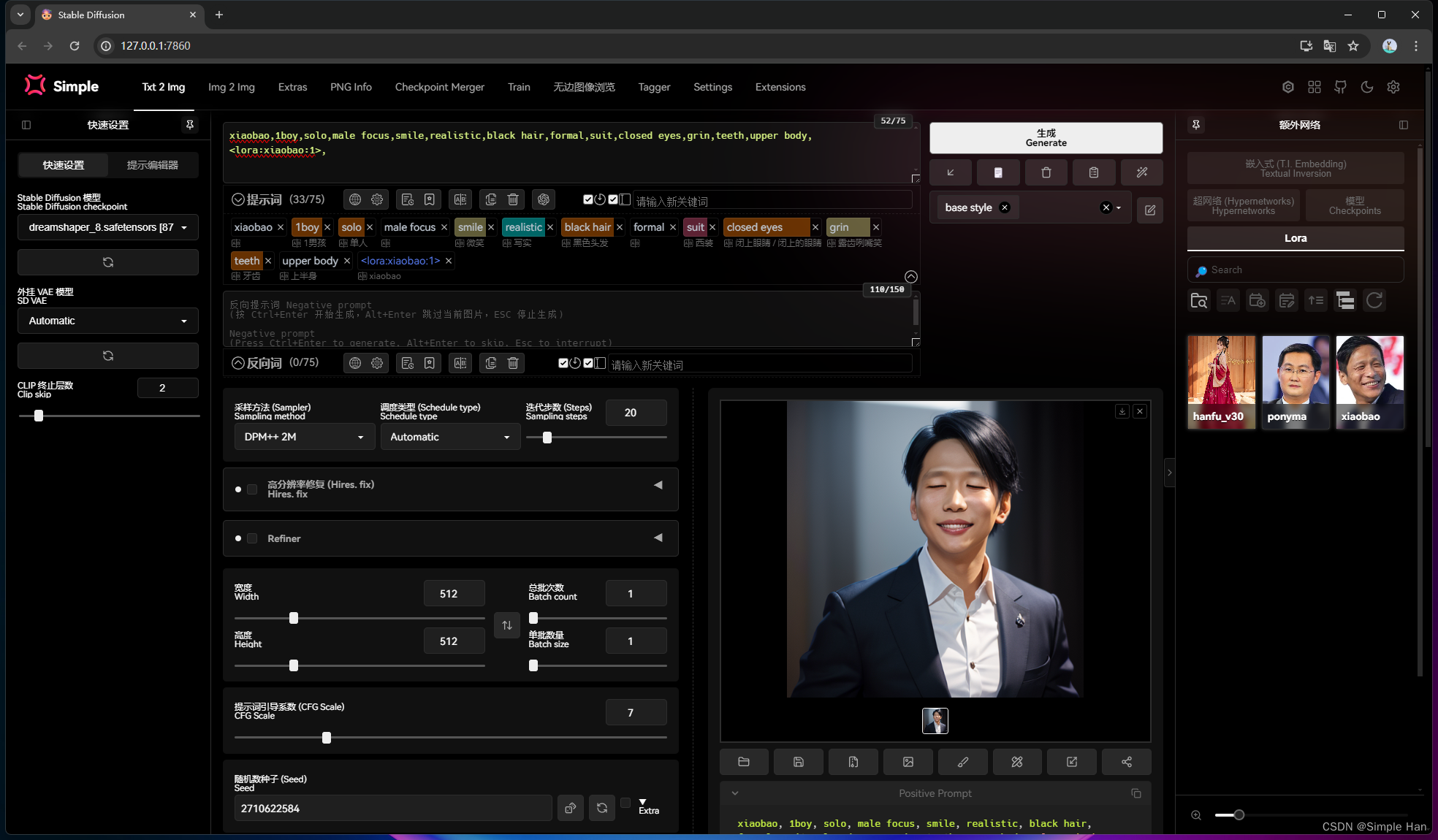
希望这篇可以帮助你了解模型训练的原理和基本逻辑,因为Embeddings仅仅是针对文本编码器做微调的,所以它的微调效果肯定没那么好,如果你多跑几张会发现好像也没那么像,相比之下其他两种微调手段的效果会更好一些,比如这是使用宋小宝训练出的LoRA模型,是不是比Embeddings更像了呢?
顺带一提Embeddings的训练大约需要小号8~10G左右的显存,而LoRA训练在最低6GB的设备上也可以进行是相对来说”性价比“更高的一种选择,如果你开始对模型训练感兴趣了,那不妨期待下一章《Stable Diffusion模型训练 — LoRA》


















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











