







说明
除特殊说明,本文以及这个系列文章中的所有插图都来自斯坦福cs231n课程。
转载请注明出处;也请加上这个链接http://vision.stanford.edu/teaching/cs231n/syllabus.html
Feel free to contact me or leave a comment.
Abstract
今天的主要内容是Backpropagation and Neural Networks (part 1).
我们在第2节课定义了一个scores function,在上节课对其补充了SVM loss和Softmax loss这两种损失函数以及regularization.
我们现在的主要目的,就是从Loss=data loss+regularization中解出最好的W使得Loss最小。我们用梯度下降的方法。
梯度下降要做的就是重复这个过程直到Loss function在我们的训练集上收敛。
因为导数方向是函数上升的方向,那下降的方向就是导数的反方向。
#Vanilla Gradient Descent
while true:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += - stepsize*weights_grad #perform parameter update
在梯度下降的代码实现中:Numerical gradient执行过程较慢,结果是对真值的近似,但是容易编写;而Analytic gradient执行过程快速,结果精确,可是代码实现容易出错。所以,在实际编写代码的过程中常常用Analytic gradient编写代码,而用Numerical gradient做检查。
Optimization
优化过程中,对于loss function的梯度下降问题,我们更应该想着从Computational Graph方面着手,而不是想着写出整个loss function的形式利用微积分解决,另外,对于Neural Turing Machine这样大型的网络结构,我们很难写出整个网络的loss function。另外,我们可能需要考虑实现梯度下降时的数据结构。
Computational Graph
根据链式原则,因为y对f的影响是-4;因此,仅增大y会减小f,减小4▽y.
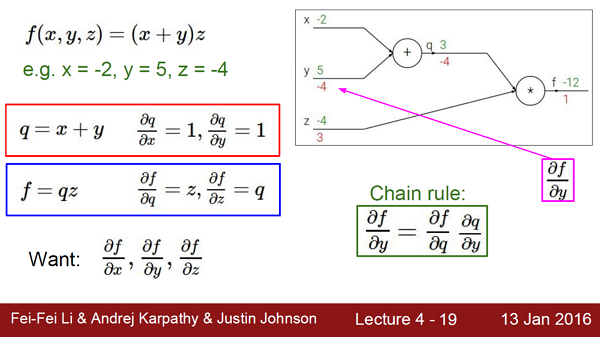
神经网络在向前传播的过程中,我们就可以算出每个神经元对于当前输入的“局部梯度”,那么显然,在back proportion时我们只需要对这些local gradient相乘就好了。

Patterns in backward flow
值得一提的是,Gradients add at branches,如果一个神经元在前向传播时分成了好几条路,那么在chain rule也就是back proportion时只所有分支的梯度要相加回来。
Implementation: forward/backward API
Caffe Sigmoid Layer
Vectorized operations
Summary so far
- neural nets will be very large: no hope of writing down gradient formula by hand for all parameters
- backpropagation = recursive application of the chain rule along a computational graph to compute the gradients of all inputs/parameters/intermediates
- implementations maintain a graph structure, where the nodes implement the forward() / backward() API.
- forward: compute result of an operation and save any intermediates needed for gradient computation in memory
- backward: apply the chain rule to compute the gradient of the loss function with respect to the inputs.
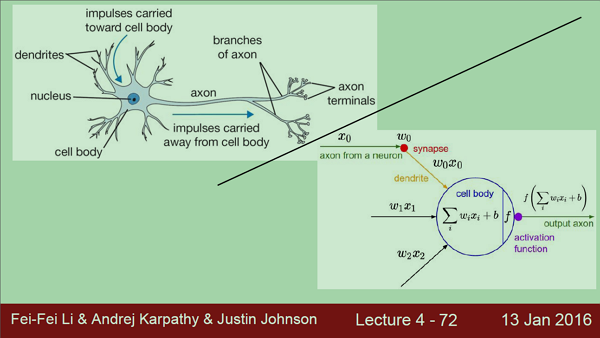
Neural Network
without the brain stuff

with the brain stuff
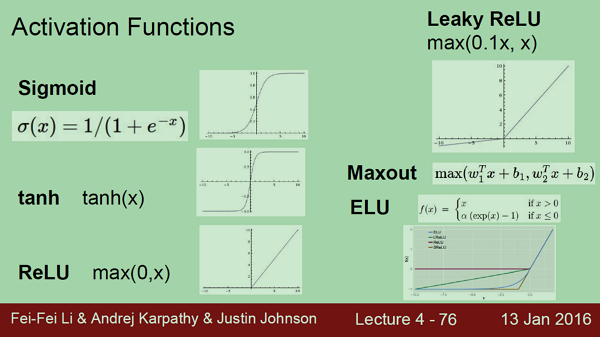
Activation Functions
Neural Networks: Architectures
We stack neurons into layers,not exactly like human brain.
带权值的层才被算作神经网络的一层,因此,输入层并不计入神经网络之中。
Setting the number of layers and their sizes,more neurons=more capacity.但是,Do not use size of neural network as a regularizer. Use stronger regularization instead.
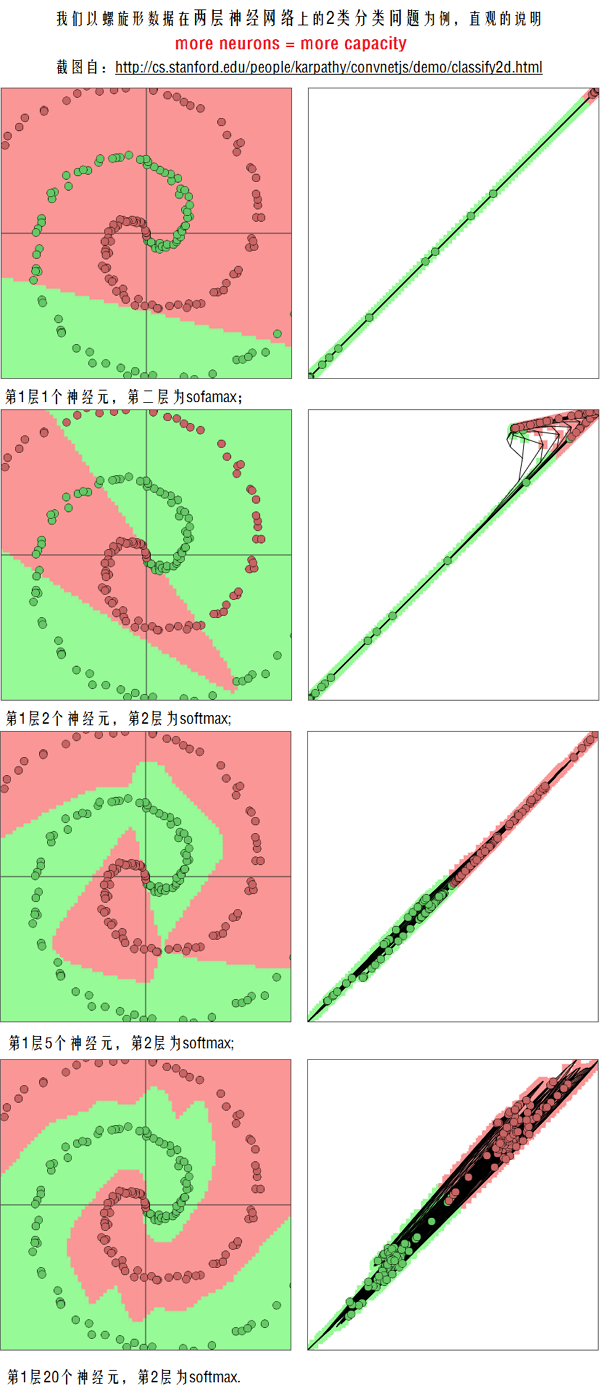
(截图自http://cs.stanford.edu/people/karpathy/convnetjs/demo/classify2d.html)
Q: Does more neurons always better?
是的,more is always better; 但是,more neurons也常意味着更可能过拟合,为了防止这种情况,我们不是降低神经元个数,而是让regularization的系数更大。
Summary
- we arrange neurons into fully-connected layers
- the abstraction of a layer has the nice property that it allows us to use efficient vectorized code (e.g. matrix multiplies)
- neural networks are not really neural
- neural networks: bigger = better (but might have to regularize more strongly)
Next Lecture:
More than you ever wanted to know about Neural Networks and how to train them.















 599
599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









