









从原理和细节上搞定HashMap
声明:网上讲HashMap的帖子很多,各自有各自着重介绍的地方,个人把自己比较感兴趣的内容和自己的一点点认识写下了。
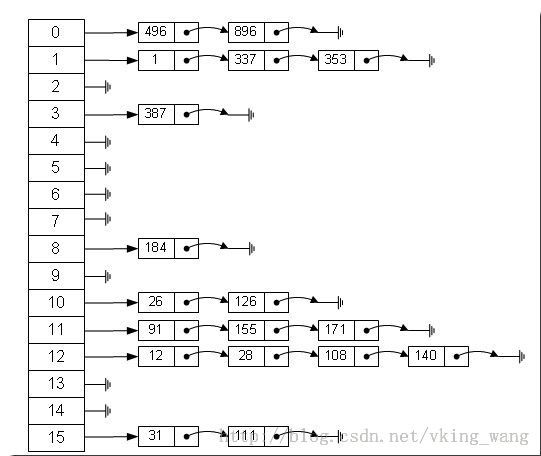
hashmap是由数组和链表组成的,要插入的元素首先根据哈希函数得到hash值,然后根据规则(取模),得到自己要插入的桶(所谓的桶就是图中的0-15的数组元素)的号。然后排在桶中元素的后面。而要取的时候也一样,先拿到桶号,在沿着这个指针逐个往下找。比如上述哈希表中,我们现在假设一个要插入的元素经过Hash函数后的值是44,44%16=12;所以这个元素要插入到桶号为12的桶中,接下来它一直往下找,最后排在了140后面。
话不多说,基本的原理我想大多数人应该也知道。不清楚的可以去有些博客上看看,应该很快就明白。
然后我们来看看JAVA1.8中关于Hashmap的源码:
这里有些不太常用的字段和函数就不一一列举了。
HashMap主要属性:
public class HashMap<k,v> extends AbstractMap<k,v> implements Map<k,v>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认桶的数量
static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量
static final float DEFAULT_LOAD_FACTOR = 0.75f;//填充比
//当add一个元素到某个位桶,其链表长度达到8时将链表转换为红黑树
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
transient Node<k,v>[] table;//存储元素的数组
transient Set<map.entry<k,v>> entrySet;
transient int size;//存放元素的个数
transient int modCount;//被修改的次数fast-fail机制
int threshold;//临界值 当实际大小(容量*填充比)超过临界值时,会进行扩容
final float loadFactor;//填充比
而其中的负载因子loadFactor的理解为:HashMap中的数据量/HashMap的总容量(initialCapacity),当loadFactor达到指定值或者0.75时候,HashMap的总容量自动扩展一倍。
其中最常用的两个函数实现大致如下:
// 存储时:
int hash = key.hashCode();
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];
接下来我觉得hash函数这点很重要。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这里hashCode()通过对象得到一个int的编码,不同的对象的函数不一样,如String的hashCode()
就是将String转化成char数组,然后把这个数组看做是一个32进制的数。
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
至于之后的h = key.hashCode()) ^ (h >>> 16)
开始有些不懂,后面去知乎上看了看。
这段代码,Java 7是这么写的
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
Java 8只做一次16位右位移异或混合,而不是四次,但原理是不变的。两段代码的目的都是想让哈希函数映射得比较均匀松散。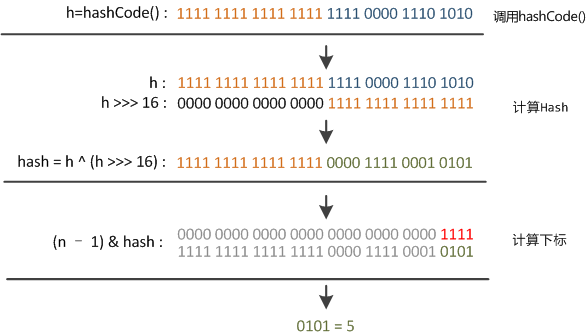
右唯一16位,正好32位的一半,自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。而且混合后的低位掺杂了高位的部分特征,这样高位的信息也被变相的保留下来。
后面还有个人认为比较重要的内容就是resize(),以及Java 8中的红黑树。
内容会在后面补充。
treefiybin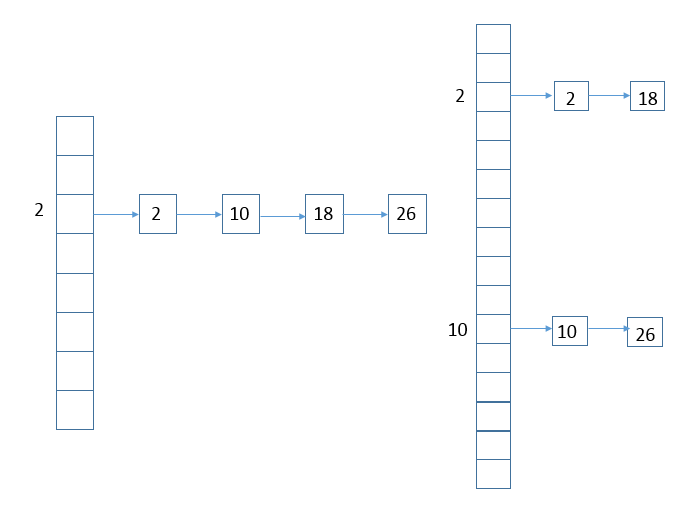
红黑树替代普通的链表
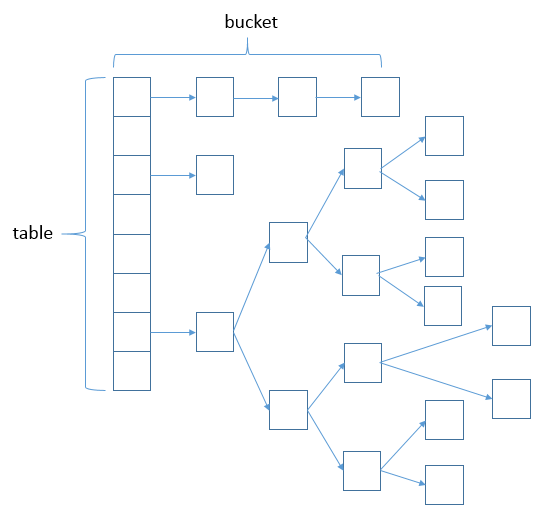
最后来看看java8 很大的一个改进resize 扩容
举个例子
上边图中第0个下标有496和896, 假设它俩的hashcode(int型,占4个字节)是
resize前:
496的hashcode: 00000000 00000000 00000000 00000000
896的hashcode: 01010000 01100000 10000000 00100000
oldCap是16: 00000000 00000000 00000000 00010000
496和896对应的e.hash & (oldCap)的值为0, 即下标都是第0个。
resize后:
496的hashcode: 00000000 00000000 00000000 00*0*00000
896的hashcode: 01010000 01100000 10000000 00*1*00000
oldCap是32: 00000000 00000000 00000000 00**1**00000
代码中 if ((e.hash & oldCap) == 0)
496和896对应的e.hash & oldCap的值为0和1, 即下标是第0个和第16个。
它将原来的链表数据散列到2个下标位置, 概率分别是0.5。
因为hashcode的第n位是0/1的概率相同, 理论上链表的数据会均匀分布到当前下标或高位数组对应下标。
回顾JDK1.7的HashMap,在扩容时会rehash即每个entry的位置都要再计算一遍, 性能不好, 所以JDK1.8做了这个优化。
再回到文章最开始的问题, HashMap为什么用&得到下标,而不是%? 如果使用了取模%, 那么在容量变为2倍时, 需要rehash确定每个链表元素的位置。
本文好多地方都是在各位大神的博客上摘抄和学习到的,只是自己整理归纳方便以后复习。
具体的引用就不写了,忘各位博主见谅!















 250
250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









