







R语言中用于存储数据的结构有:标量、向量、数组、数据框和列表。
在R中,对象是指可以赋值给变量的任何事物,包括常量、数据结构、函数、甚至图形。因子(factor)是名义型变量或有序型变量。
1.数据结构
向量
向量是用于存储数值型、字符型或逻辑性数据的一位数组。函数c()可以用来创建向量。标量是只含有一个元素的向量。
已定义的向量对象加上方括号,在方括号中给定元素所在的位置的数值,就可以访问向量中该位置的元素。
矩阵
矩阵是一个二维数组,每个元素都具有相同的属性。函数matrix()用来创建矩阵。
格式为:A <- matrix(vector,nrow=number_of_rows,ncol=number_of_cols,byrow=true/false,dimnames=list(rownames,colnames))
其中vector包含了矩阵的元素,nrow和ncol分别表示行和列的维数,dimnames包含行名和列名(rownames,colnames也分别为向量)。byrow是指按行或者按列填充,默认是按列。
同样可以使用A[i,j]的形式来获得矩阵A中第i行第j列的数据。A[i,]表示选取第i行的数据,A[,j]表示选取第j列的数据。
数组
类似于矩阵,但维数可以大于2。函数array()可用来创建数组。格式如下:
A <- array(vector,dimensions,dimnames=list())
其中vector包含了数组中的数据,dimensions是一个数值型向量,各个维度的最大值,dimnames是个维度名称的列表。
数据框
数据框中科已包含不同列可以有不同的属性(类似于数据库中的表)。可以通过函数data.frame(col1,col2,col3,...)。 col1,col2,col3...可以为不同的类型
数据框中元素的选取:
A[1:2]----------表示选取数据框A的前两列
A[c(col_names,...)]------------------选取多列,向量中为个列的名称
A$col_names--------------------选取数据框的col_names列
attach()函数可以将数据框添加到R的搜索路径中。R在遇到一个变量名后,将检查搜索路径中的数据框,以定位到这个变量。(提案件后就不用使用dataframe$col_names的形式读取某一列,直接用列名即可)
detach()函数将数据框从搜索路径中移除
当有同名的队形的时候,直接使用attac()h和detach()函数回出现问题,变量名的智慧是更早被定义的值。此时可以使用函数with()
例如 with(A, {
col_names1
col_names2}) 其中A 为数据框
函数with()的局限性在于,复制仅在在此函数的括号内生效。
当需要在函数with()外使用是,采用特殊赋值符号 <<- 代替标准复制符号
eg:
with(A, {
colname1 <<- col _names1
colname2 <- col _names1})
在with()外时,clname1是有效的 ,colname2是无效的。
相比于attach(),更多建议使用with()函数
因子
类别(名义型)变量和有序类别(有序型)变量在R中称为因子。
函数factor() 以一个整数向量的形式存储类别值,整数的取值范围是[1...k](k是名义型变量中唯一值的个数),同事一个由字符串(原始值)组成的内部变量将映射到这些整数上。
eg:名义型
diabetes <- c("type1","type2","type1") 则 语句diabetes <- factor(diabetes) 将次向量映射为类似(1,2,1),内部关联为1=type1,2=type2。针对向量diabetes 进行任何的分析都会将其作为名义型变量对待。
有序型
函数factor()需要制定参数order=TRUE。 status <- c("poor","improved","Excellent","Poor") 语句 status <- factor (status,order=TRUE),会将向量编码为(3,2,1,3),内部关联为1=Excellent,2=improved,3=poor。(字符型变量,因子的水平默认依字母顺序创建,故以上的顺序为3,2,1,3),也可以指定排序 status <- factor (status,order=TRUE,levels=c("poor","improved","Excellent"))
列表
列表list就是一些对象的有序集合。列表允许整合若干对象到单个对象名下。例如一个列表中可能包含若干向量、矩阵、数据框、甚至其他列表的组合。
函数list()用来创建列表,形式如下
A <- list(object1,object2,....)或者A <- list(name1=object1,name2=object2,....)
下图为R中的数据结构:
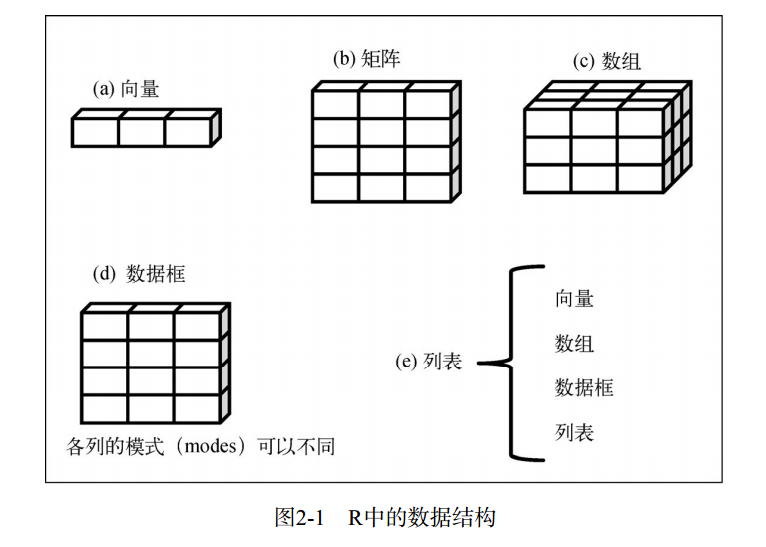
注:
在R中,对象名称中的句点(.)没有特殊意义,但是符号$代表的含义却不同于其他语言,即制定一个对象中的某些部分。
R中的下标是从1开始的
变量是无法被声明的。他们在首次被赋值时生成。
2.数据的输入
R 中可导入的数据源很多,如下图:
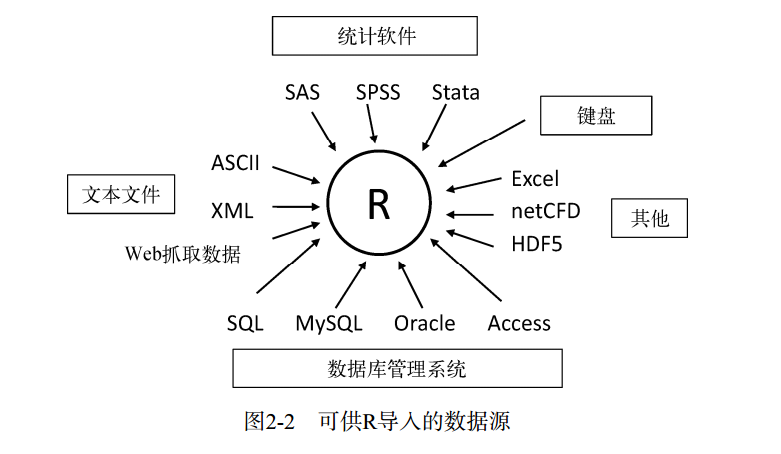
使用键盘输入数据
步骤如下:
(1)创建一个空数据框(或 矩阵),其中变量名和变量的模式需与理想中的最终数据集一致;
(2)针对这个数据对象调用文本编辑器,输入数据,并将结果保存在此数据对象中
eg: A <- data.frame(age=numeric(0),gender=character(0),weight=numeric(0))
A <- edit(A)
需要修改数据时,可在此调用函数mydata <- edit(A)或者使用fix(A)
直接从键盘输入数据使用于小数据集
对于大的数据集,可以考虑从其他数据源导入,以下介绍几种从其他数据源导入数据的方法。
从带分隔符的文本文件导入数据
函数read.table()可以从带分隔符的本本文件中导入数据。可以读入一个表格文件并将其保存为一个数据框。使用格式如下:
mydata <- read.table(file, header=logical_value, sep="delimiter", row.names="name")
其中file是一个带分隔符的文本文件,header是一个表明首行是否包含变量名称的逻辑值(TRUE/FALSE),sep用来指定数据的分隔符(逗号,回车,制表符等,默认为空格),row.names是一个可选参数,用来指定一个或多个表示行标识符的变量。
一般默认将字符型变量转换为因子,若不想转换时,使用参数stringsAsFactors,另外一种方法,是使用colClasses参数为每一列指定类型。
读入EXCLE数据
两种方法:
(1) 将Excle文件转换成.csv文件,使用函数read.table()(即同上述方法)读入数据
(2)使用RODBC包访问Excle文件(不能读.xlsx文件)。
先确保已经安装RODBC包(install.packages("RODBC"))
读入数据的代码如下:
library(RODBC)
ch <- odbcConnectExcel("文件名") # 若文件不再当前的工作目录,就要写上文件路径
madata <- sqlFetch(ch,"工作表名称")
odbcClose(ch)
.xlxs文件的读取使用read.xlsx()函数,需安装xlsx包,使用这个包要确保电脑安装了java,不然载入包的时候会提示rJava包不能载入。
read.xlsx(file,n) 其中file为文件名,n为xlsx中的第n个工作表。示例如下
library(xlsx)
workbook <- "F:/aa.xlsx"
mydata <- read.xlsx(workbook ,1)
读入SPSS数据
通过foreign包中的read.spss()函数导入,或者Hmisc包的spss.get()函数导入。
示例:
library(Hmisc)
mydata <- spss.get("aa.sav",use.value.lables=TRUE) #use.value.lables=TRUE表示让函数将带有值标签的变量导入为R中水平对应相同的因子。
导入SAS数据
在对于SAS9.1以上的版本,先使用PROC EXPORT将SAS数据集保存为一个逗号分隔符的文本文件,再使用从带分隔符的文本文件导入数据的方法读取到R中
<pre name="code" class="plain">SAS程序
proc export data = mydata
outfile="mydata.csv"
dbms=csv;
run;
R 程序
mydata <- read.table(“mydata.csv”, header=logical_value, sep=",")3.访问数据库管理系统
R中有多种面向关系型数据库管理系统的接口,包括SQL Server、Acess、MySql、Oracle、DB2、Sybase、SQLite、Teradata、PostgreSQL。一些包通过原生的数据哭驱动来提供访问功能,另一些则是通过ODBC或JDBC来实现。
ODBC接口
在R中通过RODBC包访问一个数据库比较流行,该方式允许R连接到任意一种ODBC驱动的数据库。
R中RODBC包中包含的函数有

RODBC包允许R和一个通过ODBC连接的SQL数据库之间进行双向通信。即R不仅可以读取数据库的数据,也可以修改数据库中的数据。·
举例,假设要读入一个数据库中的标A和B,程序如下
library(RODBC)
ch <- odbcConnect("mydsn",uid="Rob0,pwd="asb123") mydsn为数据源名称,uid为数据库用户名,pwd为密码
TA <- sqlFetch(ch ,A)
TB <- sqlQuery(ch ,"select * from B")
close(ch)
函数factor()可以为类别型变量创建值标签
举例:数据框patientdata中的gender变量,1表示男,2表示女,代码如下
<pre name="code" class="plain">patientdata$gender <- factor( patientdata$gender ,
levels = c(1,2),
labels = c("male","female"))
常用的处理数据对象的函数

















 2797
2797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









