









2.1什么是数据集
- 数据集通常是由数据构成的一个矩阵数组。行为观测列为变量(统计学术语,在机器学习学科称行为示例example列为属性attribute)。
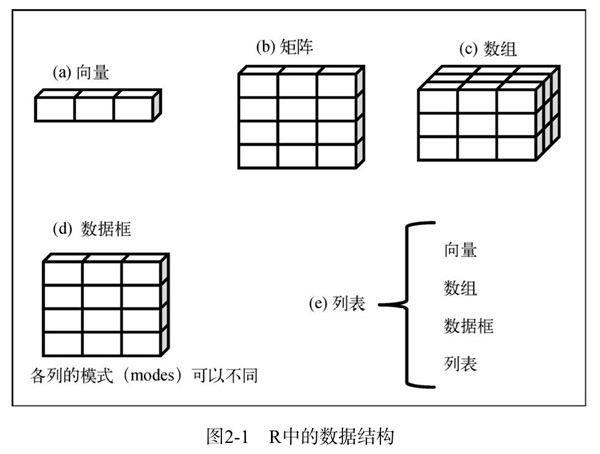
- R中有很多用于存储数据的结构,包括标量,向量,数组,数据框和列表
-
R原生可以处理的数据类型包括数值型(numeric,integer)、字符型、布尔型(TRUE/FALSE)、复数型、原生型(字节)
- numeric与interger两种数据类型的区分:numeric为浮点数,integer为整数,integer占用内存少,所以在数据方便时,把numeric转成integer可以节省内存
| #区别如下(使用as命令,as为显式强转) [1] 1 |
- 以一个表格为例:
| ID(行/实例标识符) | 入学时间(日期型变量) | 年龄(连续型变量) | 院系(名义型变量) | 性别(有序型变量) |
| 1 数值型变量 | 10/9/2015 数值型变量(存疑,如果算上'/'的话得按字符型变量算) | 18 数值型变量 | 信息 字符型变量 | 男 字符型变量 |
| … | … | … | … | … |
| 称为:行名 |
|
| 因子 | 因子 |
2.2向量
向量分为数值型,字符型和逻辑型,都可以用c()函数创建
| a <- c(1,2,35,3,6,-2,4) b <- c("one","two","three") c <- c(TRUE,TRUE,TRUE,FALSE,TRUE) |
| 同一向量中无法混杂不同模式的数据 |
| a[c(2,4)]访问向量a中的第二个和第四个元素 a[2:6]访问第二个到第六个元素 |
同时,还有vector()函数,可以限定创建特定类型的向量
| this_is_a_vector<-vector("numeric", length=10) #默认numeric类型向量会生成长度为10元素全为0的向量 |
| > this_is_a_vector |
需要注意的是,如果一个向量混入了不同类型的变量,R并不会报错,而是会隐式强转成同一种数据类型
如果数值型与字符型混在一起就会变成字符型,布尔型与数值型混在一起则会转成数值型,字符型与布尔型混在一起会变成字符型
同时,R还提供显式强转函数as.xx例如as.numeric(a)会把a转换为numeric类型同理还可转换成字符,布尔。
但有时候强转会失灵(即出现NA错误)
| > g<-c("a","b","c") |
2.3矩阵
同样,分为数值型,字符型和逻辑型通过函数matrix()创建矩阵
书写格式:
| my_matrix <- matrix(vector, nrow=5,ncol=5,byrow=TRUE/FALSE, dimnames=list(一个行名,一个列名)) #其中"一个行名"和"一个列名"用字符型向量生成e.g.①rnames<-("R1","R2")②cnames<-("C1","C2") ③dimnames=list(rnames,cnames)#rnames即为"一个行名",cnames即为"一个列名" |
| 创建了一个5*5的矩阵,元素在vector中到时候替换即可,byrow代表按行存储还是按列TRUE就代表按行存储,dimnames包含了可选的、以字符型向量表示的行名和列名。 |
例如
| >test_matrix<-matrix(1:20,nrow=5,ncol=4)#创建5*4矩阵,因为没有设置byrow=TRUE所以矩阵默认按列生成 > test_matrix
> cells <-c(1,26,24,68) > new_matrix<-matrix(cells,nrow=2,ncol=2,byrow=FALSE,dimnames = list(rnames,cnames)) #按列填充的2*2矩阵 |
| x[i,]指矩阵x中的第i行,x[,j]指矩阵x中的第j列,x[i,j]指第i行第j列的元素,选择多行或多列时可用数值型向量如x[i,c(m,n)]为第i行第m,n列的元素 |
| 与矩阵相关的函数dim() 返回维度属性,几行几列 > dim(test_matrix) test_matrix为5行4列的矩阵 attribues()#返回一个列表,第一个元素为dim元素即一个包含dim元素的向量 > attributes(test_matrix) |
| 矩阵还可以通过对已有向量添加维度属性来创建 > existing_vextor<-1:10 #已存在向量 > existing_vextor |
| 还可以通过绑定行或列来生成 cbind()#绑定列来生成矩阵 rbind()#绑定行来生成矩阵 > a<-1:4 |
2.4数组
维度大于2时就不建议使用矩阵了,建议使用数组。
使用array()函数创建,形式如下
| this_is_a_array<-array(vector,dimensions,dimnames) |
| vector包含了数组中的数据,dimensions是一个数值型向量,给出了各个维度下标的最大值,而dimnames是可选的、各个维度名称标签的列表。 |
| #创建一个三维(2*3*4)数值型数组 > name2<-c("B1","B2","B3") B1 B2 B3 , , C2 B1 B2 B3 , , C3 B1 B2 B3 , , C4 B1 B2 B3 |
| #选取元素方式与矩阵相同,this_is_a_array[1,2,3]对应15 |
2.5数据框
从结构上来看,与矩阵是相似的。由于不同的列可包含多种数据类型,数据框较矩阵更加一般。在R中非常常用。之前的那个表由于包含了数值型和字符型数据等不同种数据,不能使用矩阵,这种情况下(存储表格数据),使用数据框是最佳选择。
使用data.frame()函数创建数据框
| this_is_a_dataframe<-data.frame(col1,col2,col3,…) | ||||||
| 列向量col1,col2,col3,…可为任意类型(如字符型,数值型或逻辑型)。但列向量类型必须唯一 | ||||||
| > ID<-c(1,2) > nrow(student_data)#返回行数 | ||||||
| 选取数据框中元素的方式有若干种,既可以使用前述下标记号student_data[2,3],也可以直接指定列名 > student_data[1,2] | ||||||
| 如果想生成sex与department的列联表 > table(student_data$sex,student_data$department)
| ||||||
| 可能会注意到,每次都要在变量名之前添上student_data$不免麻烦,其实可以借助attach()、detach()函数或者单独使用with()函数来简化代码。
下面介绍实例标识符,用于区分数据集中不同的个体。可通过数据框操作函数row.names()指定。例如this_is_a_dataframe<-data.frame(col1,col2,col3,row.names=col2) 将col2指定为R中标记各类打印输出和图形中实例名称所用的变量 > plot(col2,this_is_a_dataframe$col3) |
2.6因子
有开头的表格例子可以看出,在变量逻辑性质上可以将变量分为名义型、有序型或连续型变量。
- 名义型变量是没有顺序之分的类别变量,如"院系"中可以将信息学院编号为1,工学院编为2但并不意味着二者有序。
- 有序型变量则表示顺序关系,而非数量关系。如"年级"中的大一大二大三,大三已学的东西最多大二次之大一最少,然而并不知道学的到底差多少。
- 连续型变量可以呈现某个范围内的任意值,并同时表示了顺序和数量。如"年龄"可以表示18岁到22岁之间的任意值包括18.8或者21.5这样的小数。不像有序性变量大一大二,在连续型变量中我们可以清楚知道19岁比18岁大一岁
于是引出因子的概念,R中的因子即为类别(名义型)变量和有序类别(有序型)变量。因子决定了数据的分析方式以及如何进行视觉呈现。
函数factor()以一整数向量的形式存储类别值,整数的取值范围是[1…k]其中k是名义型变量中唯一值的个数,同时一个由字符串(原始值)组成的内部向量将映射到这些整数上。
例如
| 设向量college_department<-c("xinxi","gongxue","zhibao","xinxi") college_department<-factor(college_department)将此向量存储为(1,2,3,1) 并在内部将关联设为1=xinxi,2=gongxue,3=植保 现在针对college_deparment的分析均会以名义型变量对待。 |
| 如要表示有序型变量,需要为函数factor()指定参数ordered=TRUE grade<-c("freshman","sophomore","junior","senior","freshman") grade<-factor(grade,ordered=TRUE)会将向量编码为(1,4,2,3,1),然而这并不是我们想要的顺序,原因是字符型向量因子按照字符串比较(先字母顺序再字符串长度)来分的顺序。我们可人为标号来保证顺序 grade<-c("4senior","3junior","2sophomore","1freshman","1freshman") 或者通过levels命令来覆盖默认顺序 grade<-factor(grade,ordered=TRUE,levels=c("freshman","sophomore","junior","senior")) 现在针对grade的分析均会以有序型变量对待。 |
| 给出示例 #以向量形式输入数据 > sex<-c("male","male","male","female","female") > college_department<-c("xinxi","gongxue","dongke","zhibao","xinxi") > grade<-c("freshman","sophomore","junior","senior","freshman") #显示对象的结构 > str(student_data) $ grade : Ord.factor w/ 4 levels "freshman"<"sophomore"<..: 1 2 3 4 1 #显示对象的统计概要 > summary(student_data) #显示关系图表 5 5 female 17 xinxi freshman |
提示:
- str()函数提供R某个具体对象(示例中的student_data)的信息,示例中str函数就很清楚得显示出college_department是因子,grade是有序型因子,以及他们的编码顺序
- summary()区别对待各个变量,它显示了连续型变量age的最大值最小值均值以及各四分位数,对于类别型变量college_department和grade则显示了各水平的频数值。
| 再举一个例子 |
| > a<-c("yes","yes","ok","no","no","maybe") [1] yes yes ok no no maybe x > unclass(x)#移除一个向量的类型,此语句会将x变为一个整型向量,这个函数帮助你了解因子在R中是如何被编码的 [1] 4 4 3 2 2 1 > xx<-factor(a,ordered=TRUE,levels=c("no","maybe","ok","yes")) > xx > unclass(xx) > xx<-factor(a,levels=c("no","maybe","ok","yes")) xx > unclass(xx)#如果不加ordered=TRUE内部编码不会变 |
2.7列表
非常重要的数据类型,形似向量,然而兼容性更好,可以包括若干不同类型的元素
| > h<-c(18,18,18,19,17) [[2]] [[3]] $age [[5]] [[6]] |
双重方括号可以用来查找列表元素,而查找时不光可以使用元素顺序值,还可以使用名称(如果设定了的话,如age)















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









