










Few-Shot Unsupervised Image-to-Image Translation

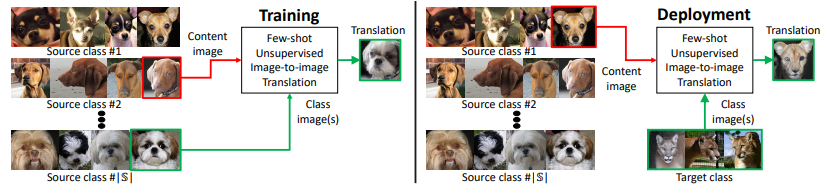
Fig. 1 Training. The training set consists of images of various object classes (source classes). We train a model to translate images between these source object classes. Deployment. We show our trained model very few images of the target class, which is sufficient to translate images of source classes to analogous images of the target class even though the model has never seen a single image from the target class during training. Note that the FUNIT generator takes two inputs: 1) a content image and 2) a set of target class images. It aims to generate a translation of the input image that resembles images of the target class.
目录
Few-Shot Unsupervised Image-to-Image Translation
Multi-task Adversarial Discriminator
Abstract
Unsupervised image-to-image translation methods learn to map images in a given class to an analogous image in a different class, drawing on unstructured (non-registered) datasets of images.
While remarkably successful, current methods require access to many images in both source and destination classes at training time. We argue this greatly limits their use.
Drawing inspiration from the human capability of picking up the essence of a novel object from a small number of examples and generalizing from there, we seek a few-shot, unsupervised image-to-image translation algorithm that works on previously unseen target classes that are specified, at test time, only by a few example images.
Our model achieves this few-shot generation capability by coupling an adversarial training scheme with a novel network design.
Through extensive experimental validation and comparisons to several baseline methods on benchmark datasets, we verify the effectiveness of the proposed framework. Our implementation and datasets are available at https://github.com/NVlabs/FUNIT.
第一句,背景解释:什么是 Unsupervised Image-to-Image Translation(废话)。
第二、三句,提出问题:虽然目前的方法非常成功,但需要在训练时同时访问源和目标类中的许多图像。我们认为这极大地限制了它们的使用。
第四句,motivation:人类从少量例子中获取新事物的本质并从中归纳的能力,本文根据这个启发,提出了 few-shot 非监督方法,在测试时,仅对几个示例图像指定的、以前未看到的 目标类上进行图像翻译(这句话有点难理解,其实就是说,测试时提供少量的 目标类别,而这些 类别 是在训练时没有出现过的类别)。
第五句,算法简述:将对抗学习与一种新的网络设计相结合 实现算法,称之为 FUNIT。
最后两句,实验结论:。。。。
Overview of the FUNIT
The proposed FUNIT framework aims at mapping an image of a source class to an analogous image of an unseen target class by leveraging a few target class images that are made available at test time.
To train FUNIT, we use images from a set of object classes (e.g. images of various animal species), called the source classes. We do not assume existence of paired images between any two classes (i.e. no two animals of different species are at exactly the same pose). We use the source class images to train a multi-class unsupervised image-to-image translation model.
During testing, we provide the model few images from a novel object class, called the target class. The model has to leverage the few target images to translate any source class image to analogous images of the target class. When we provide the same model few images from a different novel object class, it has to translate any source class images to analogous images of the different novel object class.
FUNIT 的目的:在测试时,将输入图像从源类别转换到给定类别,这些给定类别是在训练时没有出现过的。
训练时:训练样本是非配对的,利用源类图像训练一个多类无监督图像-图像转换模型。
测试时:给定的图像类别是训练时没出现过的。
Our framework consists of a conditional image generator G and a multi-task adversarial discriminator D. Unlike the conditional image generators in existing unsupervised image-to-image translation frameworks [55, 29], which take one image as input, our generator G simultaneously takes a content image x and a set of K class images {y1, ..., yK} as input and produce the output image x¯ via
We assume the content image belongs to object class cx while each of the K class images belong to object class cy. In general, K is a small number and cx is different from cy. We will refer G as the few-shot image translator.
传统的非监督条件生成器:一张输入图片;
本文的生成器:一张内容图片 x 和一个类别图像集合 K。
x 的类别与 K 中所有类别都不同。
As shown in Figure 1, G maps an input content image x to an output image x¯, such that x¯ looks like an image belonging to object class cy, and x¯ and x share structural similarity. Let
and
denote the set of source classes and the set of target classes, respectively. During training, G learns to translate images between two randomly sampled source classes cx, cy ∈
cy. At test time, G takes a few images from an unseen target class c ∈
Few-shot Image Translator
The few-shot image translator G consists of a content encoder Ex, a class encoder Ey, and a decoder Fx. The content encoder is made of several 2D convolutional layers followed by several residual blocks [16, 22]. It maps the input content image x to a content latent code zx, which is a spatial feature map. The class encoder consists of several 2D convolutional layers followed by a mean operation along the sample axis. Specifically, it first maps each of the K individual class images {y1, ..., yK} to an intermediate latent vector and then computes the mean of the intermediate latent vectors to obtain the final class latent code zy.
这段没啥可翻译的,描述了网络结构,如下图。
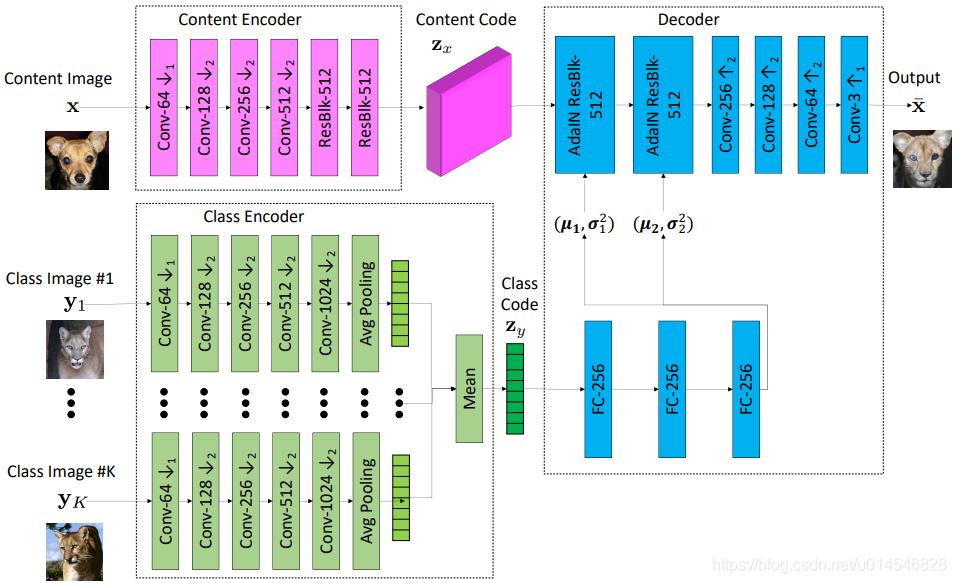
Figure 6. Visualization of the generator architecture. To generate a translation output x¯, the translator combines the class latent code zy extracted from the class images y1, ...yK with the content latent code zx extracted from the input content image. Note that nonlinearity and normalization operations are not included in the visualization.
The decoder consists of several adaptive instance normalization (AdaIN) residual blocks [19] followed by a couple of upscale convolutional layers. The AdaIN residual block is a residual block using the AdaIN [18] as the normalization layer. For each sample, AdaIN first normalizes the activations of a sample in each channel to have a zero mean and unit variance. It then scales the activations using a learned affine (仿射) transformation consisting of a set of scalars and biases. Note that the affine transformation is spatially invariant and hence can only be used to obtain global appearance information. The affine transformation parameters are adaptively computed using zy via a two-layer fully connected network.
解码器中的前两层用了 AdaIN 网络,参考链接:(ICCV 2017) Arbitrary style transfer in real-time with adaptive instance normalization
注意,仿射变换是空间不变量,因此只能用于获取全局外观信息。通过两层全连通网络,利用zy自适应计算仿射变换参数。
With Ex, Ey, and Fx, (1) becomes
By using this translator design, we aim at extracting classinvariant latent representation (e.g., object pose) using the content encoder and extracting class-specific latent representation (e.g., object appearance) using the class encoder. By feeding the class latent code to the decoder via the AdaIN layers, we let the class images control the global look (e.g., object appearance), while the content image determines the local structure (e.g., locations of eyes)
通过使用这种转换器设计,其目标是使用内容编码器提取 类不变的潜在表示 (例如,对象姿态),使用类编码器提取 类特定的潜在表示 (例如,对象外观)。通过AdaIN层将类的潜在代码提供给解码器,让类图像控制 全局外观 (例如,对象外观),而内容图像决定 局部结构 (例如,眼睛的位置)
Multi-task Adversarial Discriminator
Our discriminator D is trained by solving multiple adversarial classification tasks simultaneously. Each of the tasks is a binary classification task determining whether an input image is a real image of the source class or a translation output coming from G. As there are
多任务判别器是通过同时解决多个对抗分类任务来训练的。每个任务都是一个二值分类任务,确定输入图像是源类的真实图像还是来自生成器的转换输出。由于有 源类,D 产生 输出。
Loss Functions
We train the proposed FUNIT framework by solving a minimax optimization problem given by
where LGAN, LR, and LF are the GAN loss, the content image reconstruction loss, and the feature matching loss.
三个损失函数:GAN,L1,和 特征匹配损失。
这里要注意 L1,可不是直接拿输出与所谓的 GT 比较,这里没有 GT。那怎么用 L1 损失呢?
The content reconstruction loss helps G learn a translation model. Specifically, when using the same image for both the input content image and the input class image (in this case K = 1), the loss encourages G to generate an output image identical to the input
这里,让 类别图像 与 内容图像 相同就可以了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









