







决策树构造的输入是一组带有类别标记的例子,构造的结果是一棵二叉树或多叉树。二叉树的内部节点(非叶子节点)一般表示为一个逻辑判断,如形式为a=a_j的逻辑判断,其中a是属性,a_j是该属性的所有取值:树的边是逻辑判断的分支结果。多叉树(ID3)的内部结点是属性,边是该属性的所有取值,有几个属性值就有几条边。树的叶子节点都是类别标记。
由于数据表示不当、有噪声或者由于决策树生成时产生重复的子树等原因,都会造成产生的决策树过大。因此,简化决策树是一个不可缺少的环节。寻找一棵最优决策树,主要应解决以下3个最优化问题:①生成最少数目的叶子节点;②生成的每个叶子节点的深度最小;③生成的决策树叶子节点最少且每个叶子节点的深度最小。
ID3算法是一种经典的决策树算法,它从根节点开始,根节点被赋予一个最好的属性。随后对该属性的每个取值都生成相应的分支,在每个分支上又生成新的节点。对于最好的属性的选择标准,ID3采用基于信息熵定义的信息增益来选择内节点的测试属性,熵(Entropy)刻画了任意样本集的纯度。
ID3算法存在的缺点:(1)ID3算法在选择根节点和内部节点中的分支属性时,采用信息增益作为评价标准。信息增益的缺点是倾向于选择取值较多是属性,在有些情况下这类属性可能不会提供太多有价值的信息。(2)ID3算法只能对描述属性为离散型属性的数据集构造决策树。
ID3算法的目的在于减少树的深度。但是忽略了叶子数目的研究。C4.5算法在ID3算法的基础上进行了改进,对于预测变量的缺值处理、剪枝技术、派生规则等方面作了较大的改进,既适合于分类问题,又适合于回归问题。
C4.5算法主要做出了以下方面的改进:
(1) 用信息增益率来选择属性
克服了用信息增益来选择属性时偏向选择值多的属性的不足。信息增益率定义为:
GainRatio(S,A) = Gain(S,A)/ SplitInfo(S,A)
其中,Grain(S,A)与ID3算法中的信息增益相同,而分裂信息SplitInfo(S, A)代表了按照属性A分裂样本集S的广度和均匀性。
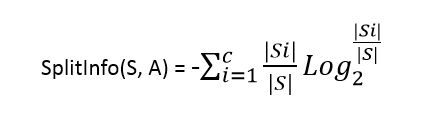
其中,S1到Sc是c个不同值的属性A分割S而形成的c个样本子集。如按照属性A把S集(含30个用例)分成了10个用例和20个用例两个集合,则SplitInfo(S,A)=-1/3*log(1/3)-2/3*log(2/3)。
(2) 可以处理连续数值型属性
C4.5算法既可以处理离散型描述属性,也可以处理连续性描述属性。在选择某节点上的分枝属性时,对于离散型描述属性,C4.5算法的处理方法与ID3相同,按照该属性本身的取值个数进行计算;对于某个连续性描述属性Ac,假设在某个节点上的数据集的样本数量为total,C4.5算法将作以下处理:
l 将该节点上的所有数据样本按照连续型描述的属性的具体数值,由小到大进行排序,得到属性值的取值序列{A1c,A2c,……Atotalc}。
l 在取值序列生成total-1个分割点。第i(0<i<total)个分割点的取值设置为Vi=(Aic+A(i+1)c)/2,它可以将该节点上的数据集划分为两个子集。
l 从total-1个分割点中选择最佳分割点。对于每一个分割点划分数据集的方式,C4.5算法计算它的信息增益比,并且从中选择信息增益比最大的分割点来划分数据集。
C4.5采用的是信息增益率(Gain Ratio)作为分裂准则,并且能处理连续属性,在C4.5中,对连续属性的处理如下:
1. 对属性的取值进行排序
2. 两个属性取值之间的中点作为可能的分裂点,将数据集分成两部分,计算每个可能的分裂点的信息增益(InforGain)
3. 对每个分裂点的信息增益(InforGain)就行修正:减去log2(N-1)/|D|
4. 选择修正后信息增益(InforGain)最大的,分裂点作为该属性的最佳分裂点
5. 计算最佳分裂点的信息增益率(Gain Ratio)作为属性的Gain Ratio
6. 选择Gain Ratio最大的属性作为分裂属性
其中,3,4两点在93年Quinlan的C4.5算法中并没有体现,后来Quinlan在96年发表文章,对C4.5进行了改进,这两点是主要的修改。Quinlan的主要理由是数据集中同时出现连续属性和离散属性时,原始的C4.5算法倾向于选择连续的属性作为分裂属性,因此连续属性的信息增益需要减去log2(N-1)/|D|作为修正,其中N为可能的分裂点个数,|D|是数据集大小。第二个修改是,选择最佳分裂点不用信息增益率(Gain Ratio),而用信息增益(Information Gain),然后用最大的信息增益对应的Gain Ratio作为属性的Gain Ratio.
(3) 采用了一种后剪枝方法
避免树的高度无节制的增长,避免过度拟合数据,该方法是用训练样本本身来估计剪枝前后的误差,从而决定是否真正剪枝。方法中使用的公式如下:
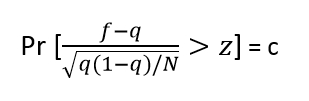
其中N是实例的数量,f=E/N为观察到的误差率(其中E为N个实例中分类错误的个数),q为真实的误差率,c为置信度(C4.5算法的一个熟人参数,默认值为0.25),z为对应于置信度c的标准差,其值可根据c的设定值通过查正态分布表得到。通过该公式即可计算出真实误差率q的一个置信区间上限,用此上限为该节点误差率e做一个悲观的估计:
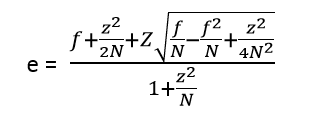
通过判断剪枝前后e的大小,从而决定是否需要剪枝。
(4) 对于缺失值的处理
在某些情况下,可供使用的数据可能缺少某些属性的值。假如<x,c(x)>是样本集S中的一个训练实例,但是其属性A的值A(x)未知。处理缺少属性值的一种策略是赋给它节点n所对应的训练实例中该属性的最常见值;另外一种更复杂的策略是为A的每个可能值赋予一个概率。例如,给定一个布尔属性A,如果结点n包含6个已知A=1和4个A=0的实例,那么A(x)=1的概率是0.6,而A(x)=0的概率是0.4。于是,实例x的60%被分配到A=1的分支,40%被分配到另一个分支。这些片断样例(fractional examples)的目的是计算信息增益,另外,如果有第二个缺失值的属性必须被测试,这些样例可以在后继的树分支中被进一步细分。C4.5就是使用这种方法处理缺少的属性值
C4.5算法的优点是产生的分类规则易于理解,准确率较高。缺点就是在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效。此外,C4.5算法只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时,程序无法运行。
1、C4.5算法的实现
假设用S代表当前样本集,当前候选属性集用A表示,则C4.5算法C4.5formtree(S, A)的伪代码如下。
算法:Generate_decision_tree由给定的训练数据产生一棵决策树
输入:训练样本samples;候选属性的集合attributelist
输出:一棵决策树
(1) 创建根节点N;
(2) IF S都属于同一类C,则返回N为叶节点,标记为类C;
(3) IF attributelist为空 OR S中所剩的样本数少于某给定值
则返回N为叶节点,标记N为S中出现最多的类;
(4) FOR each attributelist中的属性
计算信息增益率information gain ratio;
(5) N的测试属性test.attribute = attributelist具有最高信息增益率的属性;
(6) IF测试属性为连续型
则找到该属性的分割阈值;
(7) For each由节点N一个新的叶子节点{
If该叶子节点对应的样本子集S’为空
则分裂此叶子节点生成新叶节点,将其标记为S中出现最多的类
Else
在该叶子节点上执行C4.5formtree(S’, S’.attributelist),继续对它分裂;
}
(8) 计算每个节点的分类错误,进行剪枝。
<span style="font-size:18px;">// C4.5_test.cpp : Defines the entry point for the console application.
//
#include "stdafx.h"
#include <stdio.h>
#include <math.h>
#include "malloc.h"
#include <stdlib.h>
const int MAX = 10;
int** iInput;
int i = 0;//列数
int j = 0;//行数
void build_tree(FILE *fp, int* iSamples, int* iAttribute, int ilevel);//输出规则
int choose_attribute(int* iSamples, int* iAttribute);//通过计算信息增益率选出test_attribute
double info(double dTrue, double dFalse);//计算期望信息
double entropy(double dTrue, double dFalse, double dAll);//求熵
double splitinfo(int* list, double dAll);
int check_samples(int *iSamples);//检查samples是否都在同一个类里
int check_ordinary(int *iSamples);//检查最普通的类
int check_attribute_null(int *iAttribute);//检查attribute是否为空
void get_attributes(int *iSamples, int *iAttributeValue, int iAttribute);
int _tmain(int argc, _TCHAR* argv[])
{
FILE *fp;
FILE *fp1;
char iGet;
int a = 0;
int b = 0;//a,b是循环变量
int* iSamples;
int* iAttribute;
fp = fopen("c:\\input.txt", "r");
if (NULL == fp)
{
printf("error\n");
return 0;
}
iGet = getc(fp);
while (('\n' != iGet) && (EOF != iGet))
{
if (',' == iGet)
{
i++;
}
iGet = getc(fp);
}
i++;
iAttribute = (int *)malloc(sizeof(int)*i);
for (int k = 0; k < i; k++)
{
iAttribute[k] = (int)malloc(sizeof(int));
iAttribute[k] = 1;
}
while (EOF != iGet)
{
if ('\n' == iGet)
{
j++;
}
iGet = getc(fp);
}
j++;
iInput = (int **)malloc(sizeof(int*)*j);
iSamples = (int *)malloc(sizeof(int)*j);
for (a = 0; a < j; a++)
{
iInput[a] = (int *)malloc(sizeof(int)*i);
iSamples[a] = (int)malloc(sizeof(int));
iSamples[a] = a;
}
a = 0;
fclose(fp);
fp = fopen("c:\\input.txt", "r");
iGet = getc(fp);
while (EOF != iGet)
{
if ((',' != iGet) && ('\n' != iGet))
{
iInput[a][b] = iGet - 48;
b++;
}
if (b == i)
{
a++;
b = 0;
}
iGet = getc(fp);
}
fp1 = fopen("d:\\output.txt", "w");
build_tree(fp1, iSamples, iAttribute, 0);
fclose(fp);
return 0;
}
void build_tree(FILE * fp, int* iSamples, int* iAttribute, int level)//
{
int iTest_Attribute = 0;
int iAttributeValue[MAX];
int k = 0;
int l = 0;
int m = 0;
int *iSamples1;
for (k = 0; k < MAX; k++)
{
iAttributeValue[k] = -1;
}
if (0 == check_samples(iSamples))
{
fprintf(fp, "result: %d\n", iInput[iSamples[0]][i - 1]);
return;
}
if (1 == check_attribute_null(iAttribute))
{
fprintf(fp, "result: %d\n", check_ordinary(iSamples));
return;
}
iTest_Attribute = choose_attribute(iSamples, iAttribute);
iAttribute[iTest_Attribute] = -1;
get_attributes(iSamples, iAttributeValue, iTest_Attribute);
k = 0;
while ((-1 != iAttributeValue[k]) && (k < MAX))
{
l = 0;
m = 0;
while ((-1 != iSamples[l]) && (l < j))
{
if (iInput[iSamples[l]][iTest_Attribute] == iAttributeValue[k])
{
m++;
}
l++;
}
iSamples1 = (int *)malloc(sizeof(int)*(m + 1));
l = 0;
m = 0;
while ((-1 != iSamples[l]) && (l < j))
{
if (iInput[iSamples[l]][iTest_Attribute] == iAttributeValue[k])
{
iSamples1[m] = iSamples[l];
m++;
}
l++;
}
iSamples1[m] = -1;
if (-1 == iSamples1[0])
{
fprintf(fp, "result: %d\n", check_ordinary(iSamples));
return;
}
fprintf(fp, "level%d: %d = %d\n", level, iTest_Attribute, iAttributeValue[k]);
build_tree(fp, iSamples1, iAttribute, level + 1);
k++;
}
}
int choose_attribute(int* iSamples, int* iAttribute)
{
int iTestAttribute = -1;
int k = 0;
int l = 0;
int m = 0;
int n = 0;
int iTrue = 0;
int iFalse = 0;
int iTrue1 = 0;
int iFalse1 = 0;
int iDepart[MAX];
int iRecord[MAX];
double dEntropy = 0.0;
double dGainratio = 0.0;
double test = 0.0;
for (k = 0; k < MAX; k++)
{
iDepart[k] = -1;
iRecord[k] = 0;
}
k = 0;
while ((l != 2) && (k < (i - 1)))
{
if (iAttribute[k] == -1)
{
l++;
}
k++;
}
if (l == 1)
{
for (k = 0; k < (k - 1); k++)
{
if (iAttribute[k] == -1)
{
return iAttribute[k];
}
}
}
for (k = 0; k < (i - 1); k++)
{
l = 0;
iTrue = 0;
iFalse = 0;
if (iAttribute[k] != -1)
{
while ((-1 != iSamples[l]) && (l < j))
{
if (0 == iInput[iSamples[l]][i - 1])
{
iFalse++;
}
if (1 == iInput[iSamples[l]][i - 1])
{
iTrue++;
}
l++;
}
for (n = 0; n < l; n++)//计算该属性有多少不同的值并记录
{
m = 0;
while ((iDepart[m] != -1) && (m != MAX))
{
if (iInput[iSamples[n]][iAttribute[k]] == iDepart[m])
{
break;
}
m++;
}
if (-1 == iDepart[m])
{
iDepart[m] = iInput[iSamples[n]][iAttribute[k]];
}
}
while ((iDepart[m] != -1) && (m != MAX))
{
for (n = 0; n < l; n++)
{
if (iInput[iSamples[n]][iAttribute[k]] == iDepart[m])
{
if (1 == iInput[iSamples[n]][i - 1])
{
iTrue1++;
}
if (0 == iInput[iSamples[n]][i - 1])
{
iFalse1++;
}
iRecord[m]++;
}
}
dEntropy += entropy((double)iTrue1, (double)iFalse1, (double)l);
iTrue1 = 0;
iFalse1 = 0;
m++;
}
double dSplitinfo = splitinfo(iRecord, (double)l);
if (-1 == iTestAttribute)
{
iTestAttribute = k;
dGainratio = (info((double)iTrue, (double)iFalse) - dEntropy) / dSplitinfo;
}
else
{
test = (info((double)iTrue, (double)iFalse) - dEntropy) / dSplitinfo;
if (dGainratio < test)
{
iTestAttribute = k;
dGainratio = test;
}
}
}
}
return iTestAttribute;
}
double info(double dTrue, double dFalse)
{
double dInfo = 0.0;
dInfo = ((dTrue / (dTrue + dFalse))*(log(dTrue / (dTrue + dFalse)) / log(2.0)) + (dFalse / (dTrue + dFalse))*(log(dFalse / (dTrue + dFalse)) / log(2.0)))*(-1);
return dInfo;
}
double entropy(double dTrue, double dFalse, double dAll)
{
double dEntropy = 0.0;
dEntropy = (dTrue + dFalse)*info(dTrue, dFalse) / dAll;
return dEntropy;
}
double splitinfo(int* list, double dAll)
{
int k = 0;
double dSplitinfo = 0.0;
while (0 != list[k])
{
dSplitinfo -= ((double)list[k] / (double)dAll)*(log((double)list[k] / (double)dAll));
k++;
}
return dSplitinfo;
}
int check_samples(int *iSamples)
{
int k = 0;
int b = 0;
while ((-1 != iSamples[k]) && (k < j - 1))
{
if (iInput[k][i - 1] != iInput[k + 1][i - 1])
{
b = 1;
break;
}
k++;
}
return b;
}
int check_ordinary(int *iSamples)
{
int k = 0;
int iTrue = 0;
int iFalse = 0;
while ((-1 != iSamples[k]) && (k < i))
{
if (0 == iInput[iSamples[k]][i - 1])
{
iFalse++;
}
else
{
iTrue++;
}
k++;
}
if (iTrue >= iFalse)
{
return 1;
}
else
{
return 0;
}
}
int check_attribute_null(int *iAttribute)
{
int k = 0;
while (k < (i - 1))
{
if (-1 != iAttribute[k])
{
return 0;
}
k++;
}
return 1;
}
void get_attributes(int *iSamples, int *iAttributeValue, int iAttribute)
{
int k = 0;
int l = 0;
while ((-1 != iSamples[k]) && (k < j))
{
l = 0;
while (-1 != iAttributeValue[l])
{
if (iInput[iSamples[k]][iAttribute] == iAttributeValue[l])
{
break;
}
l++;
}
if (-1 == iAttributeValue[l])
{
iAttributeValue[l] = iInput[iSamples[k]][iAttribute];
}
k++;
}
}
</span>大家可以去看看C4.5决策树提出者J. R. Quinlan的原论文















 4429
4429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









