









1.创建hadoop用户组
sudo addgroup hadoop2.创建hadoop用户
sudo adduser -ingroup hadoop hadoop回车后会提示输入新的UNIX密码,这是新建用户hadoop的密码,输入回车即可。即密码不能为空。
最后确认信息是否正确,如果没问题,输入 Y
3、为hadoop用户添加权限
sudo gedit /etc/sudoers如果没有图形界面,可以用vim编辑
sudo vi /etc/sudoers将
# User privilege specification
root ALL=(ALL:ALL) ALL下添加一行,改为
# User privilege specification
root ALL=(ALL:ALL) ALL
hadoop ALL=(ALL:ALL) ALL4.使用hadoop用户登录ubuntu系统
5.安装ssh
sudo apt-get install openssh-server启动ssh
sudo /etc/init.d/ssh start #启动ssh
ps -e | grep ssh #观察ssh是否启动
6.设置ssh免密码登录,生成私钥和公钥
ssh-keygen -t rsa -P ""此时会在/home/hadoop/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,后者为公钥。
下面我们将公钥追加到authorized_keys中,它用户保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys登录ssh
ssh localhost #登录ssh
exit #退出7.安装 Java
sudo add-apt-repository ppa:webupd8team/java #添加库
sudo apt-get update #更新库
sudo apt-get install oracle-java8-installer #安装java8
java -version #查看java版本8.安装hadoop2.7.2
# 下载hadoop
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz
# 解压
sudo tar xzf hadoop-2.7.2.tar.gz
# 将hadoop拷贝到/usr/local/hadoop下
sudo mv hadoop-2.7.2 /usr/local/hadoop
# 赋予用户对该文件夹的读写权限
sudo chmod 774 /usr/local/hadoop
# 配置.bashrc文件
sudo gedit ~/.bashrc在文件末尾追加下面内容。主要需要注意的就是JAVA_HOME和HADOOP_INSTALL,一个表示java安装地点,另一个表示hadoop安装地点
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export HADOOP_INSTALL=/usr/local/hadoop
export PATH=$PATH:$HADOOP_INSTALL/bin
export PATH=$PATH:$HADOOP_INSTALL/sbin
export HADOOP_MAPRED_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_HOME=$HADOOP_INSTALL
export HADOOP_HDFS_HOME=$HADOOP_INSTALL
export YARN_HOME=$HADOOP_INSTALL
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
#HADOOP VARIABLES END执行下面命令
source ~/.bashrc #使添加环境变量生效配置 /usr/local/hadoop/etc/hadoop下相应文件
1.hadoop-env.sh 配置如下
找到JAVA_HOME变量,修改此变量为
/usr/lib/jvm/java-8-oracle/jre

2.core-site.xml 配置如下
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/local/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>其中的hadoop.tmp.dir的路径可以根据自己的习惯进行设置。
3.mapred-site.xml.template配置如下:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>4.hdfs-site.xml配置如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/local/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/local/tmp/dfs/data</value>
</property>
</configuration>其中dfs.namenode.name.dir和dfs.datanode.data.dir的路径可以自由设置,最好在hadoop.tmp.dir的目录下面。
9.运行Hadoop
在hadoop的根目录下(在本例中,为/usr/local/hadoop)
bin/hdfs namenode -format #初始化HDFS系统
sbin/start-dfs.sh #开启NameNode和DataNode守护进程
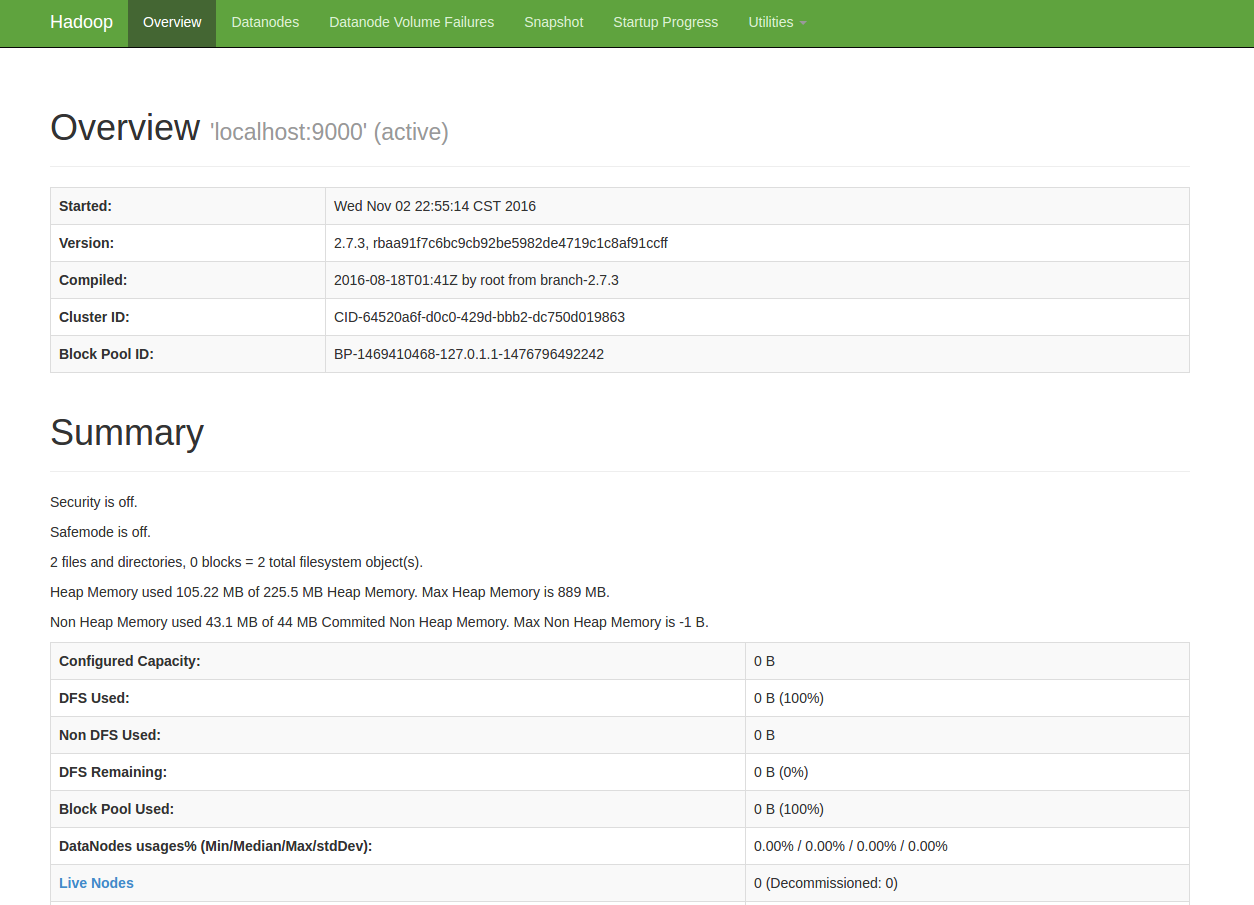
jps #查看进程信息在浏览器中输入 http://localhost:50070,即可查到相关信息,如下图所示
参考链接:
http://www.tuicool.com/articles/bmeUneM
http://www.cnblogs.com/kinglau/p/3794433.html














 5165
5165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









