







文章目录
项目背景
XX作为中国最大的自营式电商,在保持高速发展的同时,沉淀了数亿的忠实用户,积累了海量的真实数据。如何从历史数据中找出规律,去预测用户未来的购买需求,让最合适的商品遇见最需要的人,是机器学习应用在精准营销中的关键问题,也是所有电商平台在做智能化升级时所需要的核心技术。 以XX商城真实的用户、商品和行为数据(脱敏后)为基础,通过数据挖掘的技术和机器学习的算法,构建用户购买商品的预测模型,输出高潜用户和目标商品的匹配结果,为精准营销提供高质量的目标群体。
目标:使用XX多个品类下商品的历史销售数据,构建算法模型,预测用户在未来5天内,对某个目标品类下商品的购买意向。
数据概述
这里涉及到的数据集是XX用户的数据集:
- JData_User.csv 用户数据集 105,321个用户
- JData_Comment.csv 商品评论 558,552条记录
- JData_Product.csv 预测商品集合 24,187条记录
- JData_Action_201602.csv 2月份行为交互记录 11,485,424条记录
- JData_Action_201603.csv 3月份行为交互记录 25,916,378条记录
- JData_Action_201604.csv 4月份行为交互记录 13,199,934条记录
数据挖掘流程
(一)、数据清洗
- 数据集完整性验证
- 数据集中是否存在缺失值
- 数据集中各特征数值应该如何处理
- 哪些数据是我们想要的,哪些是可以过滤掉的
- 将有价值数据信息做成新的数据源
- 去除无行为交互的商品和用户
- 去掉浏览量很大而购买量很少的用户(惰性用户或爬虫用户)
(二)、数据理解与分析
- 掌握各个特征的含义
- 观察数据有哪些特点,是否可利用来建模
- 可视化展示便于分析
- 用户的购买意向是否随着时间等因素变化
(三)、特征提取
- 基于清洗后的数据集哪些特征是有价值
- 分别对用户与商品以及其之间构成的行为进行特征提取
- 行为因素中哪些是核心?如何提取?
- 瞬时行为特征or累计行为特征?
(四)、模型建立
- 使用机器学习算法进行预测
- 参数设置与调节
- 数据集切分?
1、模型导入
import pandas as pd
import numpy as np
import xgboost as xgb
from sklearn.model_selection import train_test_split
from matplotlib import pylab as plt
import gc
2、加载数据
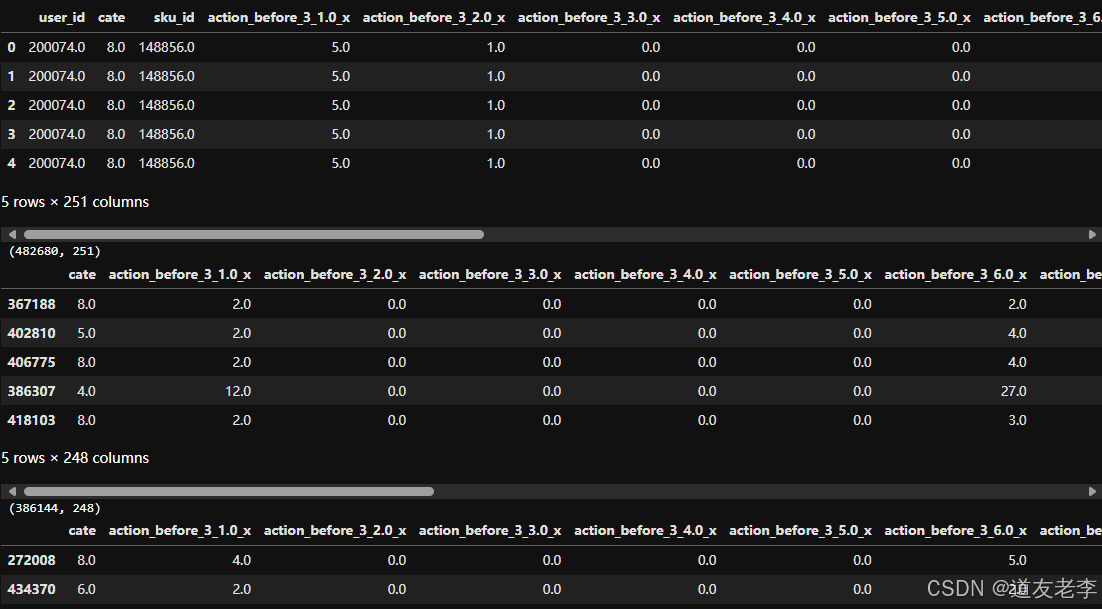
data = pd.read_csv('train_set.csv')
display(data.head(),data.shape)
data_X = data.loc[:,data.columns != 'label']
data_y = data.loc[:,data.columns == 'label']
X_train, X_val, y_train, y_val = train_test_split(data_X,data_y,test_size = 0.2, random_state = 0)
# 删除用户ID和商品编号,这两列属于自然数编号,对预测结果影响不大
del X_train['user_id']
del X_train['sku_id']
display(X_train.head(),X_train.shape)
display(X_val.head(),X_val.shape)
del data,data_X,data_y
gc.collect()
3、Xgboost建模
Xgboost介绍
XGBoost(Extreme Gradient Boosting)是一种优化的分布式梯度提升库,它旨在提供高效的、可扩展的和灵活的解决方案。XGBoost是基于梯度提升决策树(GBDT, Gradient Boosting Decision Trees)算法的一个实现,但它通过引入了一系列创新的技术改进了原始的GBDT,使其在性能、速度和模型质量上都有显著提升。以下是关于XGBoost的一些关键点介绍:
XGBoost的主要特点
- 高效性:
- XGBoost采用了更高效的分裂查找算法,能够快速找到最佳分裂点。
- 支持并行化处理,可以在多核CPU或GPU上加速训练过程。
- 正则化:
- 在损失函数中加入了L1和L2正则项,帮助减少过拟合现象,提高泛化能力。
- 正则化参数可以控制树的复杂度,使得模型更加稳定。
- 自定义目标函数与评估指标:
- 用户可以根据具体问题定义自己的目标函数和评估标准,提供了极大的灵活性。
- 内置了许多常用的目标函数(如回归、分类等)及其对应的评估指标。
- 处理缺失值:
- XGBoost内置了对缺失值的支持,在节点分裂时自动学习最佳方向。
- 这种特性使得它在处理具有不完整特征的数据集时表现优异。
- 剪枝策略:
- 采用了一种称为“预排序”的方法来决定是否进行剪枝,从而提高了计算效率。
- 当树的增长达到一定深度后,如果新增加的叶子节点不能带来足够的增益,则不会继续生长该分支。
- 近似分裂点查找:
- 对于大规模数据集,XGBoost使用了近似的直方图方法来确定分裂点,这大大减少了内存占用并加快了训练速度。
- 交叉验证支持:
- 提供了内置的交叉验证功能,方便用户评估模型性能而不必额外编写代码。
- 多种语言接口:
- XGBoost不仅支持Python,还提供了R、Java、C++等多种编程语言的API,便于不同环境下的集成开发。
- DART (Dropouts meet Multiple Additive Regression Trees):
- DART是一种随机丢弃部分树的方法,类似于神经网络中的dropout技术,有助于防止过拟合并增加模型多样性。
应用场景
XGBoost广泛应用于各种机器学习任务,包括但不限于:
- 分类:二元分类或多类别分类问题。
- 回归:预测连续数值型变量。
- 排序:例如搜索引擎结果排序。
- 异常检测:识别罕见事件或异常情况。
dtrain = xgb.DMatrix(X_train, label=y_train)
dvalid = xgb.DMatrix(X_val, label=y_val)
'''
'min_child_weight': 5,孩子节点中最小的样本权重和。
如果一个叶子节点的样本权重和小于min_child_weight则拆分过程结束。即调大这个参数能够控制过拟合。
gamma = 0.1,# 树的叶子节点上做进一步分区所需的最小损失减少,越大越保守,一般0.1 0.2这样子
scale_pos_weight =10 # 如果取值大于0的话,在类别样本不平衡的情况下有助于快速收敛,平衡正负权重
'eta': 0.1, # 如同学习率'''
param = {'n_estimators': 4000, 'max_depth': 3, 'min_child_weight': 5, 'gamma': 0.1,
'subsample': 0.9,'colsample_bytree': 0.8, 'scale_pos_weight':10, 'eta': 0.1,
'objective': 'binary:logistic','eval_metric':['auc','error']}
num_round = param['n_estimators']
evallist = [(dtrain, 'train'), (dvalid, 'eval')]
bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=10)
bst.save_model('bst.model')
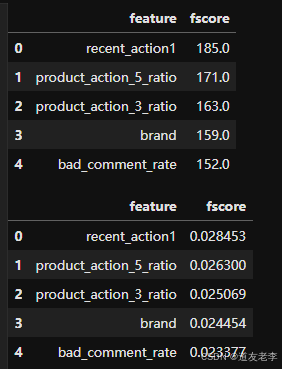
4、特征重要性
def feature_importance(bst_xgb):
importance = bst_xgb.get_fscore()
importance = sorted(importance.items(), key=lambda x:x[1], reverse=True)
df = pd.DataFrame(importance, columns=['feature', 'fscore'])
df['fscore'] = df['fscore'] / df['fscore'].sum()
file_name = 'feature_importance_.csv'
df.to_csv(file_name)
feature_importance(bst)
feature_importance_ = pd.read_csv('feature_importance_.csv')
feature_importance_.head()
5、算法预测验证数据
查看验证数据
X_val.head()

算法预测
users = X_val[['user_id', 'sku_id', 'cate']].copy()
del X_val['user_id']
del X_val['sku_id']
X_val_DMatrix = xgb.DMatrix(X_val)
y_pred = bst.predict(X_val_DMatrix)
X_val['pred_label'] = y_pred
X_val.head()
目标值概率转分类
def label(column):
if column['pred_label'] > 0.5:
column['pred_label'] = 1
else:
column['pred_label'] = 0
return column
X_val = X_val.apply(label,axis = 1)
X_val.head()
添加真实值用户ID商品编号
X_val['true_label'] = y_val
X_val['user_id'] = users['user_id']
X_val['sku_id'] = users['sku_id']
X_val.head()
6、模型评估【验证集】
购买用户统计
# 所有购买用户
all_user_set = X_val[X_val['true_label']==1]['user_id'].unique()
print(len(all_user_set))
# 所有预测购买的用户
all_user_test_set = X_val[X_val['pred_label'] == 1]['user_id'].unique()
print(len(all_user_test_set))
准确率召回率
pos, neg = 0,0
for user_id in all_user_test_set:
if user_id in all_user_set:
pos += 1
else:
neg += 1
all_user_acc = 1.0 * pos / ( pos + neg)
all_user_recall = 1.0 * pos / len(all_user_set)
print ('所有用户中预测购买用户的准确率为 ' + str(all_user_acc))
print ('所有用户中预测购买用户的召回率' + str(all_user_recall))

实际商品对准确率召回率
# 所有预测购买用户商品对应关系
all_user_test_item_pair = X_val[X_val['pred_label'] == 1]['user_id'].map(str) + '-' + X_val[X_val['pred_label'] == 1]['sku_id'].map(str)
all_user_test_item_pair = np.array(all_user_test_item_pair)
print(len(all_user_test_item_pair))
#所有实际商品对
all_user_item_pair = X_val[X_val['true_label']==1]['user_id'].map(str) + '-' + X_val[X_val['true_label']==1]['sku_id'].map(str)
all_user_item_pair = np.array(all_user_item_pair)
pos, neg = 0, 0
for user_item_pair in all_user_test_item_pair:
if user_item_pair in all_user_item_pair:
pos += 1
else:
neg += 1
all_item_acc = 1.0 * pos / ( pos + neg)
all_item_recall = 1.0 * pos / len(all_user_item_pair)
print ('所有用户中预测购买商品的准确率为 ' + str(all_item_acc))
print ('所有用户中预测购买商品的召回率' + str(all_item_recall))

7、测试数据
数据加载
X_data = pd.read_csv('test_set.csv')
display(X_data.head())
X_test,y_test = X_data.iloc[:,:-1],X_data.iloc[:,-1]
算法预测
users = X_test[['user_id', 'sku_id', 'cate']].copy()
del X_test['user_id']
del X_test['sku_id']
X_test_DMatrix = xgb.DMatrix(X_test)
y_pred = bst.predict(X_test_DMatrix)
X_test['pred_label'] = y_pred
X_test.head()
目标值概率转分类
def label(column):
if column['pred_label'] > 0.5:
column['pred_label'] = 1
else:
column['pred_label'] = 0
return column
X_test = X_test.apply(label,axis = 1)
X_test.head()
添加真实用户ID商品编号
X_test['true_label'] = y_test
X_test['user_id'] = users['user_id']
X_test['sku_id'] = users['sku_id']
X_test.head()
8、模型评估【测试集】
购买用户统计
# 所有购买用户
all_user_set = X_test[X_test['true_label']==1]['user_id'].unique()
print(len(all_user_set))
# 所有预测购买的用户
all_user_test_set = X_test[X_test['pred_label'] == 1]['user_id'].unique()
print(len(all_user_test_set))
准确率召回率
pos, neg = 0,0
for user_id in all_user_test_set:
if user_id in all_user_set:
pos += 1
else:
neg += 1
all_user_acc = 1.0 * pos / ( pos + neg)
all_user_recall = 1.0 * pos / len(all_user_set)
print ('所有用户中预测购买用户的准确率为 ' + str(all_user_acc))
print ('所有用户中预测购买用户的召回率' + str(all_user_recall))

实际商品对准确率召回率
# 所有预测购买用户商品对应关系
all_user_test_item_pair = X_test[X_test['pred_label'] == 1]['user_id'].map(str) + '-' + X_test[X_test['pred_label'] == 1]['sku_id'].map(str)
all_user_test_item_pair = np.array(all_user_test_item_pair)
print(len(all_user_test_item_pair))
#所有实际商品对
all_user_item_pair = X_test[X_test['true_label']==1]['user_id'].map(str) + '-' + X_test[X_test['true_label']==1]['sku_id'].map(str)
all_user_item_pair = np.array(all_user_item_pair)
print(len(all_user_item_pair))
pos, neg = 0, 0
for user_item_pair in all_user_test_item_pair:
if user_item_pair in all_user_item_pair:
pos += 1
else:
neg += 1
all_item_acc = 1.0 * pos / ( pos + neg)
all_item_recall = 1.0 * pos / len(all_user_item_pair)
print ('所有用户中预测购买商品的准确率为 ' + str(all_item_acc))
print ('所有用户中预测购买商品的召回率' + str(all_item_recall))




















 1754
1754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











