







 博客围绕XGBoost超参数优化展开。先明确不同参数对算法结果的影响力大小,确定用于搜索的参数空间,如通过绘制学习曲线等方式确定各参数范围。接着基于TEP(TPE贝叶斯优化)对XGBoost进行优化,包括建立基准、定义目标函数等步骤,多次优化后根据结果调整参数空间并验证。
博客围绕XGBoost超参数优化展开。先明确不同参数对算法结果的影响力大小,确定用于搜索的参数空间,如通过绘制学习曲线等方式确定各参数范围。接着基于TEP(TPE贝叶斯优化)对XGBoost进行优化,包括建立基准、定义目标函数等步骤,多次优化后根据结果调整参数空间并验证。
目录
1. 确定XGBoost的参数空间
对任意集成算法进行超参数优化之前,我们需要明确两个基本事实:①不同参数对算法结果的影响力大小;②确定用于搜索的参数空间。对XGBoost来说,各个参数对算法的影响排列大致如下:
| 影响力 | 参数 |
|---|---|
| ⭐⭐⭐⭐⭐ 几乎总是具有巨大影响力 | num_boost_round(整体学习能力) eta(整体学习速率) |
| ⭐⭐⭐⭐ 大部分时候具有影响力 | booster(整体学习能力) colsample_by*(随机性) gamma(结构风险 + 精剪枝) lambda(结构风险 + 间接剪枝) min_child_weight(精剪枝) |
| ⭐⭐ 可能有大影响力 大部分时候影响力不明显 | max_depth(粗剪枝) alpha(结构风险 + 精剪枝) subsamples(随机性) objective(整体学习能力) scale_pos_weight(样本不均衡) |
| ⭐ 当数据量足够大时,几乎无影响 | seed base_score(初始化) |
比起其他树的集成算法,XGBoost有大量通过影响建树过程而影响整体模型的参数(比如gamma,lambda等)。这些参数以较为复杂的方式共同作用、影响模型的最终结果,因此他们的影响力不是线性的,也不总是能在调参过程中明显地展露出来,但调节这些参数大多数时候都能对模型有影响,因此大部分与结构风险相关的参数都被评为4星参数了。相对的,对XGBoost来说总是具有巨大影响力的参数就只有迭代次数与学习率了。
在上述影响力排名当中,需要特别说明以下几点:
-
在随机森林中影响力巨大的
max_depth在XGBoost中默认值为6,比GBDT中的调参空间略大,但还是没有太多的空间,因此影响力不足。 -
在GBDT中影响力巨大的
max_features对标XGBoost中的colsample_by*系列参数,原则上来说影响力应该非常大,但由于三个参数共同作用,调参难度较高,在只有1个参数作用时效果略逊于max_features。 -
精剪枝参数往往不会对模型有太大的影响,但在XGBoost当中,
min_child_weight与结构分数的计算略微相关,因此有时候会展现出较大的影响力。 -
类似于
objective这样影响整体学习能力的参数一般都有较大的影响力,但XGBoost当中每种任务可选的损失函数不多,因此一般损失函数不在调参范围之内,故认为该参数的影响力不明显。 -
XGBoost的初始化分数只能是数字,因此当迭代次数足够多、数据量足够大时,起点的影响会越来越小。因此我们一般不会对base_score进行调参。
在调参的时候,我们首先会考虑所有影响力巨大的参数,当算力足够/优化算法运行较快的时候,我们可以考虑将大部分时候具有影响力的参数也都加入参数空间。一般来说,只要样本量足够,我们还是愿意尝试subsample以及max_depth,如果算力充足,我们还可以加入obejctive这样或许会有效的参数。需要说明的是,一般不会同时使用三个colsample_by*参数、更不会同时调试三个colsample_by*参数。首先,参数colsample_bylevel较为不稳定,不容易把握,因此当训练资源充足时,会同时调整colsample_bytree和colsample_bynode。如果计算资源不足,或者优先考虑节约计算时间,则会先选择其中一个参数、尝试将特征量控制在一定范围内来建树,并观察模型的结果。在这三个参数中,使用bynode在分枝前随机,比使用bytree建树前随机更能带来多样性、更能对抗过拟合,但同时也可能严重地伤害模型的学习能力。
在这样的基本思想下,再结合硬件与运行时间因素,将选择如下参数进行调整,并使用基于TPE贝叶斯优化(HyperOpt)对XGBoost进行优化——
| 参数 |
|---|
num_boost_round |
eta |
booster |
colsample_bynode |
colsample_bytree |
gamma |
lambda |
min_child_weight |
max_depth |
subsamples |
objective |
在此基础上,我们需要进一步确认参数空间:
- 对于有界的参数(比如
colsample_bynode,subsamples等),或者有固定选项的参数(比如booster,objective),无需确认参数空间。
- 对取值较小的参数(例如学习率
eta,一般树模型的min_impurity_decrease等),或者通常会向下调整的参数(比如max_depth),一般是围绕默认值向两边展开构建参数空间。
- 对于取值可大可小,且原则上可取到无穷值的参数(
num_boost_round,gamma、lambda、min_child_weight等),一般需要绘制学习曲线进行提前探索,或者也可以设置广而稀的参数空间,来一步步缩小范围。
现在我们对num_boost_round和min_child_weight参数绘制学习曲线进行轻度探索。如下所示:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import xgboost as xgb
from sklearn.model_selection import cross_validate, KFold
data = pd.read_csv(r"F:\\Jupyter Files\\机器学习进阶\\datasets\\House Price\\train_encode.csv",index_col=0)
X = data.iloc[:,:-1]
y = data.iloc[:,-1]
data_xgb = xgb.DMatrix(X,y)
#定义一个函数,用来检测模型迭代完毕后的过拟合情况
def overfitcheck(result):
return (result.iloc[-1,2] - result.iloc[-1,0]).min()
◆ num_boost_round
train = []
test = []
option = np.arange(10,300,10)
overfit = []
for i in option:
params = {"max_depth":5,"seed":1412,"eta":0.1, "nthread":16
}
result = xgb.cv(params,data_xgb,num_boost_round=i
,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证
,seed=1412 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子
)
overfit.append(overfitcheck(result))
train.append(result.iloc[-1,0])
test.append(result.iloc[-1,2])
plt.plot(option,test);
plt.plot(option,train);
plt.plot(option,overfit);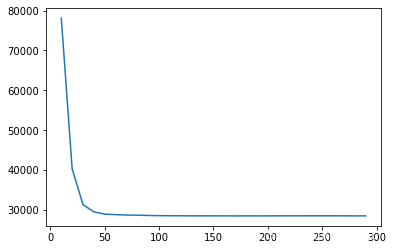
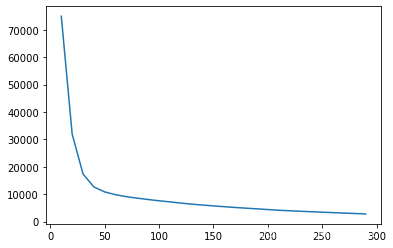
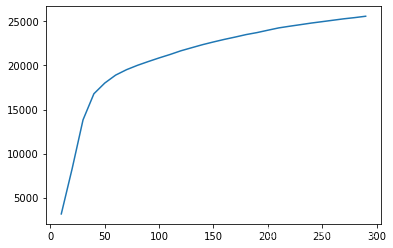
100棵树之后损失几乎没有再下降,因此num_boost_round的范围可以定到range(50,200,10)。
◆ min_child_weight
作为ℎ𝑖值之和,min_child_weight的真实值是可以计算出来的,但精确的计算需要跟随xgboost建树的过程运行,因此比较麻烦。遗憾的是,xgboost官方并未提供调用树结构以及ℎ𝑖值的接口,因此最佳方案其实是对每个叶子上的样本量进行估计。
X.shape #(1460, 80)现在总共有样本1460个,在五折交叉验证中训练集共有1460*0.8 = 1168个样本。由于CART树是二叉树,我们规定的最大深度为5,因此最多有25=3225=32个叶子节点,平均每个叶子结点上的样本量大概为1168/32 = 36.5个。粗略估计,如果min_child_weight是一个小于36.5的值,就可能对模型造成巨大影响。当然,不排除有大量样本集中在一片叶子上的情况,因此我们可以设置备选范围稍微放大,例如设置为[0,100]来观察模型的结果。
train = []
test = []
option = np.arange(0,100,1)
overfit = []
for i in option:
params = {"max_depth":5,"seed":1412,"eta":0.1, "nthread":16
,"min_child_weight":i
}
result = xgb.cv(params,data_xgb,num_boost_round=50
,nfold=5 #补充交叉验证中所需的参数,nfold=5表示5折交叉验证
,seed=1412 #交叉验证的随机数种子,params中的是管理boosting过程的随机数种子
)
overfit.append(overfitcheck(result))
train.append(result.iloc[-1,0])
test.append(result.iloc[-1,2])
plt.plot(option,test);
plt.plot(option,train);
plt.plot(option,overfit);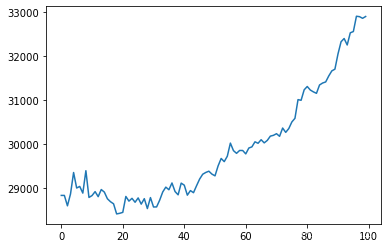
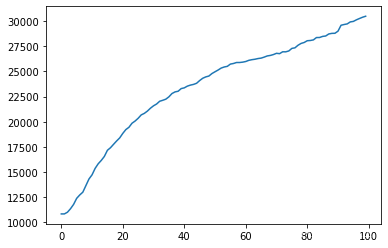

很明显,min_child_weight在0~40的范围之内对测试集上的交叉验证损失有较好的抑制作用,因此我们可以将min_child_weight的调参空间设置为range(0,50,2)来进行调参。
如此,全部参数的参数空间就确定了,如下所示:
| 参数 | 范围 |
|---|---|
num_boost_round | 学习曲线探索,最后定为(50,200,10) |
eta | 以0.3为中心向两边延展,最后定为(0.05,2.05,0.05) |
booster | 两种选项["gbtree","dart"] |
colsample_bytree | 设置为(0,1]之间的值,但由于还有参数bynode,因此整体不宜定得太小,因此定为(0.3,1,0.1) |
colsample_bynode | 设置为(0,1]之间的值,定为(0.1,1,0.1) |
gamma | 学习曲线探索,有较大可能需要改变,定为(1e6,1e7,1e6) |
lambda | 学习曲线探索,定为(0,3,0.2) |
min_child_weight | 学习曲线探索,定为(0,50,2) |
max_depth | 以6为中心向两边延展,右侧范围定得更大(2,30,2) |
subsample | 设置为(0,1]之间的值,定为(0.1,1,0.1) |
objective | 两种回归类模型的评估指标["reg:squarederror", "reg:squaredlogerror"] |
rate_drop | 如果选择"dart"树所需要补充的参数,设置为(0,1]之间的值(0.1,1,0.1) |
一般在初次搜索时,我们会设置范围较大、较为稀疏的参数空间,然后在多次搜索中逐渐缩小范围、降低参数空间的维度。
2. 基于TEP对XGBoost进行优化
import time
import xgboost as xgb
#导入优化算法
import hyperopt
from hyperopt import hp, fmin, tpe, Trials, partial
from hyperopt.early_stop import no_progress_loss
data = pd.read_csv(r"F:\\Jupyter Files\\机器学习进阶\\datasets\\House Price\\train_encode.csv",index_col=0)
X = data.iloc[:,:-1]
y = data.iloc[:,-1]Step 1.建立benchmark
| 算法 | RF (TPE) | AdaBoost (TPE) | GBDT (TPE) |
|---|---|---|---|
| 5折验证 运行时间 | 0.22s | 0.27s | 1.54s(↑) |
| 测试最优分数 (RMSE) | 28346.673 | 35169.730 | 26415.835(↓) |
Step 2.定义目标函数、参数空间、优化函数、验证函数
①目标函数
def hyperopt_objective(params):
paramsforxgb = {"eta":params["eta"]
,"booster":params["booster"]
,"colsample_bytree":params["colsample_bytree"]
,"colsample_bynode":params["colsample_bynode"]
,"gamma":params["gamma"]
,"lambda":params["lambda"]
,"min_child_weight":params["min_child_weight"]
,"max_depth":int(params["max_depth"])
,"subsample":params["subsample"]
,"objective":params["objective"]
,"rate_drop":params["rate_drop"]
,"nthread":14
,"verbosity":0
,"seed":1412}
result = xgb.cv(params,data_xgb, seed=1412, metrics=("rmse")
,num_boost_round=int(params["num_boost_round"]))
return result.iloc[-1,2]②参数空间
param_grid_simple = {'num_boost_round': hp.quniform("num_boost_round",50,200,10)
,"eta": hp.quniform("eta",0.05,2.05,0.05)
,"booster":hp.choice("booster",["gbtree","dart"])
,"colsample_bytree":hp.quniform("colsample_bytree",0.3,1,0.1)
,"colsample_bynode":hp.quniform("colsample_bynode",0.1,1,0.1)
,"gamma":hp.quniform("gamma",1e6,1e7,1e6)
,"lambda":hp.quniform("lambda",0,3,0.2)
,"min_child_weight":hp.quniform("min_child_weight",0,50,2)
,"max_depth":hp.choice("max_depth",[*range(2,30,2)])
,"subsample":hp.quniform("subsample",0.1,1,0.1)
,"objective":hp.choice("objective",["reg:squarederror","reg:squaredlogerror"])
,"rate_drop":hp.quniform("rate_drop",0.1,1,0.1)
}③优化函数
def param_hyperopt(max_evals=100):
#保存迭代过程
trials = Trials()
#设置提前停止
early_stop_fn = no_progress_loss(30)
#定义代理模型
params_best = fmin(hyperopt_objective
, space = param_grid_simple
, algo = tpe.suggest
, max_evals = max_evals
, verbose=True
, trials = trials
, early_stop_fn = early_stop_fn
)
#打印最优参数,fmin会自动打印最佳分数
print("\n","\n","best params: ", params_best,
"\n")
return params_best, trialsStep 3.训练贝叶斯优化器
XGBoost中涉及到前所未有多的随机性,因此模型可能表现得极度不稳定,需要多尝试几次贝叶斯优化来观察模型的稳定性。因此在这里我们完成了多次贝叶斯优化,查看如下的结果:
params_best, trials = param_hyperopt(100)57%|██████████████████████████▊ | 57/100 [05:43<04:18, 6.02s/trial, best loss: 26775.553385333333]
best params: {'booster': 1, 'colsample_bynode': 0.5, 'colsample_bytree': 1.0, 'eta': 0.5, 'gamma': 10000000.0, 'lambda': 1.6, 'max_depth': 2, 'min_child_weight': 0.0, 'num_boost_round': 110.0, 'objective': 0, 'rate_drop': 0.1, 'subsample': 0.7000000000000001}
params_best, trials = param_hyperopt(100) 32%|███████████████ | 32/100 [05:21<11:23, 10.05s/trial, best loss: 26803.143880333333]
best params: {'booster': 1, 'colsample_bynode': 0.9, 'colsample_bytree': 0.4, 'eta': 1.3, 'gamma': 9000000.0, 'lambda': 1.2000000000000002, 'max_depth': 8, 'min_child_weight': 4.0, 'num_boost_round': 180.0, 'objective': 0, 'rate_drop': 0.1, 'subsample': 1.0}
params_best, trials = param_hyperopt(100)52%|████████████████████████▍ | 52/100 [05:26<05:01, 6.29s/trial, best loss: 27745.835937666667]
best params: {'booster': 1, 'colsample_bynode': 0.30000000000000004, 'colsample_bytree': 1.0, 'eta': 2.0, 'gamma': 7000000.0, 'lambda': 0.0, 'max_depth': 8, 'min_child_weight': 2.0, 'num_boost_round': 110.0, 'objective': 0, 'rate_drop': 0.4, 'subsample': 0.7000000000000001}
根据多次迭代情况,首先,objective在所有迭代中都被选为"reg:squarederror",这也是xgboost的默认值,因此不再对该参数进行搜索。同样的。booster参数都被选为"dart",因此基本可以确认对目前的数据使用DART树是更好的选择。对于其他参数,我们则根据搜索结果修改空间范围、增加空间密度,一般让范围向选中更多的一边倾斜,并且减小步长。例如num_boost_round从来没有选到100以下的值,一次接近上限,因此可以将原本的范围(50,200,10)修改为(100,300,10)。colsample_bynode的结果均匀地分布在0.3~1之间,可以考虑不更换范围,但缩小步长。colsample_bytree的结果更多偏向于1.0,因此可以考虑提升下限。其他的参数也以此类推:
Step 4.在此基础上继续调整参数空间
param_grid_simple = {'num_boost_round': hp.quniform("num_boost_round",100,300,10)
,"eta": hp.quniform("eta",0.05,2.05,0.05)
,"colsample_bytree":hp.quniform("colsample_bytree",0.5,1,0.05)
,"colsample_bynode":hp.quniform("colsample_bynode",0.3,1,0.05)
,"gamma":hp.quniform("gamma",5e6,1.5e7,5e5)
,"lambda":hp.quniform("lambda",0,2,0.1)
,"min_child_weight":hp.quniform("min_child_weight",0,10,0.5)
,"max_depth":hp.choice("max_depth",[*range(2,15,1)])
,"subsample":hp.quniform("subsample",0.5,1,0.05)
,"rate_drop":hp.quniform("rate_drop",0.1,1,0.05)
}
def hyperopt_objective(params):
paramsforxgb = {"eta":params["eta"]
,"colsample_bytree":params["colsample_bytree"]
,"colsample_bynode":params["colsample_bynode"]
,"gamma":params["gamma"]
,"lambda":params["lambda"]
,"min_child_weight":params["min_child_weight"]
,"max_depth":int(params["max_depth"])
,"subsample":params["subsample"]
,"rate_drop":params["rate_drop"]
,"booster":"dart"
,"nthred":14
,"verbosity":0
,"seed":1412}
result = xgb.cv(params,data_xgb, seed=1412, metrics=("rmse")
,num_boost_round=int(params["num_boost_round"]))
return result.iloc[-1,2]
Step 5.在修改后的参数空间上,继续训练贝叶斯优化器
params_best, trials = param_hyperopt(100)100%|██████████████████████████████████████████████| 100/100 [02:38<00:00, 1.59s/trial, best loss: 25711.822916666668]
best params: {'colsample_bynode': 0.7000000000000001, 'colsample_bytree': 0.75, 'eta': 0.1, 'gamma': 13500000.0, 'lambda': 1.8, 'max_depth': 3, 'min_child_weight': 1.5, 'num_boost_round': 210.0, 'rate_drop': 0.7000000000000001, 'subsample': 1.0}
params_best, trials = param_hyperopt(100)100%|██████████████████████████████████████████████| 100/100 [02:33<00:00, 1.53s/trial, best loss: 25662.024739666667]
best params: {'colsample_bynode': 0.45, 'colsample_bytree': 1.0, 'eta': 0.05, 'gamma': 13000000.0, 'lambda': 0.5, 'max_depth': 6, 'min_child_weight': 0.5, 'num_boost_round': 150.0, 'rate_drop': 0.65, 'subsample': 0.8500000000000001}
params_best, trials = param_hyperopt(100)58%|███████████████████████████▎ | 58/100 [01:33<01:07, 1.62s/trial, best loss: 25737.109375333337]
best params: {'colsample_bynode': 0.7000000000000001, 'colsample_bytree': 0.9500000000000001, 'eta': 0.05, 'gamma': 8000000.0, 'lambda': 0.8, 'max_depth': 9, 'min_child_weight': 1.0, 'num_boost_round': 160.0, 'rate_drop': 0.30000000000000004, 'subsample': 0.8}
在搜索当中得到的最佳分数是25662.024。现在尝试在验证函数上验证这一组参数:
Step 6.验证参数
def hyperopt_validation(params):
paramsforxgb = {"eta":params["eta"]
,"booster":"dart"
,"colsample_bytree":params["colsample_bytree"]
,"colsample_bynode":params["colsample_bynode"]
,"gamma":params["gamma"]
,"lambda":params["lambda"]
,"min_child_weight":params["min_child_weight"]
,"max_depth":int(params["max_depth"])
,"subsample":params["subsample"]
,"rate_drop":params["rate_drop"]
,"nthred":14
,"verbosity":0
,"seed":1412}
result = xgb.cv(params,data_xgb, seed=1412, metrics=("rmse")
,num_boost_round=int(params["num_boost_round"]))
return result.iloc[-1,2]bestparams = {'colsample_bynode': 0.45
, 'colsample_bytree': 1.0
, 'eta': 0.05
, 'gamma': 13000000.0
, 'lambda': 0.5
, 'max_depth': 6
, 'min_child_weight': 0.5
, 'num_boost_round': 150.0
, 'rate_drop': 0.65
, 'subsample': 0.8500000000000001}
start = time.time()
hyperopt_validation(bestparams)25368.487630333333
end = (time.time() - start)
print(end)1.1478571891784668
| 算法 | RF (TPE) | AdaBoost (TPE) | GBDT (TPE) | XGB (TPE) |
|---|---|---|---|---|
| 5折验证 运行时间 | 0.22s | 0.27s | 1.54s(↑) | 1.14s(↓) |
| 测试最优分数 (RMSE) | 28346.673 | 35169.730 | 26415.835(↓) | 25368.487(↓) |

















 1284
1284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









