






大家好,今儿和大家分享一个关于XGBoost 的案例:使用XGBoost预测虚拟销售数据的产品销售额。
本案例的目标是通过XGBoost模型,利用虚拟销售数据来预测未来的产品销售额。XGBoost是一个基于梯度提升算法(Gradient Boosting Decision Trees, GBDT)的增强算法,以其高效、灵活和准确的特性广泛应用于分类和回归任务。
XGBoost原理
XGBoost全称为eXtreme Gradient Boosting,是GBDT的扩展。它通过训练一系列的弱学习器(通常是决策树)来优化损失函数。XGBoost的核心思想是通过每一轮迭代,训练一个新的弱学习器来修正之前模型的误差。最终,所有弱学习器的组合形成一个强大的预测模型。
XGBoost采用的梯度提升树(Gradient Boosting Tree,GBT)是迭代构建的树集成模型。每次迭代时,新树拟合当前模型的残差,也就是当前模型的预测值和实际值的误差。新树的加入使得模型的预测能力不断提升。
虚拟数据集
在本案例中,我们将生成一个虚拟的销售数据集,数据集包含以下字段:
-
Product_ID: 产品ID -
Store_ID: 商店ID -
Sales: 销售额(目标变量) -
Promotion: 是否进行促销(0或1) -
Price: 产品价格 -
Season: 当前季节(1代表春季,2代表夏季,3代表秋季,4代表冬季) -
Stock: 库存量
通过该数据集,我们将训练一个XGBoost模型,预测不同商店在不同促销和季节条件下的产品销售额。
Python代码实现
数据生成与可视化
首先,我们使用Python代码生成一个虚拟的数据集并对数据进行简单的可视化。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 设置随机种子
np.random.seed(42)
# 生成虚拟数据集
data_size = 1000
Product_ID = np.random.randint(1, 20, data_size)
Store_ID = np.random.randint(1, 10, data_size)
Promotion = np.random.randint(0, 2, data_size)
Price = np.random.uniform(5, 100, data_size)
Season = np.random.randint(1, 5, data_size)
Stock = np.random.randint(10, 500, data_size)
# 销售额 = 基础销量 + 促销 + 价格和库存的随机效应
Sales = (Price * 0.1 + Stock * 0.05) * (1 + Promotion * 0.2) * (1 + Season * 0.1) + np.random.normal(0, 5, data_size)
# 构建DataFrame
df = pd.DataFrame({
'Product_ID': Product_ID,
'Store_ID': Store_ID,
'Promotion': Promotion,
'Price': Price,
'Season': Season,
'Stock': Stock,
'Sales': Sales
})
# 显示数据的前几行
print(df.head())
# 绘制销售额的分布情况
plt.figure(figsize=(10, 6))
sns.histplot(df['Sales'], kde=True, color='blue')
plt.title('Distribution of Sales')
plt.xlabel('Sales')
plt.ylabel('Frequency')
plt.show()
# 绘制价格与销售额的关系
plt.figure(figsize=(10, 6))
sns.scatterplot(x='Price', y='Sales', data=df, hue='Promotion', palette='bright')
plt.title('Price vs Sales with Promotion')
plt.xlabel('Price')
plt.ylabel('Sales')
plt.show()
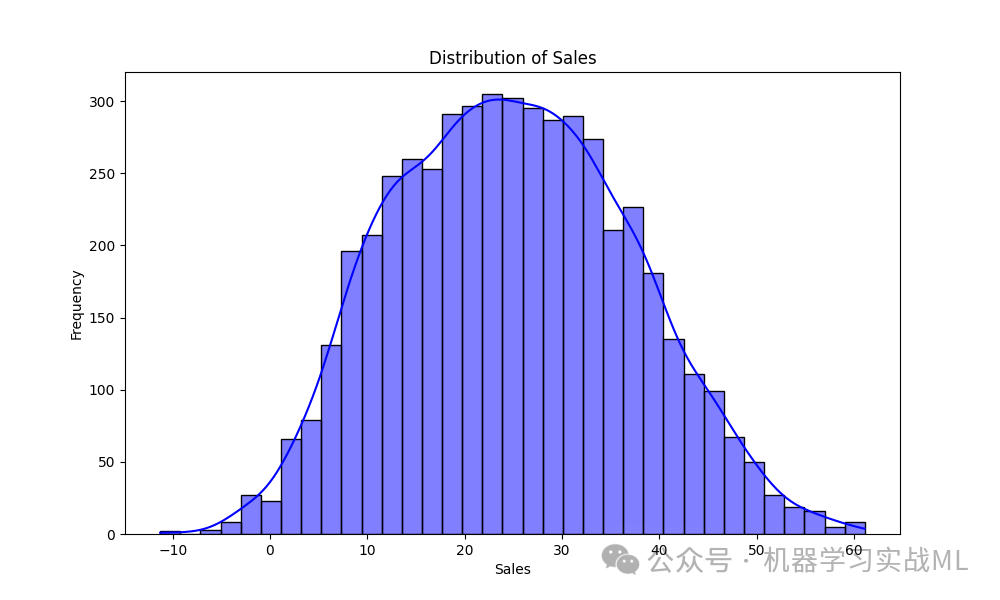
Sales分布图:我们首先查看了目标变量Sales的分布情况。通过观察分布图,可以看出销售额大致呈正态分布,且大部分销售额集中在中等区间,存在一些极端高销售额的样本。这为建模提供了初步的参考,数据没有明显的偏态。
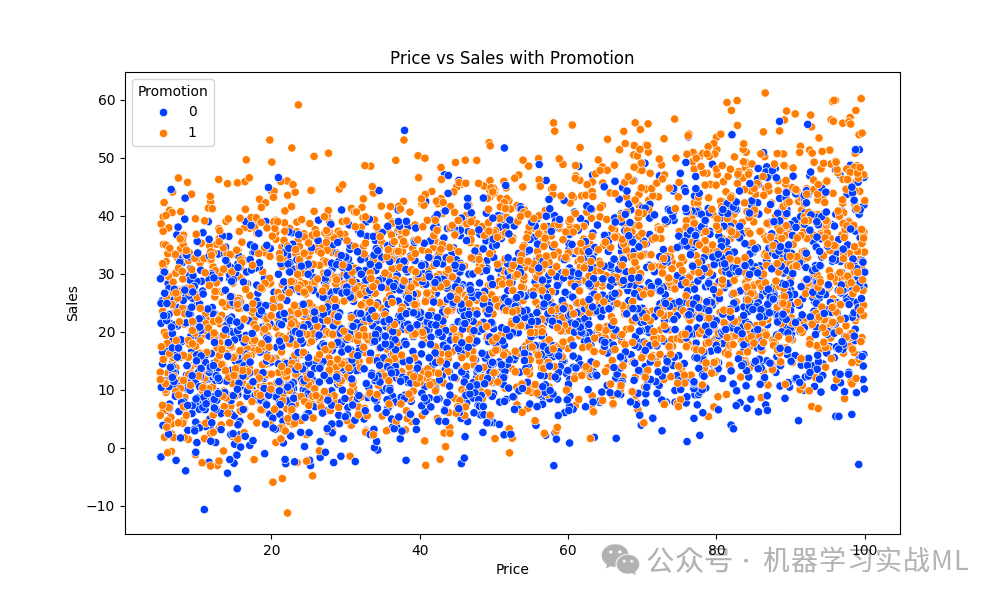
Price vs Sales散点图:第二张图展示了产品价格与销售额之间的关系,并通过颜色区分是否进行了促销。可以看到价格较高时,促销对销售的提升作用较大,而在价格较低时促销的影响相对较小。这个结果符合我们对现实销售情境的预期。
模型训练与调参
接下来我们将使用XGBoost模型进行训练,并使用网格搜索(Grid Search)进行参数调优。
from sklearn.model_selection import train_test_split
from xgboost import XGBRegressor
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import mean_squared_error
# 数据准备
X = df[['Product_ID', 'Store_ID', 'Promotion', 'Price', 'Season', 'Stock']]
y = df['Sales']
# 分割数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始模型训练
xgb_model = XGBRegressor(objective='reg:squarederror', random_state=42)
xgb_model.fit(X_train, y_train)
# 模型预测
y_pred = xgb_model.predict(X_test)
# 计算MSE
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# 网格搜索参数调优
param_grid = {
'max_depth': [3, 5, 7],
'learning_rate': [0.01, 0.1, 0.3],
'n_estimators': [100, 200, 300],
'subsample': [0.8, 1],
'colsample_bytree': [0.8, 1]
}
grid_search = GridSearchCV(estimator=xgb_model, param_grid=param_grid, cv=3, scoring='neg_mean_squared_error', verbose=2)
grid_search.fit(X_train, y_train)
# 输出最优参数
print("Best Parameters:", grid_search.best_params_)
# 使用最佳参数训练最终模型
best_model = grid_search.best_estimator_
y_pred_best = best_model.predict(X_test)
# 计算最终的MSE
final_mse = mean_squared_error(y_test, y_pred_best)
print(f"Final Mean Squared Error: {final_mse}")
结果分析与可视化
通过训练后的模型,我们可以对特征重要性进行可视化,并分析模型的预测结果。
# 特征重要性可视化
plt.figure(figsize=(10, 6))
importance = best_model.feature_importances_
sns.barplot(x=importance, y=X.columns, palette='viridis')
plt.title('Feature Importance')
plt.xlabel('Importance Score')
plt.ylabel('Features')
plt.show()
# 绘制预测值与真实值的对比图
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred_best, color='red')
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], linestyle='--', color='blue')
plt.title('Predicted vs Actual Sales')
plt.xlabel('Actual Sales')
plt.ylabel('Predicted Sales')
plt.show()
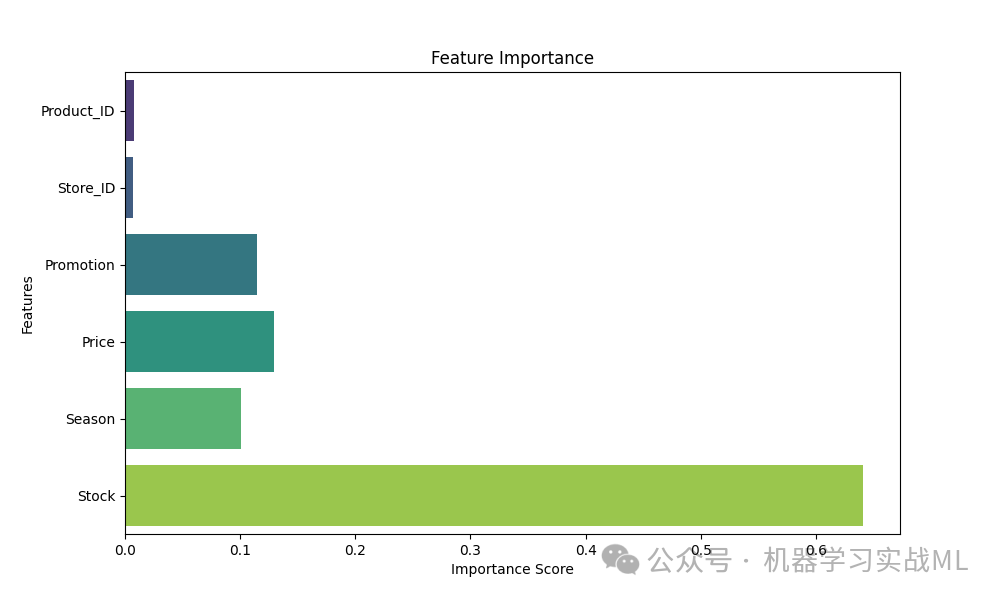
Feature Importance:从特征重要性图中可以看出,Price 和 Stock 是影响销售额最重要的两个特征。这符合我们的业务逻辑,价格和库存量直接决定了产品销售的规模。Promotion 和 Season 也对销售有一定影响,但相对较弱。
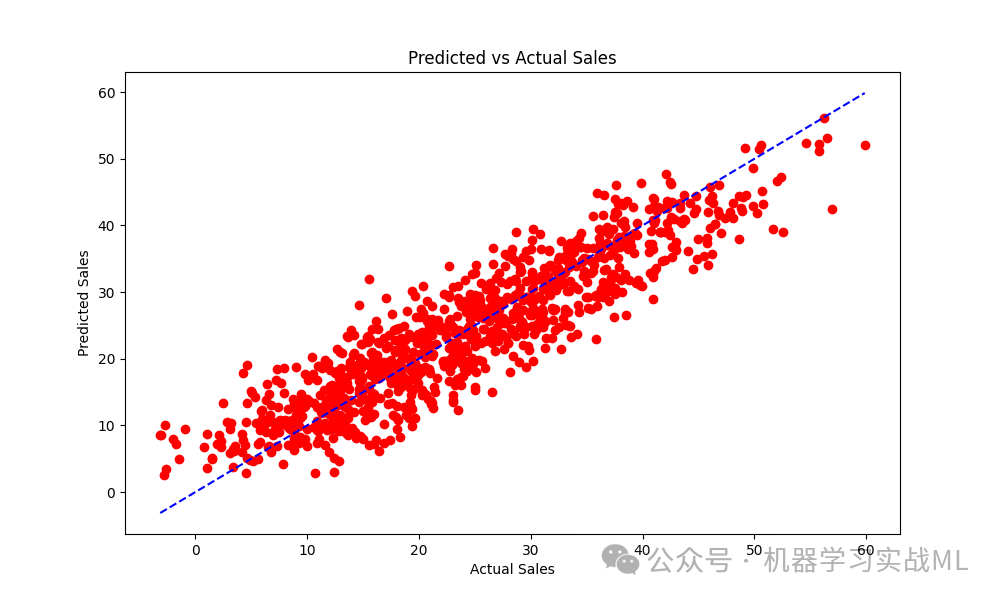
Predicted vs Actual Sales:第二张图展示了模型预测的销售额与实际销售额的对比情况。理想情况下,所有点应该沿着蓝色的45度线分布。可以看到,模型在多数样本上有较为准确的预测,但对于极端值的预测偏差较大,这可能是由于极端销售额的数据较少,导致模型难以精确拟合这些样本。
总结
最终结果表明,价格和库存量是预测销售额的重要因素,而促销和季节对销售额的影响次之。模型的预测效果较为理想,但在极端样本上存在一定的误差。这为我们在实际业务中使用XGBoost模型提供了重要参考,同时也表明在实际应用中还需要更多的数据和更复杂的模型优化手段。


















 2031
2031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









