










今日CS.CV计算机视觉论文速览
Tue, 5 Mar 2019
Totally 63 papers

Interesting:
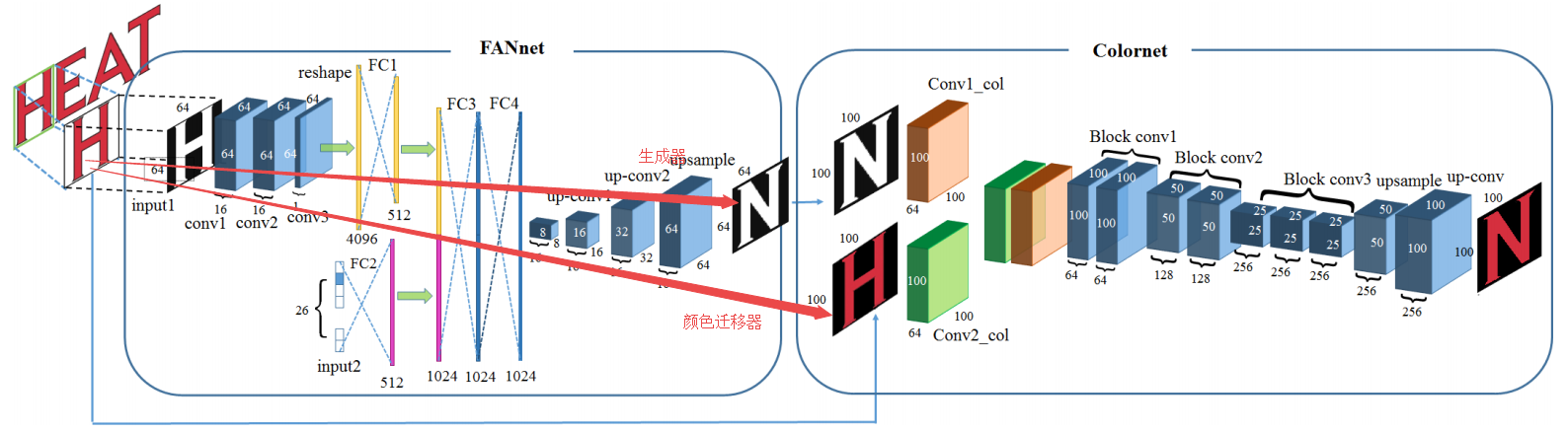
?STEFANN,基于字体自适应网络实现场景中的文字编辑修改。目前的场景文字识别很成功,按时对于场景中文字修改的工作还很少。这篇文章对于照片中文字进行自适应修改,不仅能够修复图像中的文字信息,同时可以得到戏剧性的效果。研究人员首先聚焦于如何生成不违和的文字,包括字体和颜色等。提出了一个多输入的字体特征生成器,并将原图的颜色迁移到目标图像上去。随后将生成的文字放置到原图的对应位置,并进行视觉连续性处理。(from Indian Statistical Institute Kolkata) CVPR
模型的架构如下,包含了字体生成器和颜色迁移器组成:
一些有趣的效果:
数据集:ICDAR


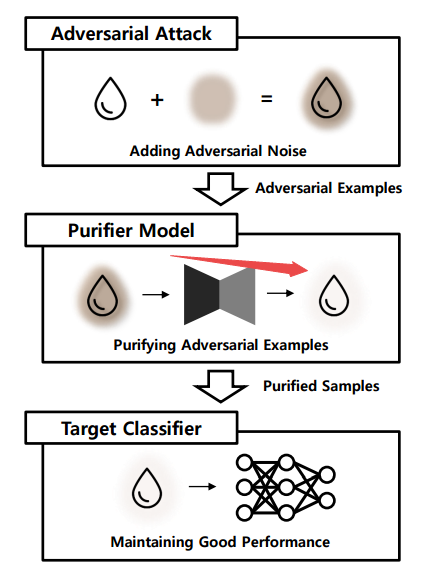
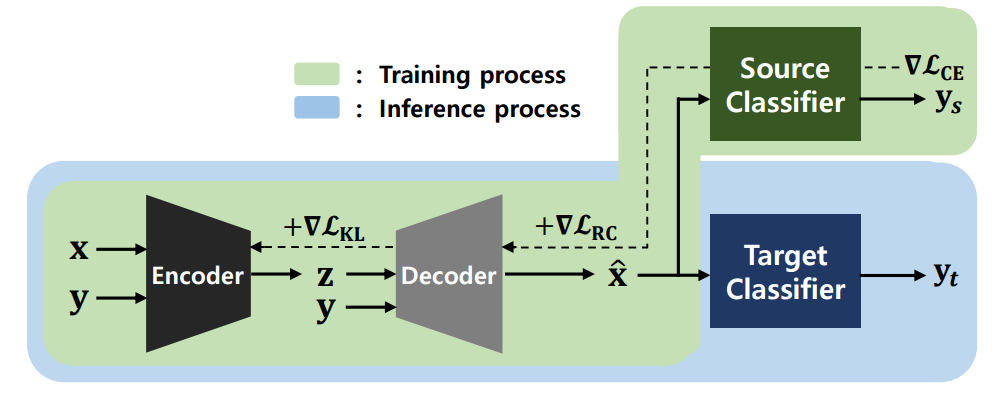
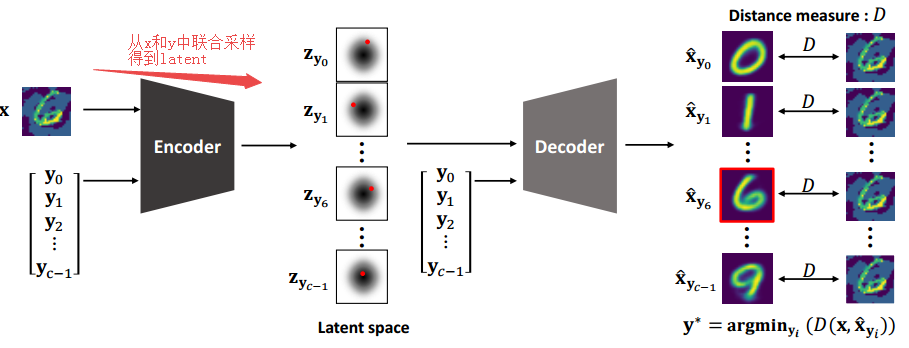
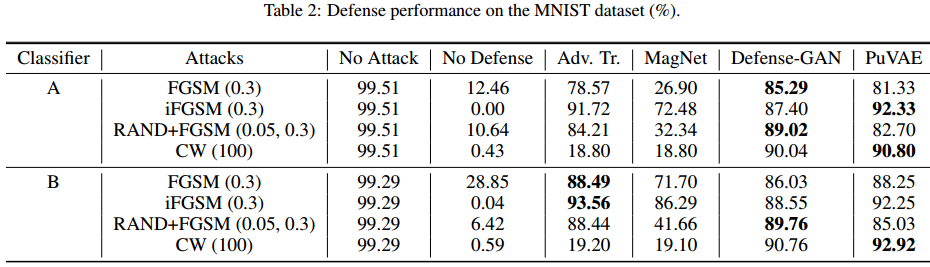
?PuVAE基于变分自编码器提纯对抗样本,提出了一种利用变分自编码器提出对抗样本,降低对抗噪声的模型。为了防御深度学习中对抗样本的影响,研究人员提出了一种基于变分自编码器提纯对抗样本的方法。通过将对抗样本投影到流型空间的不同类别上,来估计和消除对抗扰动。实验表面这种方法性能强劲并比普通DefenseGan快130倍。(首尔国立大学)
模型结构示例图:
训练和推理过程示例图:
推理过程的示意图:
与类似方法的比较:
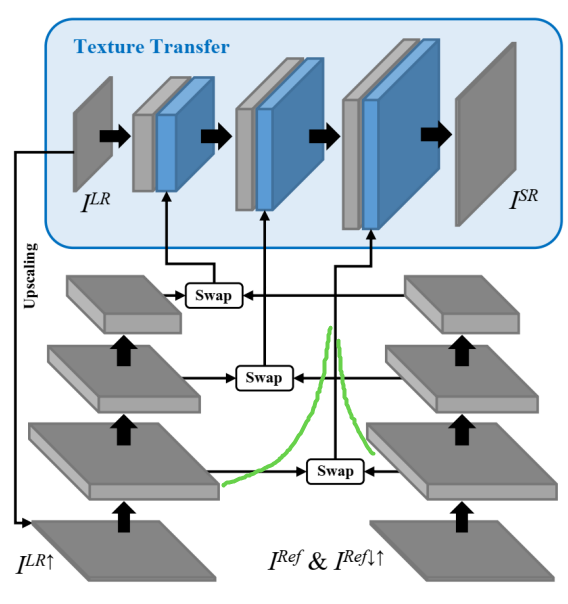
?SRNTT基于迁移学习的图像超分辨,单图像超分辨在近年来获得了较大的发展,但对于参考图片与目标图片不相似的情况下生成的超分辨率质量较差。研究人员提出了一种可以将高分辨图像中的细节纹理信息用于提高低分辨率图像分辨率的迁移学习方法,利用自然纹理迁移的技术实现了图像超分辨。利用多级神经空间匹配来代替像素间的配准,提高了模型利用语义相似片层的能力,并用优雅的方法提高了超分辨的能力。研究还建立了RefSR数据集,包含了低分辨图像和一系列层级相似性的配对图像。(from adobe)
一些结果:
模型的架构如下图所示,将多层级的特征进行了交换,并将参考图像下采样得到与低分辨图频谱一致的约束:
一些相似方法的对比:
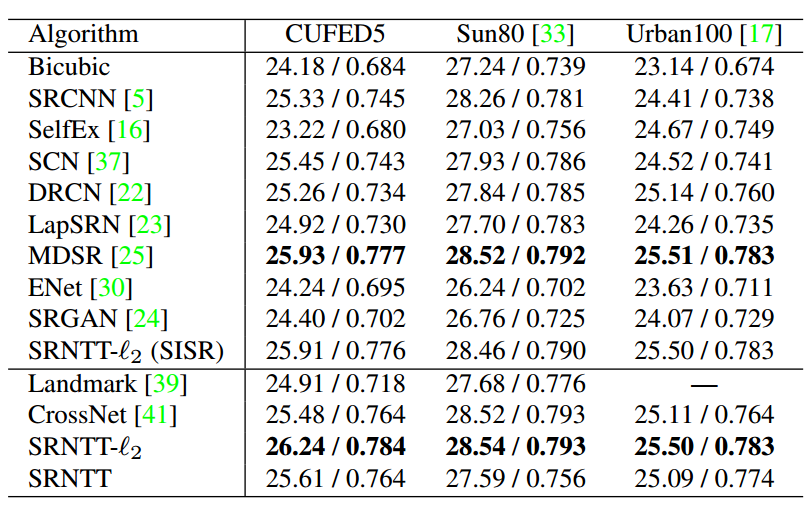
Implementation of SR algorithms in comparison:
SRCNN, SelfEx, SCN, DRCN, LapSRN, MDSR, ENet, SRGAN, CrossNet,
code:https://github.com/ZZUTK/SRNTT
*****author:https://research.adobe.com/person/zhifei-zhang/ http://web.eecs.utk.edu/~zzhang61/

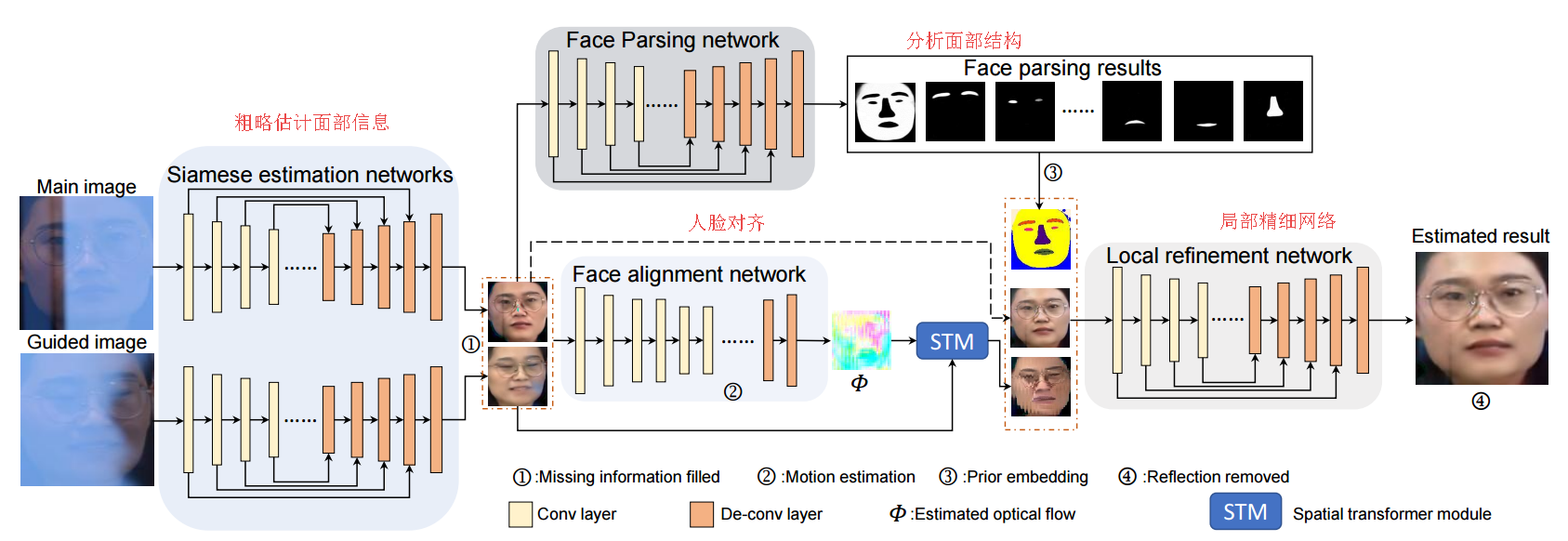
?提出了一种基于图像修复和面部先验的方法,用于移除面部照片中的玻璃反光,研究了透射、反射、非投射式反射等情况下的反射去除。(from 南洋理工)
模型的框架分为四个部分:
研究人员还构建了自己的面部反射数据集:
一些最终的结果:
作者研究多年反射去除:https://wanrenjie.github.io/



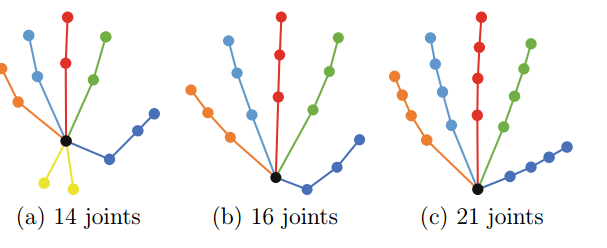
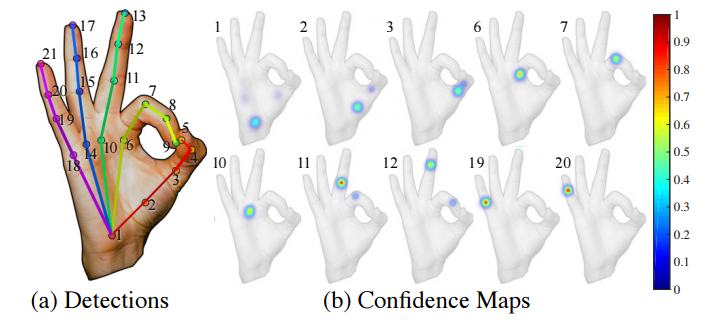
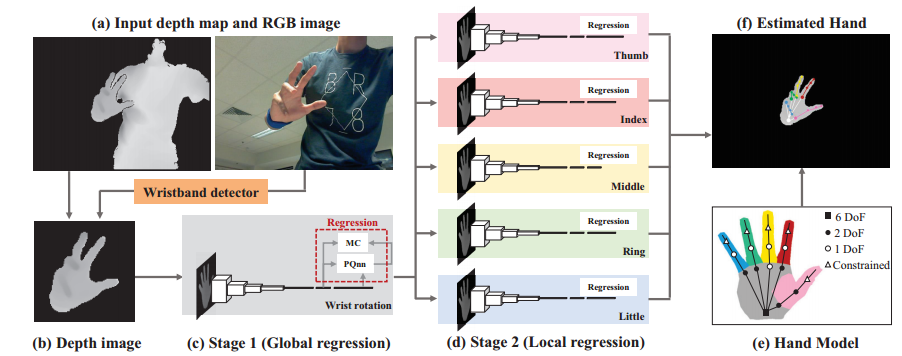
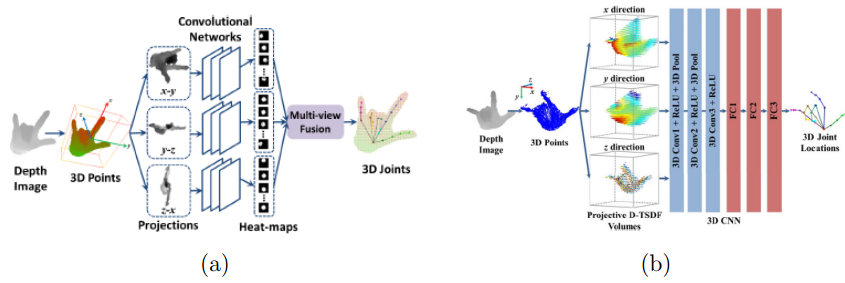
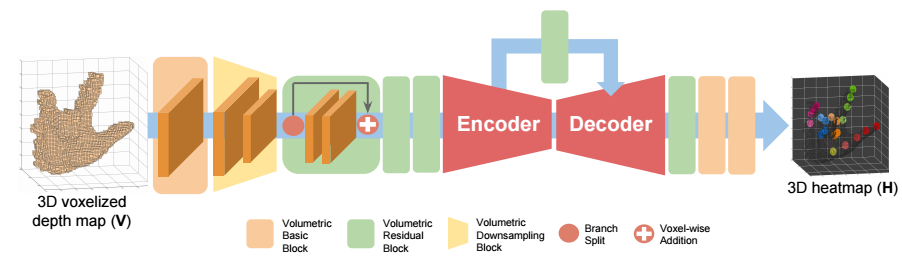
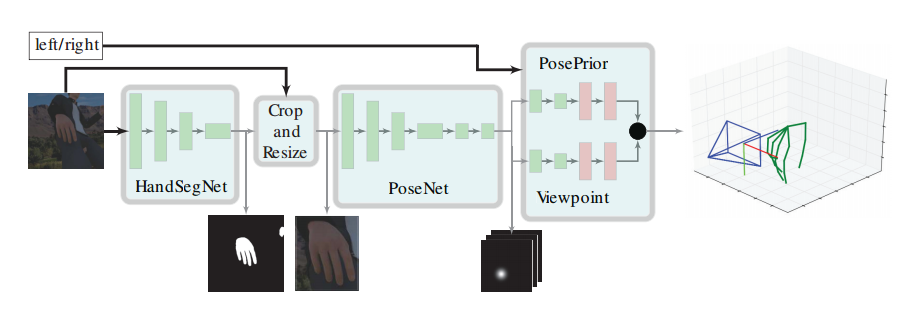
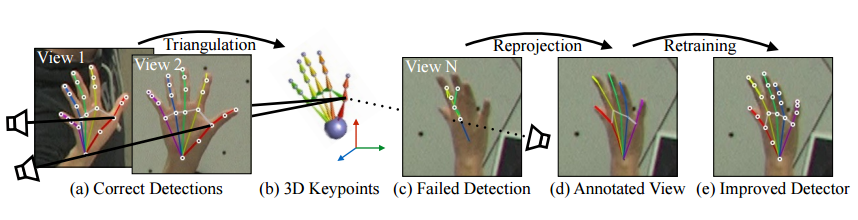
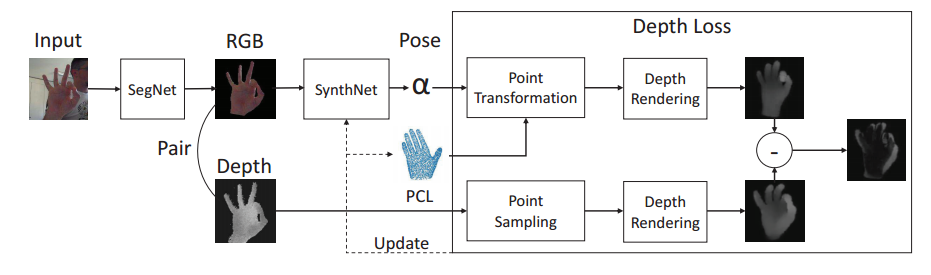
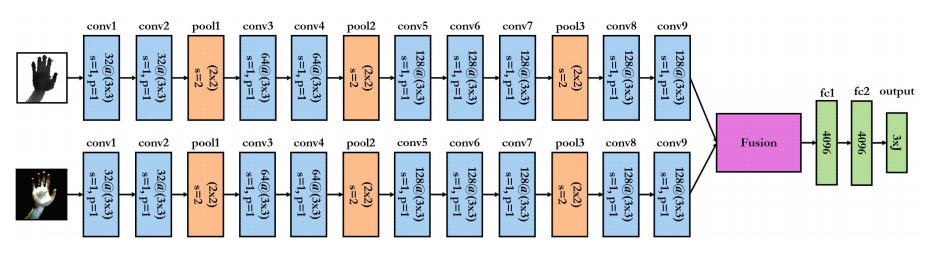
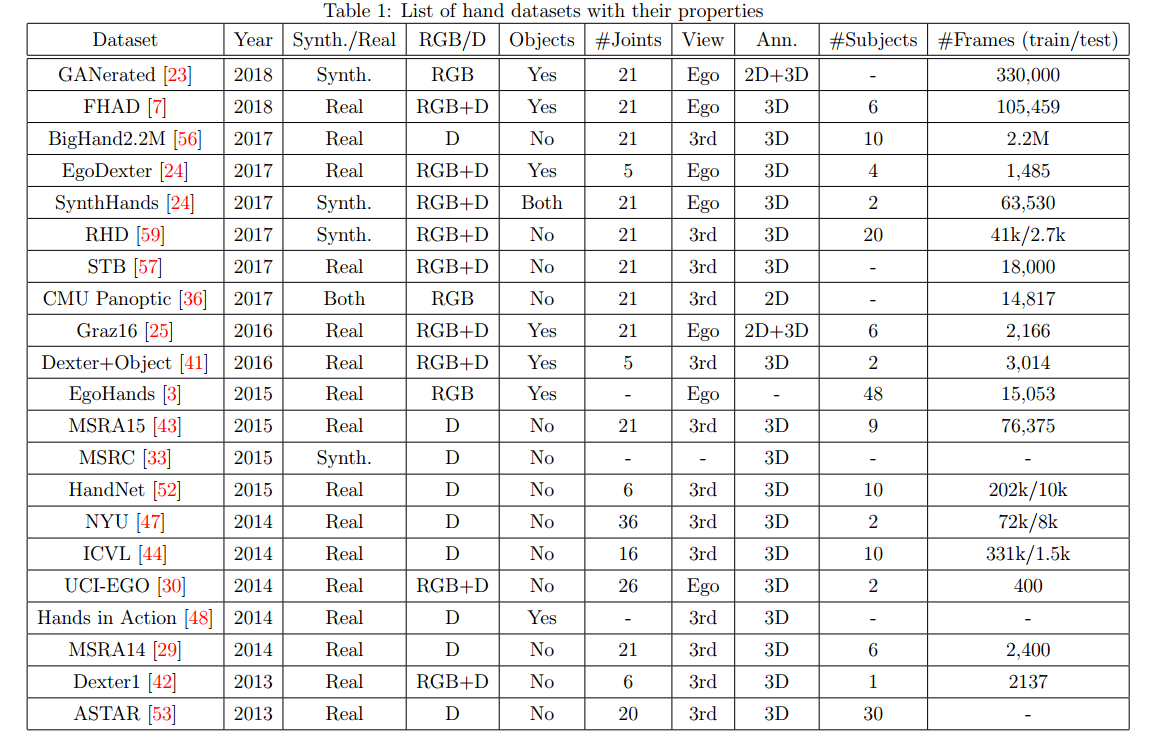
?手部位姿识别综述,文章中解释了手部位姿估计问题,介绍了一些主要的解决办法,特别是基于RGB和深度之间的区别。此外介绍了每个子领域的重要论文及其优缺点,随后给出了领域中的数据集。(from印第安纳大学)
不同种类的关键点:
基于颜色和置信图的方式:
一些主要的处理模型:
现有的著名数据集:


Daily Computer Vision Papers
[1] Title: VideoFlow: A Flow-Based Generative Model for Video
Authors:Manoj Kumar, Mohammad Babaeizadeh, Dumitru Erhan, Chelsea Finn, Sergey Levine, Laurent Dinh, Durk Kingma
[2] Title: An Adversarial Super-Resolution Remedy for Radar Design Trade-offs
Authors:Sherif Abdulatif, Karim Armanious, Fady Aziz, Urs Schneider, Bin Yang
[3] Title: Reduced Focal Loss: 1st Place Solution to xView object detection in Satellite Imagery
Authors:Nikolay Sergievskiy, Alexander Ponamarev
[4] Title: Joint segmentation and classification of retinal arteries/veins from fundus images
Authors:Fantin Girard, Conrad Kavalec, Farida Cheriet
[5] Title: Semi-Supervised Brain Lesion Segmentation with an Adapted Mean Teacher Model
Authors:Wenhui Cui, Yanlin Liu, Yuxing Li, Menghao Guo, Yiming Li, Xiuli Li, Tianle Wang, Xiangzhu Zeng, Chuyang Ye
[6] Title: Understanding the Mechanism of Deep Learning Framework for Lesion Detection in Pathological Images with Breast Cancer
Authors:Wei-Wen Hsu, Chung-Hao Chen, Chang Hoa, Yu-Ling Hou, Xiang Gao, Yun Shao, Xueli Zhang, Jingjing Wang, Tao He, Yanghong Tai
[7] Title: Unsupervised Domain Adaptation Learning Algorithm for RGB-D Staircase Recognition
Authors:Wang Jing, Zhang Kuangen
[8] Title: Collaborative Spatio-temporal Feature Learning for Video Action Recognition
Authors:Chao Li, Qiaoyong Zhong, Di Xie, Shiliang Pu
[9] Title: STEFANN: Scene Text Editor using Font Adaptive Neural Network
Authors:Prasun Roy, Saumik Bhattacharya, Subhankar Ghosh, Umapada Pal
[10] Title: PanopticFusion: Online Volumetric Semantic Mapping at the Level of Stuff and Things
Authors:Gaku Narita, Takashi Seno, Tomoya Ishikawa, Yohsuke Kaji
[11] Title: Zero-Shot Task Transfer
Authors:Arghya Pal, Vineeth N Balasubramanian
[12] Title: Automatic microscopic cell counting by use of deeply-supervised density regression model
Authors:Shenghua He, Kyaw Thu Minn, Lilianna Solnica-Krezel, Mark Anastasio, Hua Li
[13] Title: Unsupervised Cross-spectral Stereo Matching by Learning to Synthesize
Authors:Mingyang Liang, Xiaoyang Guo, Hongsheng Li, Xiaogang Wang, You Song
[14] Title: COMIC: Towards A Compact Image Captioning Model with Attention
Authors:Jia Huei Tan, Chee Seng Chan, Joon Huang Chuah
[15] Title: Incremental Visual-Inertial 3D Mesh Generation with Structural Regularities
Authors:Antoni Rosinol, Torsten Sattler, Marc Pollefeys, Luca Carlone
[16] Title: Spatiotemporal Pyramid Network for Video Action Recognition
Authors:Yunbo Wang, Mingsheng Long, Jianmin Wang, Philip S. Yu
[17] Title: Active Authentication using an Autoencoder regularized CNN-based One-Class Classifier
Authors:Poojan Oza, Vishal M. Patel
[18] Title: A Kernelized Manifold Mapping to Diminish the Effect of Adversarial Perturbations
Authors:Saeid Asgari Taghanaki, Kumar Abhishek, Shekoofeh Azizi, Ghassan Hamarneh
[19] Title: Hand Pose Estimation: A Survey
Authors:Bardia Doosti
[20] Title: Self-Supervised Learning of Face Representations for Video Face Clustering
Authors:Vivek Sharma, Makarand Tapaswi, M.Saquib Sarfraz, Rainer Stiefelhagen
[21] Title: X-Section: Cross-section Prediction for Enhanced RGBD Fusion
Authors:Andrea Nicastro, Ronald Clark, Stefan Leutenegger
[22] Title: Matching Thermal to Visible Face Images Using a Semantic-Guided Generative Adversarial Network
Authors:Cunjian Chen, Arun Ross
[23] Title: Probability Map Guided Bi-directional Recurrent UNet for Pancreas Segmentation
Authors:Jun Li, Xiaozhu Lin, Hui Che, Hao Li, Xiaohua Qian
[24] Title: Unsupervised Bi-directional Flow-based Video Generation from one Snapshot
Authors:Lu Sheng, Junting Pan, Jiaming Guo, Jing Shao, Xiaogang Wang, Chen Change Loy
[25] Title: Ground Plane based Absolute Scale Estimation for Monocular Visual Odometry
Authors:Dingfu Zhou, Yuchao Dai, Hongdong Li
[26] Title: MILDNet: A Lightweight Single Scaled Deep Ranking Architecture
Authors:Anirudha Vishvakarma
[27] Title: 3D convolutional neural network for abdominal aortic aneurysm segmentation
Authors:Karen López-Linares, Inmaculada García, Ainhoa García-Familiar, Iván Macía, Miguel A. González Ballester
[28] Title: Meta-SR: A Magnification-Arbitrary Network for Super-Resolution
Authors:Xuecai Hu, Haoyuan Mu, Xiangyu Zhang, Zilei Wang, Jian Sun, Tieniu Tan
[29] Title: Face Image Reflection Removal
Authors:Renjie Wan, Boxin Shi, Haoliang Li, Ling-Yu Duan, Alex C. Kot
[30] Title: Less is More: Learning Highlight Detection from Video Duration
Authors:Bo Xiong, Yannis Kalantidis, Deepti Ghadiyaram, Kristen Grauman
[31] Title: Recognition of Multiple Food Items in a Single Photo for Use in a Buffet-Style Restaurant
Authors:Masashi Anzawa, Sosuke Amano, Yoko Yamakata, Keiko Motonaga, Akiko Kamei, Kiyoharu Aizawa
[32] Title: CAD-Net: A Context-Aware Detection Network for Objects in Remote Sensing Imagery
Authors:Gongjie Zhang, Shijian Lu, Wei Zhang
[33] Title: Crowd Counting and Density Estimation by Trellis Encoder-Decoder Network
Authors:Xiaolong Jiang, Zehao Xiao, Baochang Zhang, Xiantong Zhen, Xianbin Cao, David Doermann, Ling Shao
[34] Title: Improving Referring Expression Grounding with Cross-modal Attention-guided Erasing
Authors:Xihui Liu, Zihao Wang, Jing Shao, Xiaogang Wang, Hongsheng Li
[35] Title: Image Super-Resolution by Neural Texture Transfer
Authors:Zhifei Zhang, Zhaowen Wang, Zhe Lin, Hairong Qi
[36] Title: Pancreas Segmentation via Spatial Context based U-net and Bidirectional LSTM
Authors:Hao Li, Jun Li, Xiaozhu Lin, Xiaohua Qian
[37] Title: 3D Hand Shape and Pose Estimation from a Single RGB Image
Authors:Liuhao Ge, Zhou Ren, Yuncheng Li, Zehao Xue, Yingying Wang, Jianfei Cai, Junsong Yuan
[38] Title: Let’s Transfer Transformations of Shared Semantic Representations
Authors:Nam Vo, Lu Jiang, James Hays
[39] Title: AIRD: Adversarial Learning Framework for Image Repurposing Detection
Authors:Ayush Jaiswal, Yue Wu, Wael AbdAlmageed, Iacopo Masi, Premkumar Natarajan
[40] Title: Spatio-Temporal Vegetation Pixel Classification By Using Convolutional Networks
Authors:Keiller Nogueira, Jefersson A. dos Santos, Nathalia Menini, Thiago S. F. Silva, Leonor Patricia C. Morellato, Ricardo da S. Torres
[41] Title: Extreme Channel Prior Embedded Network for Dynamic Scene Deblurring
Authors:Jianrui Cai, Wangmeng Zuo, Lei Zhang
[42] Title: PartNet: A Recursive Part Decomposition Network for Fine-grained and Hierarchical Shape Segmentation
Authors:Fenggen Yu, Kun Liu, Yan Zhang, Chenyang Zhu, Kai Xu
[43] Title: Deep Optimization model for Screen Content Image Quality Assessment using Neural Networks
Authors:Xuhao Jiang, Liquan Shen, Guorui Feng, Liangwei Yu, Ping An
[44] Title: Fine-Grained Semantic Segmentation of Motion Capture Data using Dilated Temporal Fully-Convolutional Networks
Authors:Noshaba Cheema, Somayeh Hosseini, Janis Sprenger, Erik Herrmann, Han Du, Klaus Fischer, Philipp Slusallek
[45] Title: OmniDRL: Robust Pedestrian Detection using Deep Reinforcement Learning on Omnidirectional Cameras
Authors:G. Dias Pais, Tiago J. Dias, Jacinto C. Nascimento, Pedro Miraldo
[46] Title: Quaternion Convolutional Neural Networks
Authors:Xuanyu Zhu, Yi Xu, Hongteng Xu, Changjian Chen
[47] Title: Feature Selective Anchor-Free Module for Single-Shot Object Detection
Authors:Chenchen Zhu, Yihui He, Marios Savvides
[48] Title: RGBD Based Dimensional Decomposition Residual Network for 3D Semantic Scene Completion
Authors:Jie Li, Yu Liu, Dong Gong, Qinfeng Shi, Xia Yuan, Chunxia Zhao, Ian Reid
[49] Title: Unsupervised Traffic Accident Detection in First-Person Videos
Authors:Yu Yao, Mingze Xu, Yuchen Wang, David J. Crandall, Ella M. Atkins
[50] Title: Straight to the point: reinforcement learning for user guidance in ultrasound
Authors:Fausto Milletari, Vighnesh Birodkar, Michal Sofka
[51] Title: Unsupervised Tracklet Person Re-Identification
Authors:Minxian Li, Xiatian Zhu, Shaogang Gong
[52] Title: Learning where to look: Semantic-Guided Multi-Attention Localization for Zero-Shot Learning
Authors:Yizhe Zhu, Jianwen Xie, Zhiqiang Tang, Xi Peng, Ahmed Elgammal
[53] Title: PEA265: Perceptual Assessment of Video Compression Artifacts
Authors:Liqun Lin, Shiqi Yu, Tiesong Zhao, Member, IEEE, Zhou Wang, Fellow, IEEE
[54] Title: Complement Objective Training
Authors:Hao-Yun Chen, Pei-Hsin Wang, Chun-Hao Liu, Shih-Chieh Chang, Jia-Yu Pan, Yu-Ting Chen, Wei Wei, Da-Cheng Juan
[55] Title: Accelerating Training of Deep Neural Networks with a Standardization Loss
Authors:Jasmine Collins, Johannes Balle, Jonathon Shlens
[56] Title: End-to-end Driving Deploying through Uncertainty-Aware Imitation Learning and Stochastic Visual Domain Adaptation
Authors:Lei Tai, Peng Yun, Yuying Chen, Congcong Liu, Haoyang Ye, Ming Liu
[57] Title: Keyframe-based Direct Thermal-Inertial Odometry
Authors:Shehryar Khattak, Christos Papachristos, Kostas Alexis
[58] Title: Marker based Thermal-Inertial Localization for Aerial Robots in Obscurant Filled Environments
Authors:Shehryar Khattak, Christos Papachristos, Kostas Alexis
[59] Title: Time-Delay Momentum: A Regularization Perspective on the Convergence and Generalization of Stochastic Momentum for Deep Learning
Authors:Ziming Zhang, Wenju Xu, Alan Sullivan
[60] Title: Equilibrated Recurrent Neural Network: Neuronal Time-Delayed Self-Feedback Improves Accuracy and Stability
Authors:Ziming Zhang, Anil Kag, Alan Sullivan, Venkatesh Saligrama
[61] Title: Strong homotopy of digitally continuous functions
Authors:P. Christopher Staecker
[62] Title: PuVAE: A Variational Autoencoder to Purify Adversarial Examples
Authors:Uiwon Hwang, Jaewoo Park, Hyemi Jang, Sungroh Yoon, Nam Ik Cho
[63] Title: Sparse Depth Enhanced Direct Thermal-infrared SLAM Beyond the Visible Spectrum
Authors:Young-Sik Shin, Ayoung Kim
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









