







转载自http://zhangliliang.com/2015/05/17/paper-note-fast-rcnn/
论文出处见:http://arxiv.org/abs/1504.08083
项目见:https://github.com/rbgirshick/fast-rcnn
R-CNN的进化版,0.3s一张图片,VOC07有70的mAP,可谓又快又强。
而且rbg的代码一般写得很好看,应该会是个很值得学习的项目。
动机
为何有了R-CNN和SPP-Net之后还要提出Fast RCNN(简称FRCN)?因为前者有三个缺点
- 训练的时候,pipeline是隔离的,先提proposal,然后CNN提取特征,之后用SVM分类器,最后再做bbox regression。FRCN实现了end-to-end的joint training(提proposal阶段除外)。
- 训练时间和空间开销大。RCNN中ROI-centric的运算开销大,所以FRCN用了image-centric的训练方式来通过卷积的share特性来降低运算开销;RCNN提取特征给SVM训练时候需要中间要大量的磁盘空间存放特征,FRCN去掉了SVM这一步,所有的特征都暂存在显存中,就不需要额外的磁盘空间了。
- 测试时间开销大。依然是因为ROI-centric的原因,这点SPP-Net已经改进,然后FRCN进一步通过single scale testing和SVD分解全连接来提速。
整体框架
整体框架如Figure 1,如果以AlexNet(5个卷积和3个全连接)为例,大致的训练过程可以理解为:
- selective search在一张图片中得到约2k个object proposal(这里称为RoI)
- 缩放图片的scale得到图片金字塔,FP得到conv5的特征金字塔。
- 对于每个scale的每个ROI,求取映射关系,在conv5中crop出对应的patch。并用一个单层的SPP layer(这里称为Rol pooling layer)来统一到一样的尺度(对于AlexNet是6x6)。
- 继续经过两个全连接得到特征,这特征有分别share到两个新的全连接,连接上两个优化目标。第一个优化目标是分类,使用softmax,第二个优化目标是bbox regression,使用了一个smooth的L1-loss.
除了1,上面的2-4是joint training的。
测试时候,在4之后做一个NMS即可。
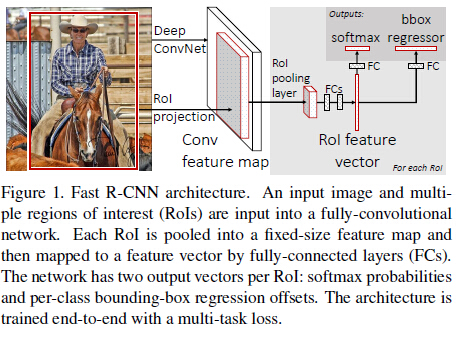
整体框架大致如上述所示了,对比回来SPP-Net,可以看出FRCN大致就是一个joint training版本的SPP-Net,改进如下:
- SPP-Net在实现上无法同时tuning在SPP layer两边的卷积层和全连接层。
- SPP-Net后面的需要将第二层FC的特征放到硬盘上训练SVM,之后再额外训练bbox regressor。
接下来会介绍FRCN里面的一些细节的motivation和效果。
Rol pooling layer
Rol pooling layer的作用主要有两个,一个是将image中的rol定位到feature map中对应patch,另一个是用一个单层的SPP layer将这个feature map patch下采样为大小固定的feature再传入全连接层。
这里有几个细节。
- 对于某个rol,怎么求取对应的feature map patch?这个论文没有提及,笔者也还没有仔细去抠,觉得这个问题可以到代码中寻找。:)
- 为何只是一层的SPP layer?多层的SPP layer不会更好吗?对于这个问题,笔者认为是因为需要读取pretrain model来finetuning的原因,比如VGG就release了一个19层的model,如果是使用多层的SPP layer就不能够直接使用这个model的parameters,而需要重新训练了。
Multi-task loss
FRCN有两个loss,以下分别介绍。
对于分类loss,是一个N+1路的softmax输出,其中的N是类别个数,1是背景。为何不用SVM做分类器了?在5.4作者讨论了softmax效果比SVM好,因为它引入了类间竞争。(笔者觉得这个理由略牵强,估计还是实验效果验证了softmax的performance好吧 ^_^)
对于回归loss,是一个4xN路输出的regressor,也就是说对于每个类别都会训练一个单独的regressor的意思,比较有意思的是,这里regressor的loss不是L2的,而是一个平滑的L1,形式如下:
作者这样设置的目的是想让loss对于离群点更加鲁棒,控制梯度的量级使得训练时不容易跑飞。
最后在5.1的讨论中,作者说明了Multitask loss是有助于网络的performance的。
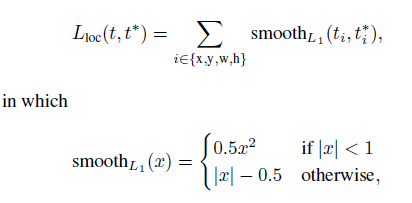
Scale invariance
这里讨论object的scale问题,就是网络对于object的scale应该是要不敏感的。这里还是引用了SPP的方法,有两种。
- brute force (single scale),也就是简单认为object不需要预先resize到类似的scale再传入网络,直接将image定死为某种scale,直接输入网络来训练就好了,然后期望网络自己能够学习到scale-invariance的表达。
- image pyramids (multi scale),也就是要生成一个金字塔,然后对于object,在金字塔上找到一个大小比较接近227x227的投影版本,然后用这个版本去训练网络。
可以看出,2应该比1更加好,作者也在5.2讨论了,2的表现确实比1好,但是好的不算太多,大概是1个mAP左右,但是时间要慢不少,所以作者实际采用的是第一个策略,也就是single scale。
这里,FRCN测试之所以比SPP快,很大原因是因为这里,因为SPP用了2,而FRCN用了1。
SVD on fc layers
对应文中3.1,这段笔者没细看。大致意思是说全连接层耗时很多,如果能够简化全连接层的计算,那么能够提升速度。
具体来说,作者对全连接层的矩阵做了一个SVD分解,mAP几乎不怎么降(0.3%),但速度提速30%
Which layers to finetune?
对应文中4.5,作者的观察有2点
- 对于较深的网络,比如VGG,卷积层和全连接层是否一起tuning有很大的差别(66.9 vs 61.4)
- 有没有必要tuning所有的卷积层?答案是没有。如果留着浅层的卷积层不tuning,可以减少训练时间,而且mAP基本没有差别。
Data augment
在训练期间,作者做过的唯一一个数据增量的方式是水平翻转。
作者也试过将VOC12的数据也作为拓展数据加入到finetune的数据中,结果VOC07的mAP从66.9到了70.0,说明对于网络来说,数据越多就是越好的。
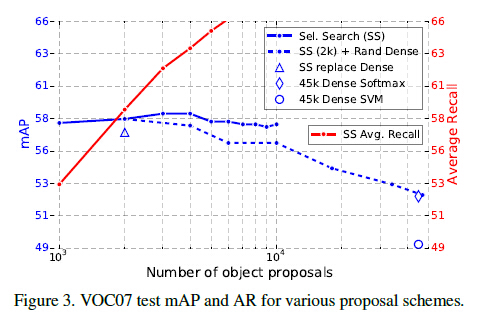
Are more proposals always better?
对应文章的5.5,答案是NO。
作者将proposal的方法粗略地分成了sparse(比如selective search)和dense(sliding windows)。
如Figure 3所示,不管是哪种方法,盲目增加proposal个数反而会损害到mAP的。
作者引用了文献11的一句话来说明:““[sparse proposals] may improve detection quality by reducing spurious false positives.”
然后笔者搜索了一下,发现文献11被TPAMI15录取了,看来也是要看一下啊。。
Fast R-CNN 论文笔记
一、为什么提出Fast R-CNN
因为Fast R-CNN的前任R-CNN和SPP-net不给力。
R-CNN训练分为多个阶段,步骤繁琐: 微调网络+训练SVM+训练边框回归器; 训练耗时又耗内存; 目标检测又慢。
SPP-net虽然比R-CNN快一些,但和R-CNN同样存在训练步骤繁锁的问题,而且无法更新SPP-net之前的卷积层。
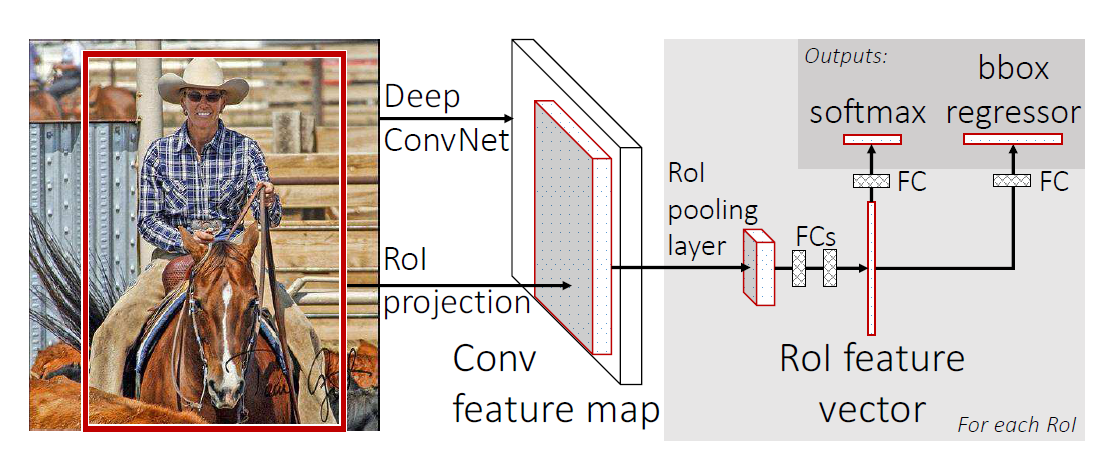
二、Fast R-CNN的框架
Fast R-CNN的输入: 一整张图像和一系列目标候选区域(object proposal)。
1)首先用conv和max_pooling层处理整张图像,生成一张特征图(feature map)。
2)然后RoI_pooling层对感兴趣的部分区域(a region of interest)提取固定长度的特征向量。
3)特征向量通过全连接层后,分别输出到softmax层和bbox_regressor层。
注意:
1)RoI_pooling层用的方法是,把
h×w
的感兴趣区域(RoI)分到固定大小的
H×W
网格中,然后对每一个网格取其最大值,这样得到的特征向量也是固定长度的,实际上这是SPP-net的一种特殊情况。
2)softmax层输出目标属于各类的概率大小,这里背景算额外的一类。
3)bbox_regressor层输出4维向量,描述一个框,即框的左顶点、长、宽。
三、Fast R-CNN的优点
1)相比较于R-CNN和SPP-net,Fast检测质量更高(mAP)。
2)训练只有一个阶段,使用了多任务损失函数。
3)相比较于SPP-net,训练可以更新所有的层。
4)缓存特征时不需要硬盘存储。
四、Fast R-CNN的缺点
我若能发现就能先写出下一篇的Faster R-CNN了~_~
发现论文中的不足,是我急需要提升的能力。
五、Fast R-CNN的补充
作者在文中研究了一些问题。
1)多任务训练能起到帮助吗?
答:能。它能提高分类准确率。
2)尺度不变性:单尺度 or 多尺度?
答:实验表明单尺度检测几乎与多尺度检测同样好,说明深度卷积网络本身就能擅长直接学习尺度不变性。
3)需要更多的数据吗?
答:实验表明,更多的数据的确提高了准确率。
4)SVMs比softmax好?
答:实验表明,softmax表现还稍胜SVMs一筹。
5)候选区域是越多越好吗?
答:不见得。
快速R-CNN,对R-CNN和SPPNet的加速,使用multi-task 进行单步训练,网络使用的是VGG16。R-CNN对每个proposal单独warp处理,SPPNet将warp放到最后一个卷积层的后面,将多个池化网格的结果串联到SPP中。SPPNet的微调算法只能更新全连接层,限制了深层网路VGG16发挥性能。
主要贡献:
1.比R-CNN检测率更高
2.单步训练,使用multi-class loss
3.可在训练的时候更新所有的网络层
4.特征不需要存储到硬盘中
1.快速R-CNN训练:
使用ConvNet在ImageNet上进行初步训练,构建具有几个卷积层和最大化池化层的网络,接下来有一个RoI池化层和几个全连接层,网络最终以两个子层收尾,一个输出K+1类目标的softmax概率,另外一个输出对应每类的4个实数值(bbox),结构如下图所示:
1)RoI池化层
SPPNet中空间金字塔池化的简化,只有一层,RoI池化层的输入是N个特征图和R个RoI区域,特征图是卷积层的输出,大小是H*W*C。RoI是一个多元组(n,r,c,h,w),对应每个特征图的位置和大小。该层的输出是最大池化特征图
2)使用初训练的网络
有三个初始训练的网络,有5个最大池化层和5到13个卷积层,快速R-CNN对它进行了三个变形:最大池化层由一个RoI池化层取代,网络最后一层由两个子层取代,网络接受图像和RoI两种输入
3)检测微调
快速R-CNN将softmax 分类器和bbox 回归一起优化,解决参数微调不能后向传播到SPP之前层的问题,整个流程包括loss,mini-batch sampling,bp through RoI pooling layers, SGD hyperparameters.
A. multi-task loss
使用multi-task loss联合训练分类及回归:
k∗
是真是类标记,
Lcls(p,k∗)=−logpk∗
为标准log损失。
Lcoc
是类
k∗
的bbox的真实坐标
t∗
和预测坐标t定义,bbox回归的loss为:
L1
loss比起
L2
loss对outliers更不敏感,
λ
是平衡两种loss的超参数
B. mini-batch sampling
每个SGD的mini-batch由N=2副图构建,mini-batch的数目R为128,从每副图中采样64个RoI,从proposal中选取与ground truth的IoU>0.5的RoI作为正样本,其余的IoU值在[0.1,0.5)之间的作为负样本。
C. BP through RoI pooling layers
multi-task loss在RoI 池化层的R个输出上进行平均,RoI池化层的后向传播计算损失函数对每个输入变量x的偏导:
D. SGD 超参数
全连接层由零均值高斯分布初始化,方差为0.01和0.001,权值学习率为1,偏量学习率为2,30k mini-batch迭代。
2.快速R-CNN检测
输入一个单尺度图像和约2000个proposals,对于每个RoI r,网络输出r的后验概率和bbox,根据概率分配一个置信水平给r。
A. Truncated SVD for faster detection
需要处理的RoI比较多,网络需要花将近一半的时间在全连接层上,论文使用truncated SVD压缩全连接层,全连接层又
u×v
的权值矩阵W表示:
W≈UΣtVT
因式分解过程中,U是W的前t个左奇异向量,
Σt
是W奇异值组成的对角矩阵,V是W的前t个右奇异向量,truncated SVD将参数的个数由uv降到t(u+v)。对应W的全连接层被分解成两个,第一个使用权值矩阵
ΣtVT
,第二个使用U,实现了对网络的















 389
389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









