







Author
Ross Girshick
Abstract
Compared to SPP net, Fast R-CNN trains VGG16 x3 faster, tests 10x faster, and is more accurate.
1 Introduction
Localization challenges:
1. numerous candidate object locations must be processed.
2. these candidates provide only rough localization that must be refined to achieve precise localization.
Solutions to these problems often compromise speed, accuracy, or simplicity.
In this paper, we jointly learns to classify object proposals and refine their spatial locations.
1.1 R-CNN and SPP net
Rcnn’s drawbacks:
1. training is multi-stage pipeline:
Finetunes net using log loss–>fit SVM —>bounding-box regressors
2. Training is expensive in space and time. For svm and bb training, features are extracted from each object proposal in each image and written to disk.
3. Object detection is slow. At test-time, features are extracted from each object proposal in each test image.
SPP net’s drawback:
1. Multi-stage pipeline
extracting features–>fine-tuning with log loss—>training SVMs—->fitting bounding-box regressors
2. Features are also written to disk
3. cannot update the convolutional layers (fixed)
1.2 contributions
- Higher accuracy
- Training is single-stage,using a multi-task loss.
- Training can update all network layers
- No disk storage is required for feature caching
2 Architecture and training
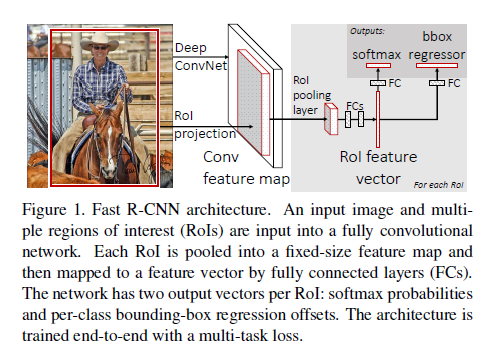
1. The network first processes the whole image to produce a conv feature map.
2. for each object proposal a RoI layer extracts a fixed-length feature vector from the feature map(like spp layer did)
3. feature vector is feed into fc layers and finally branch into two sibling output layers: one for k+1 probability, one that outputs 4 real-valued numbers(refined bounding-box positions) for each of the K object classes.
2.1 RoI pooling layer
Each RoI is defined by a four-tuple(r,c,h,w):top-left corner(r,c),height and width(h,w).RoI is simply the special-case of SPP in which there is only one pyramid level.
2.2 Initializing from the pre-trained networks
- the last max pooling layer is replaced by a RoI pooling layer
- The last fc layer and softmax are replace with two sibling layers( a fully connected layer and softmax over K+1 categores and category-specific bounding-box regressor)
- The network is modified to take two data input: a list of images and a list of RoIs in thos images.
2.3 Fine-tuning for detection
?

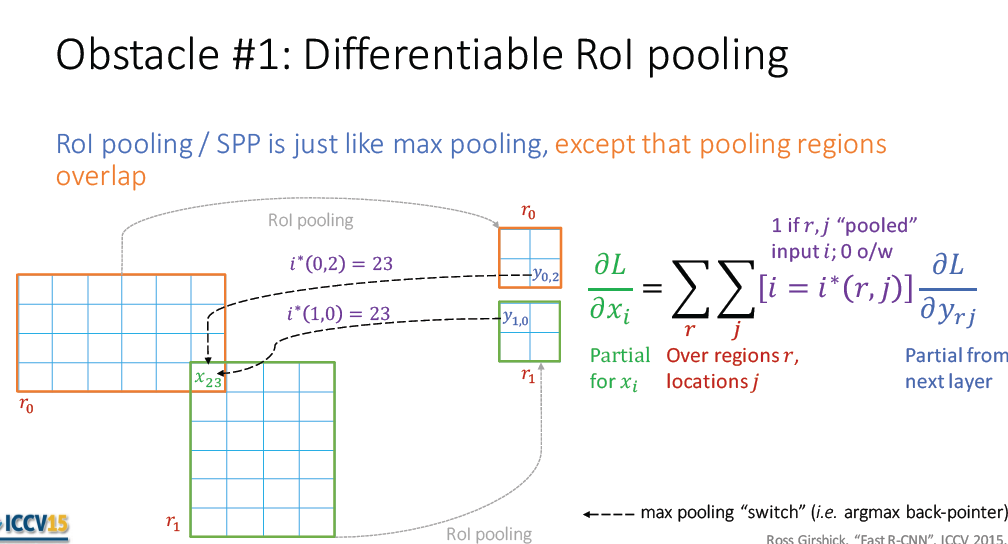
Let’s elucidate why sppnet is unable to update weights below the SPP layer: backpropagation through the SPP layer is highly inefficient when each training sample comes from a different image,because the training inputs are large(often the entire image(????)).
A more efficient training method that takes advantage of feature sharing during training. SGD minibatches are sampled hierarchically,first by sampling N images and then by sampling R/N RoIs from each image. Critially, RoIs from the same image share computation and memory in the forward and backward passes. for example, when using N=2 and R=128, the proposed training scheme is roughly 64x faster than sampling RoI from 128 different images.
In addition to hierarchical sampleing, Fast rcnn uses a streamlined training process with one fine-tuning stage that jointly optimizes classifier and bb regressors.
2.3.1 multi-task loss
?
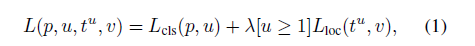
By convention the catch-all background class is labeled u=0
ground-truth class u, ground-truth bounding-box regression target v
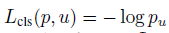
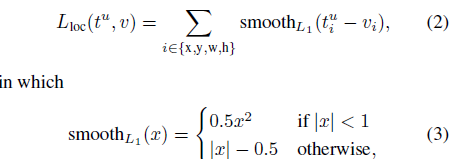
L1 loss is less sensitive to outliers than the l2 loss used in R-CNN and SPPnet, when the regression targets are unbounded (???)training with l2 loss can require careful tuning of learning rates in order to prevent exploding gradients.
λ
controls the balance between the two task losses.
2.3.2 Mini-batch sampling
We take 25% of the RoIs from object proposals that have IoU overlap with a groundtruth box of at least 0.5, the remaing RoIs are sampled from object proposals that have a maximum ioU in [0.1,0.5), are background example(u=0).
2.3.3 Backpropagation through RoI pooling Layers
?
2.4 Scale invariance
single scale vs. multi-scale
3 Fast R-CNN detection
?
The network takes as input an image (or an image pyramid , encouded as list of images) and a list of R object proposals to score, at test time, R is typically around 2000, although we will consider cases in which it is larger.(???)
when using an image pyramid each RoI is assigned to the scale such that the scaled RoI is closest to 224 pixel in area(????)
For each test RoI r we perform non-maximun surppression independently for each class.
3.1 Truncated SVD for faster detection
?
For detection the number of RoIs to process is large and nearly half of the forward pass time is speet computing the fully connected layer. Large fully connected layers are easily accelerated by compressing them with truncated SVD(??????)
#svd
E. Denton, W. Zaremba, J. Bruna, Y. LeCun, and R. Fergus.
Exploiting linear structure within convolutional networks for
efficient evaluation. In NIPS, 2014.
J. Xue, J. Li, and Y. Gong. Restructuring of deep neural
network acoustic models with singular value decomposition.
In Interspeech, 2013.4 Main results
- state-of-the-art mAP on voc07 2010 2012
- Fast training and testing compared to Rcnn and sppnet
- Fine-tuning conv layers in vgg16 imporves mAP
4.2 voc2010 2012
on voc10, **SegDeepM**achieves a higher mAP than Fast RCNN, it is designed to boost rcnn accuracy by using a markov random field to reason over r-cnn detecions and segmentations from the O2P semantic segmentation method.
#segdeepm
Y. Zhu, R. Urtasun, R. Salakhutdinov, and S. Fidler.
segDeepM: Exploiting segmentation and context in deep
neural networks for object detection. In CVPR, 2015.
#o2p
J. Carreira, R. Caseiro, J. Batista, and C. Sminchisescu. Semantic
segmentation with second-order pooling. In ECCV,
2012. 5Fast R-cnn also eliminates hundreds of gigabytes of disk storage, becuase it does not cache features.
4.4.1 Truncated SVD
Truncated SVD can reduce detection time by more than 30% with only a small (0.3%)drop in mAP, and without needing to perform additional fine-tuning after model compression.
Further speed-ups are possible with smaller drops in mAP if one fine-tnes again afer compression.
4.5 Which layers to fine tune

1. updating from conv2_1 slows training by 1.3x compared to learning from conv3_1. higher 0.3%
2. updating from conv1_1 over-runs gpu memory
5 Design evaluation
5.1 Does multi-task training help?

5.2 Scale invariance: to brute force or finesses
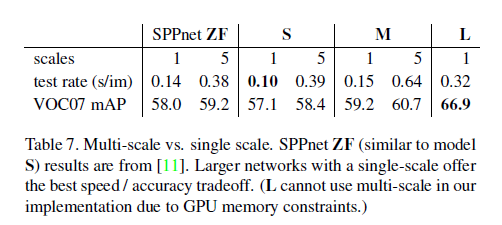
The multi-scale approach offers only a small increase in mAP at a large cost in compute time
5.3 Do we need more training data?
Zhou found that DPM mAP saturates after only afew hundred to thousand training examples.
A good object detector should improve when supplied with more training data.
5.4 SVM vs. Softmax
use the same training algorithm and hyperparameters as in RCNN
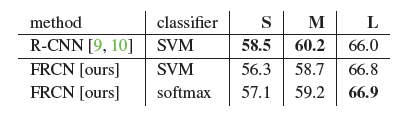
We note that softmax ,unlike one-vs-rest SVMs , introduces competition between classes when scoring a RoI.
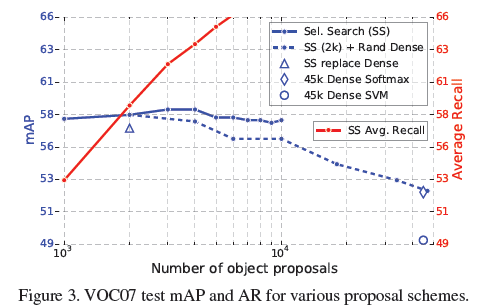
5.5 Are more proposals always better?
we find evidence that the proposal classsifier cascade aslso improves Fast RCNN
#cascade
P. Viola and M. Jones. Rapid object detection using a boosted
cascade of simple features. In CVPR, 2001. 8
#What makes for effective detection proposals?
http://www.robots.ox.ac.uk/~vgg/rg/papers/hosang_pami15.pdf
#AR
K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling
in deep convolutional networks for visual recognition. In
ECCV, 2014conclusion
BTW:
http://blog.csdn.net/shenxiaolu1984/article/details/51036677















 4605
4605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









