







caffe里自带的convert_imageset.cpp直接生成一个data和label都集成在Datum的lmdb(Datum数据结构见最
后),只能集成一个label。而我们平时遇到的分类问题可能会有多个label比如颜色,种类等。
目前网上有多种解决方法:
1. 修改caffe代码,步骤繁琐,但是对于理解代码有帮助
2. 加入多个data和label层作为输入,简单可行,但是需要准备多个lmdb,较为麻烦
3. 等等等
注意:caffe的数据层输入格式(batch_size, c, h, w),通道是BGR
本文采用多label的lmdb+Slice Layer的方法
- 生成多label的lmdb
import numpy as np
import os
import lmdb
from PIL import Image
import numpy as np
import sys
# Make sure that caffe is on the python path:
caffe_root = 'your caffe root path'
sys.path.insert(0, caffe_root + '/python')
import caffe
####################pre-treatment############################
#txt with labels eg. (0001.jpg 2 5)
file_input=open('your label txt','r')
img_list=[]
label1_list=[]
label2_list=[]
for line in file_input:
content=line.strip()
content=content.split(' ')
img_list.append(int(content[1]))
label1_list.append(int(content[1]))
label2_list.append(int(content[2]))
del content
file_input.close()
####################train data(images)############################
#your data lmdb path
#注意一定要先删除之前生成的lmdb,因为lmdb会在之前的数据基础上新增数据,而不会先清空
#os.system('rm -rf ' + your data(images) lmdb path)
in_db=lmdb.open('your data(images) lmdb path',map_size=int(1e12))
with in_db.begin(write=True) as in_txn:
for in_idx,in_ in enumerate(img_list):
im_file='your images path'+in_
im=Image.open(im_file)
im = im.resize((w,h),Image.BILINEAR)#放缩图片,分类一般用
#双线性BILINEAR,分割一般用最近邻NEAREST,**注意准备测试数据时一定要一致**
im=np.array(im) # im: (w,h)RGB->(h,w,3)RGB
im=im[:,:,::-1]#把im的RGB调整为BGR
im=im.transpose((2,0,1))#把height*width*channel调整为channel*height*width
im_dat=caffe.io.array_to_datum(im)
in_txn.put('{:0>10d}'.format(in_idx),im_dat.SerializeToString())
print 'data train: {} [{}/{}]'.format(in_, in_idx+1, len(file_list))
del im_file, im, im_dat
in_db.close()
print 'train data(images) are done!'
######train data of label################
#your labels lmdb path
in_db=lmdb.open('your labels lmdb path',map_size=int(1e12))
with in_db.begin(write=True) as in_txn:
for in_idx,in_ in enumerate(img_list):
target_label=np.zeros((2,1,1))# 2种label
target_label[0,0,0]=label1_list[in_idx]
target_label[1,0,0]=label2_list[in_idx]
label_data=caffe.io.array_to_datum(target_label)
in_txn.put('{:0>10d}'.format(in_idx),label_data.SerializeToString())
print 'label train: {} [{}/{}]'.format(in_, in_idx+1, len(file_list))
del target_label, label_data
in_db.close()
print 'train labels are done!'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 修改prototxt
layer {
name: "data"
type: "Data"
include {
phase: TRAIN
}
data_param {
source: "your data(images) lmdb"
batch_size: 10
backend: LMDB
}
top: "data"
}
layer {
name: "label"
type: "Data"
top: "label"
include {
phase: TRAIN
}
data_param {
source: "your labels lmdb"
batch_size: 10
backend: LMDB
}
}
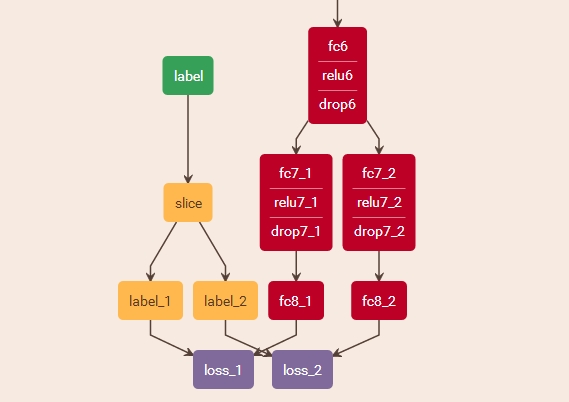
layer {
name: "slice"
type: "Slice"
bottom: "label"
top: "label_1"
top: "label_2"
slice_param {
axis: 1
slice_point: 1
}
# 假如有3个label,n个同理
# slice_point: 1
# slice_point: 2
# axis指定目标轴,batch_size,c,h,w 刚刚生成label时c就是label种类数,c在第1个维度(batch_size是0)
# slice_point指定选定维数的索引(索引的数量必须等于blob数量减去一)。
# 比如10维,输出3个label 且slice_point: 2 slice_point: 6
# 1 2 | 3 4 5 6 | 7 8 9 10 '|' 为切点(1,2)(3,4,5,6)(7,8,9)
# 这种切点我们暂时可忽略
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
总结
本文把多个label集成到一个lmdb中,最后在prototxt中通过Slice层分离开,避免了多个lmdb的繁琐,整体操作起来简单易懂。
知识延伸
Datum数据结构定义如下,上述代码直接用caffe.io.array_to_datum转化成Datum,其实可以根据它的结构一一
设置,比如datum.channels = 3,datum.data = im.tobytes() (im为图像数组shape为(3,224,224)),根据caffe
说明,图像数据也可以放在float_data中)
因为caffe中的图像样例是单个label,所以可以把图像的label存储于Datum中的label,但是多label的话就不行
了,需要用上述的方法把多label存储于Datum中的data
message Datum {
optional int32 channels = 1;
optional int32 height = 2;
optional int32 width = 3;
// the actual image data, in bytes
optional bytes data = 4;
optional int32 label = 5;
// Optionally, the datum could also hold float data.
repeated float float_data = 6;
// If true data contains an encoded image that need to be decoded
optional bool encoded = 7 [default = false];
}
以下介绍另一种修改源码的方法实现多label,比其他博客改动源码最少简介
我们都知道ImageDataLayer是直接读取原图进行分类,它的label是单label,文件格式如下
train.txt示例
001.jpg 1
002.jpg 2
003.jpg 3
layer {
name: "demo"
type: "ImageData"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
scale: 0.00390625
mean_value: 128
}
image_data_param {
source: "your path/train.txt"
root_folder: "your image data path"
new_height: xxx
new_width: xxx
batch_size: 32
shuffle: true #每个epoch都会进行shuffle
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
修改代码
由于ImageataLayer的限制,我们只能在train.txt中放置单label,现在我们来修改ImageataLayer的代码来实现多label
主要涉及三个文件
- caffe/src/caffe/proto/caffe.proto
- caffe/include/caffe/layers/image_data_layer.hpp
- caffe/src/caffe/layers/image_data_layer.cpp
定位到caffe/src/caffe/proto/caffe.proto中message ImageDataParameter
// 添加一个参数
// Specify the label dim. default 1.
// 有几种label,比如性别、年龄两种label,在网络结构里就把此参数设置为2
optional uint32 label_dim = 13 [default = 1];
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
定位到caffe/include/caffe/layers/image_data_layer.hpp
// 修改vector<std::pair<std::string, int> > lines_;
// string对应那个train.txt中的图片名称,in对应label,我们把int改为int*,实现多label
vector<std::pair<std::string, int *> > lines_;
- 1
- 2
- 3
- 1
- 2
- 3
定位到caffe/src/caffe/layers/image_data_layer.cpp
// DataLayerSetUp函数
// 原本的加载图片名称和label的代码
std::ifstream infile(source.c_str());
string line;
size_t pos;
int label;
while (std::getline(infile, line)) {
pos = line.find_last_of(' ');
label = atoi(line.substr(pos + 1).c_str());
lines_.push_back(std::make_pair(line.substr(0, pos), label));
}
// 修改为这样
std::ifstream infile(source.c_str());
string filename;
// 获取label的种类
int label_dim = this->layer_param_.image_data_param().label_dim();
// 注意这里默认每个label直接以空格隔开,每个图片名称及其label占一行,如果你的格式不同,可自行修改读取方式
while (infile >> filename) {
int* labels = new int[label_dim];
for(int i = 0;i < label_dim;++i){
infile >> labels[i];
}
lines_.push_back(std::make_pair(filename, labels));
}
// 原本的输出label
vector<int> label_shape(1, batch_size);
top[1]->Reshape(label_shape);
for (int i = 0; i < this->prefetch_.size(); ++i) {
this->prefetch_[i]->label_.Reshape(label_shape);
}
// 修改为这样
vector<int> label_shape(2);
label_shape[0] = batch_size;
label_shape[1] = label_dim;
top[1]->Reshape(label_shape); // label的输出shape batch_size*label_dim
for (int i = 0; i < this->PREFETCH_COUNT; ++i) {
this->prefetch_[i].label_.Reshape(label_shape);
}
// 注意:caffe最新版本prefetch_的结构由之前的Batch<Dtype> prefetch_[PREFETCH_COUNT];
// 改为 vector<shared_ptr<Batch<Dtype> > > prefetch_; 由对象数组改为了存放shared指针的vector。
// 所以此处的this->PREFETCH_COUNT改为this->prefetch_.size();
// 此处的this->prefetch_[i].label_.Reshape(label_shape);
// 改为this->prefetch_[i]->label_.Reshape(label_shape);把.改成指针的->
// load_batch函数
// 在函数一开始先获取下label_dim参数
int label_dim = this->layer_param_.image_data_param().label_dim();
// 原本的预取label
prefetch_label[item_id] = lines_[lines_id_].second;
// 修改为这样
for(int i = 0;i < label_dim;++i){
// lines_[lines_id_].second就是最开始改为的int*,多label
prefetch_label[item_id * label_dim + i] = lines_[lines_id_].second[i];
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
最后进行make
示例
train.txt
001.jpg 1 3 2
002.jpg 2 4 7
003.jpg 3 0 9
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
# trainval.prototxt
layer {
name: "data"
type: "ImageData"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
mean_value: 128
mean_value: 128
mean_value: 128
}
image_data_param {
mirror: true
source: "your path/train.txt"
root_folder: "your image data path"
new_height: xxx
new_width: xxx
batch_size: 32
shuffle: true #每个epoch都会进行shuffle
label_dim: 3
}
}
layer {
name: "slice"
type: "Slice"
bottom: "label"
top: "label_1"
top: "label_2"
top: "label_3"
slice_param {
axis: 1
slice_point:1
slice_point:2
}
}
......
# 后续代码参考我另一篇caffe实现多label输入的代码
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41

总结
对比其他修改源码的博客,本篇对源码的改动最少,而且兼容原来的版本,最重要的是使用起来最方便,不用生成lmdb之类
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12















 870
870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









