







This example is based on PASCAL VOC 2012, I think the matters of the blog are as follows:
1. Python data layer
2. SigmoidCrossEntropyLoss
1 Preliminaries
- make sure you compile caffe using WITH_PYTHON_LAYER:=1
- PASCAL VOC 2012 http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
- import modules, set data directories (pascal_root)and initialize caffe(caffenet again)
2 Define network prototxts
we have to note how the SigmoidCrossEntropyLayer and python data layer are defined.
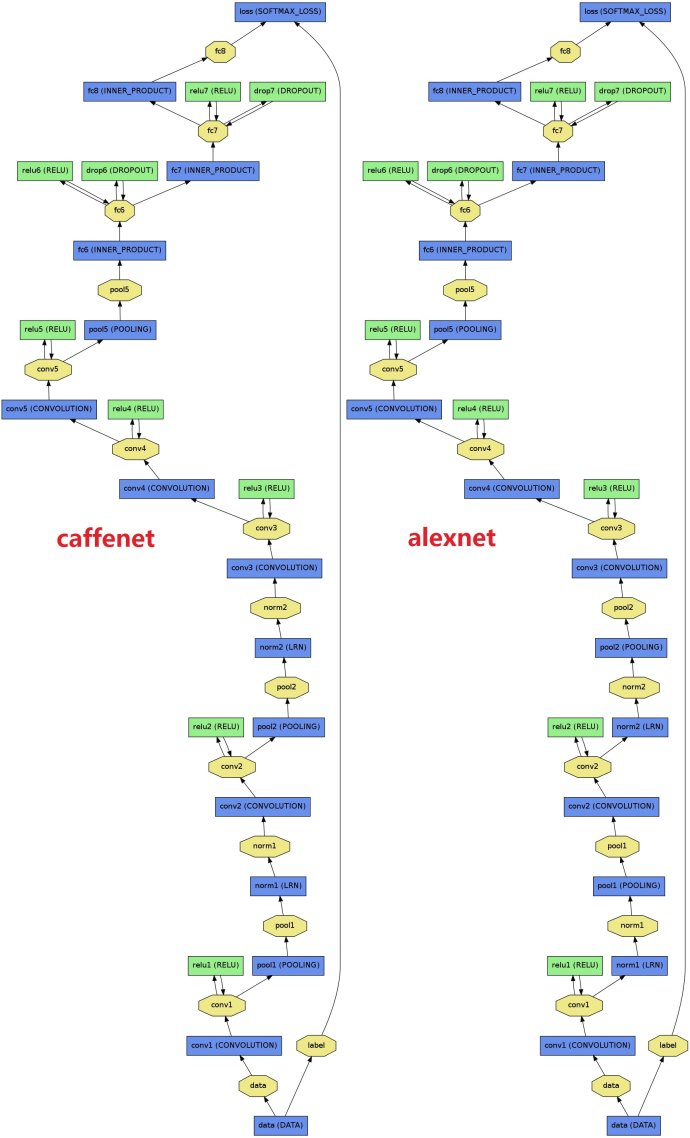
before we start it,let us see the architecture of caffenet and alexnet:
2.1 caffe.NetSpec
def conv_relu(bottom,ks,nout,stride=1,pad=0,group=1):
conv=L.Convolution(bottom,kernel_size=ks,stride=stride,num_output=nout,pad=pad,group=group)
return conv,L.ReLU(conv,in_place=True)
def fc_relu(bottom,nout):
fc=L.InnerProduct(bottom,num_output=nout)
return fc,L.ReLU(fc,in_place=Ture)
def max_pool(bottom,ks,stride=1):
return L.Pooling(bottom,pool=P.Pooling.MAX,kernel_size=ks,stride=stride)
def caffenet_multilabel(data_layer_params,datalayer):
n=caffe.NetSpec()
n.data,n.label=L.Python(module='pascal_multilabel_datalayers',layer=datalayer,ntop=2,param_str=str(data_layer_params))
n.conv1,n.relu1=conv_relu(n.data,11,96,stride=4)
n.pool1=max_pool(n.relu1,3,stride=2)
n.norm1=l.LRN(n.pool1,local_size=5,alpha=1e-4,beta=0.75)#Local Response Normalization
n.conv2,n.relu2=conv_relu(n.norm1,5,256,pad=2,group=2)
n.pool2=max_pool(n.relu2,3,stride=2)
n.norm2=L.LRN(n.pool2,local_size=5,alpha=1e-4,beta=0.75)
n.conv3,n.relu3=conv_relu(n.norm2,3,384,pad=1)
n.conv4,n.relu4...
n.conv5,n.relu5
n.pool5
n.fc6,rule6=
n.drop6=L.Dropout(n.relu6,in_place=True)
n.fc7,rule7=
n.drop7
n.score=L.InnerProduct(n.drop7,num_output=20)
n.loss=L.SigmoidCrossEntropyLoss(n.socre,n.label)
return str(n.to_proto())2.2 CaffeSolver &step(1)
solverprotxt=tools.CaffeSolver(trainnet_protxt_path=...,testnet_prototxt_path=...)
solverprototxt.sp['display']='1'
solverprototxt.sp['base_lr']='0.0001'
solverprototxt.write('your path')
with open('path','w') as f :
data_layer_params=dic(bathc_size=32,im_shape=[227,227],split='train',pascal_root=pascal_root)
f.write(caffenet_multilabel(data_layer_params,'pascalMultilabelDataLayerSync'))#difined in './pycaffe/layers/pascal_mutilabel_datalayer.py'let’s review what we do in the past:
from caffe.proto import caffe_pd2
s=caffe_pb.SolverParameter()
s.random_seed=x
s.xx=xx
with open(yourpath,'w')as f:
f.write(str(s))
solver=None
solver=caffe.get_solver(yourpath)now we can load the caffe solver as usual:
solver=caffe.SGDSolver('pathpathpath')
solver.net.copy_fram('model/path/caffenet.caffemodel')
solver.test_net[0].share_with(solver.net) #i think it is important
solver.step(1)let’s check the data we have loaded.
transformer=tools.SimpleTransformer()#good tool
image_index=0
plt.figure()
plt.imshow(transformer.deprocess(copy(solver.net.blobs['data'].data[image_index,...])))
gtlist=solver.net.blobs['label'].data[image_index,...].astype(np.int)
plt.title('GT:{}'.format(classes[np.where(gtlist)]))# classes are defined in the ahead step.
plt.axis('off')2.3 train
as we used to do, we need some way to measure the accuracy
. here, for multilabel problems, hamming distans is commonly used.
def hamming_distance(gt,est):
return sum([1 for (g,e) in zip(gt,est)if g==e])/float(len(gt))
def check_accuracy(net,num_baches,batch_size=32):
acc=0.0
for t in range (num_bathces):
net.forward ()
gts=net.blobs['label'].data
ests=net.blobs['score'].data>0
for gt,est in zip(gts,ests):
acc+=hamming_distance(gt,est)
return acc/(num_batches*batch_size)
###let us train for a while
for itt in range(6):
solver.step(100)
print 'itt:{:3d}.format((itt+1)*100)','accuracy:.{0:.4f}'.format(check_accuracy(solver.test_nets[0],50))the results are 0.9526…0.9591
it looks high, but let us see the baseline accuracy:
def check_baseline_accuracy(net,num_baches,batch_size=32):
acc=0.0
for t in range (num_bathces):
net.forward ()
gts=net.blobs['label'].data
ests=np.zeros((batch_size,len(gts)))
for gt,est in zip(gts,ests):
acc+=hamming_distance(gt,est)
return acc/(num_batches*batch_size)
print 'baseline',check_baseline_accuracy(solver.test_net[0],5823/32)the baseline accuracy is 0.9238!
we can look at some prediction results
test_net=solver.test_net[0]
for image-index in range(5):
plt.figure()
plt.imshow(transformer.deprocess(copy(test_net.blobs['data'].data[image_index,...])))
gtlist= test_net.blobs['label'].data[image_index,...].astype(np.int)
estlist=test_net.blobs['score'].data[image_index,...]
plt.title(classes[np.where(gtlist)],'est',classes[np.where(estlist)])
plt.axis('off')














 2951
2951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









