







1.在多个reducetask的并且进行全局排序的时候报出错误:
java.io.IOException:wrong key class: org.apache.hadoop.io.Text is not class org.apache.hadoop.io.LongWritable
这个问题原因是输入的Key和输出的key不一致导致的。为什么会导致这个问题呢?
Hadoop 全局排序采用的算法:二分检索,随机取样。
思想:分而治之
如果每个分区只有一个元素,分区间排好序列那么全局就排好序了。
在分区间排好序的前提下,如果分区内排好序了,那么全局就排好序了。
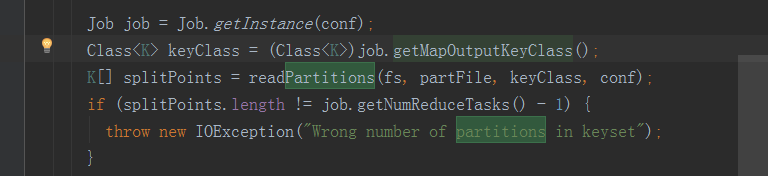
2.分区间排序,可以通过shuffle的时候来对各个分区进行标尺。标尺的标准和如何比对呢?
可以在输入的时候进行一个取样,这个取样就是根据reduce的key进行取样的。然后标识各个分区的分割线(二分检索)。
reduce端拉取数据后,要形成一个全局有序的文件,那么输出的key就会和输入的key比较(比较分割线看这个key应该放在哪个文件中)。如果标尺的key类型和reduce输出的key类型不一样直接就会报错。
代码如下:















 1138
1138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









