







容器部分归纳为三篇来写,分别从基本用法,深入研究,以及在算法中的应用。本章主要介绍深入研究,具体实现部分。
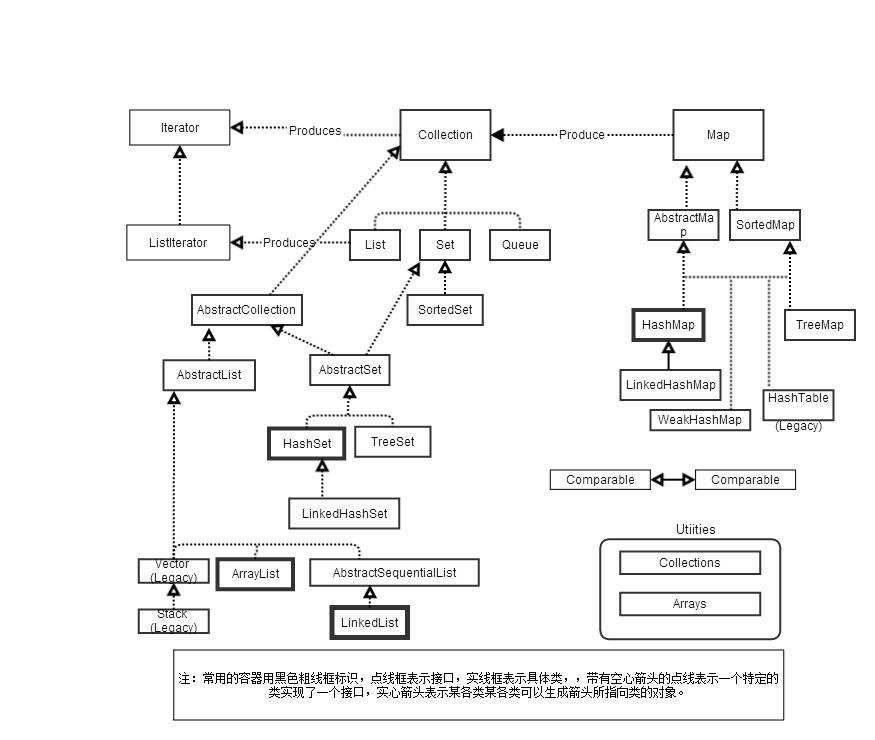
上图是集合类库的完备图,包括抽象类和遗留构件。
Collection
List
List是有序的,跟插入的顺序对应。基本的List很容易使用:大多数时候只是调用add()添加对象,使用get()一次取出一个元素,以及调用iterator()获取用于该序列的Iterator。
Set和存储顺序
Set是自己维护内部顺序的,Set在执行诸如Integer和String这样的java预定义的类型时,这些类型被设计为可以在容器内部使用。当你创建自己的类型时要意识到Set需要一种方式来维护存储顺序,而存储顺序如何维护,则是在Set的不同实现之间有变化。
- Set(Interface) 存入Set的每个元素都必须是唯一的,因为Set不保存重复的元素。加入的元素必须定义equals()方法以确保对象的唯一性。Set和Collection有完全一样的接口。Set接口不保证维护元素的次序。
- HashSet*(默认) 为快速查找而设计的Set。存入HashSet的元素必须定义HashCode()。
- TreeSet 保持次序的Set,底层为树结构。使用它可以从Set中提取有序的序列。元素必须实现Comparable接口。
- LinkedHashSet 具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入顺序)。于是在使用迭代器遍历Set时,结果会按元素的插入顺序显示。元素也必须定义hashCode()方法。
从上面对比可以看出,我们必须为散列存储和树形存储创建一个hashCode()方法,为了有个良好的编程方法,我们在覆盖equals方法时也覆盖hashCode方法,只有在至于HashSet时HashCode方法才起作用。以下代码是具体实现。
class SetType{
int i;
public SetType(int n){i = n;}
@Override
public boolean equals(Object obj) {
return obj instanceof SetType && (i == ((SetType)obj).i);
}
public String toString(){
return Integer.toString(i);}
}
class HashType extends SetType{
public HashType(int n){
super(n);}
public int hashCode(){
return i;}
}
class TreeType extends SetType
implements Comparable<TreeType>{
public TreeType(int n){
super(n);}
@Override
public int compareTo(TreeType o) {
return (o.i < i? -1 :(o.i == i?0:1));
}
}
public class MockSet {
static <T> Set<T> fill(Set<T>set, Class<T> type){
try {
for(int i=0; i<10;i++){
set.add(type.getConstructor(int.class).newInstance(i));
}
} catch (Exception e) {
throw new RuntimeException(e);
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1543
1543











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









