







大端模式(Big_endian):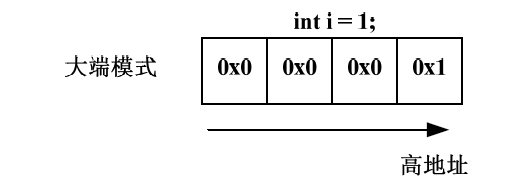
小端模式(Little_endian):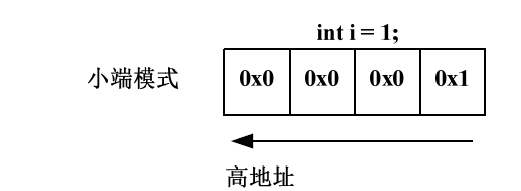
判定:
union A
{
short m;
char arr[2];
};
void test()
{
A k;
k.m = 0x0102;
if (k.arr[0] == 1)
{
printf("k.arr[0] %d \n",k.arr[0]);
printf("Big \n");
}
else
{
printf("k.arr[1] %d \n", k.arr[1]);
printf("small \n");
}
}运用:
#include<stdio.h>
int main()
{
int a[5]={1,2,3,4,5};
int *ptr1=(int *)(&a+1);
int *ptr2=(int *)((int)a+1);
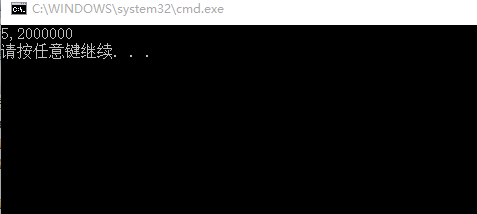
printf("%x,%x",*ptr2,ptr1[-1]);
return 0;
}
分析:
1.> int ptr2=(int )((int)a+1);
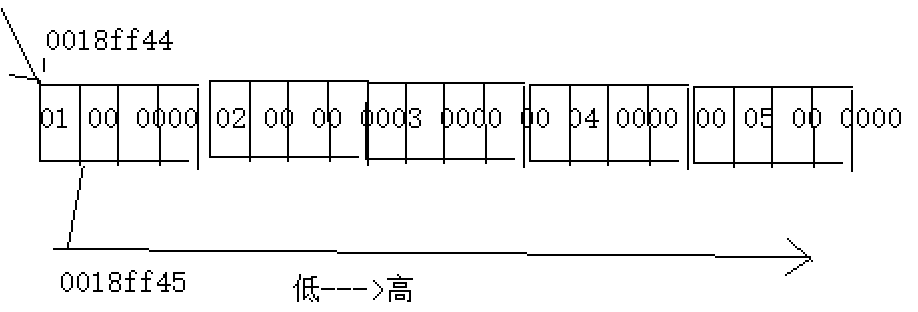
将a强制类型转换为int,假设a的地址也就是数组首元素的地址为0018ff44,则(int)a+1==0018ff45,在将其强制类型转换为指针,此时ptr2==0018ff45;
由上图可知,该地址的大小是从低—>高排列, 而我的编译器是以小端形式存储,故低位在放低地址,(在32位操作系统中,32位和64位系统中,编译器为了相互兼容,所以指针都是4个字节长度。)故而*ptr2为02 00 00 00;
2.>对于数组名存在两个方式不会发生降级的情况,一个是sizeof(数组名),此处指该数组的整个大小,另一个就是此处的&a,此时指数组的整个地址,和数组首元素的地址相同,如
int arr[5]={0};
int *pa=arr;
int *pb=&arr;
printf("%p\n%p\n",pa,pb);
既数组首元素的首地址和整个数组的首地址是相同的,但是当分别对arr和&arr+1之后,你会发现它们的地址就会不在相同,因为arr指数组的首元素,而&arr却指的是整个数组
int arr[5]={0,1,2,3,4};
int *pa=arr +1 ;
int *pb=&arr+1 ;
printf("%8d %d\n",*pa,*pb) ;
printf("%p %p\n",pa,pb);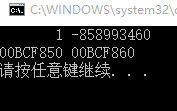















 4359
4359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









