







1 前言
2 收集数据
3 探索数据
4 选择模型
5 准备数据
数据被输入模型之前,需要将数据转换成模型能理解的格式,该过程被称之为数据标准化。
首先,已收集到的数据样本可能是以指定的顺序存储,而在实际分析中,期望文本与标签的关系是不能受到与数据样本的顺序相关的信息的影响。例如,如果数据集合是根据类别排序的,然后,数据集合被分割成训练数据集合与验证数据集合两个部分,则这些数据集合并不能表示出原始数据的整体分布。
保证模型不受数据顺序影响的一个简单的最佳实践是,在处理数据之前对数据集合执行乱序的处理(比较随机的顺序),一般情况下,在对数据执行乱序处理之后,将原始数据集合的80%划分为训练数据集合,将原始数据集合的20%划分为验证数据集合,在数据集合分割完成之后,需要保证使用相同的数据标准化的处理方法转换原始数据集合。
其次,机器学习算法输入的数据类型是数字类型。也就是,需要将前面所述的文本数据集合转换成数字化的向量集合,这是一个数据标准化的处理过程,其包括以下两个步骤:
| 步骤1:分词 将文本分割成单词或者更小的子文本单元,有利于更好地生成文本与标签的关系,该方法可以确定数据集合的词汇。 |
| 步骤2:向量化 定义一个好的数字度量单位对文本执行特征化处理。 |
以下内容将描述如何使用以上方法的两个处理步骤执行n-gram向量与序列向量的处理,同时,也将描述如何使用特征选择以及标准化的技术优化向量的表示。
N-gram向量集
n-gram向量集是指如何使用n-gram模型执行分词以及向量化,其中也包括如何使用特征选择以及标准化的技术优化n-gram模型的表示。
在一个n-gram的向量集合中,文本被表示成一个包括唯一性元素的n-grams集合:n个相邻分词的分组(一般是单词分组),例如,对于句子【The mouse ran up the clock】,当n等于1,则1-gram分词的集合是['the', 'mouse', 'ran', 'up', 'clock'],当n等于2,则2-gram分词的集合是['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'],当n等于其他数值,也是按照这种分词方法实现n-gram分词的集合。
分词
理论上,将文本分割成混合的组成,例如,包括1-gram与2-gram的混合模型,具有更好的准确度以及消耗更小的计算时间。
向量化
分词的步骤执行完成之后,向量化需要把分词所得的1-gram以及2-gram集合中的元素转换成数字向量集合,该数字化的向量集合能够被机器学习的模型识别与处理。如下所示,两个文本句子的分词与索引列表:

如上所示,其中Texts表示输入的两个文本句子,Index表示赋予每个分词元素的索引,这些数据样本集合中的元素在索引上是乱序的,并不能表示出原始数据文本的顺序。
使用以上的索引列表(12个索引元素,索引位置从0到11,索引位0表示clock,索引位1表示down,依次类推),分别使用三种编码方式实现文本的向量化,One-hot encoding、Count encoding与Tf-idf encoding。
One-hot encoding
该方式是以索引列表为基础,根据以上索引列表的索引顺序的每个元素,确定文本中是否出现,0表示不出现,1表示出现,如下所示:

如上所示,数字化向量集合中共12个元素,刚好对应以上索引列表的12个元素,分别识别索引元素是否在文本中出现,例如,第一位1表示clock索引元素出现(索引位是从0开始识别),第二位0表示索引元素down不出现,第三位1表示索引元素mouse出现,依次类推,从而,得出数字化的向量列表。
Count encoding
该方式是以索引列表为基础,根据以上索引列表的顺序的每个元素,确定文本中出现的次数,0表示不出现,大于0表示出现的次数,如下所示:

如上所示,第七位2表示索引元素the在文本中共出现两次,其他元素与One-hot encoding中统计的信息保持一致。
Tf-idf encoding
由以上的分析可知,One-hot encoding、Count encoding两种方法并没有处理常用的词语,例如,a或者the,这类词语在一个文本中通常出现的频率都很高,但是又没有实质性的作用,这些问题使用Tf-idf encoding编码方式可以解决,其输出的格式如下所示:

处理文本向量的表示的编码方式很多,但是以上这三种编码方式是最常用的。很明显,Tf-idf encoding比其他两种方式One-hot encoding、Count encoding的准确度更高(大概平均高出0.25-15%),因此,推荐使用Tf-idf encoding作为n-grams的向量化方式,但是该方式需要消耗更多的内存资源,因为其使用浮点数作为向量表示,在大数据集合的处理场景中,需要消耗更多的计算时间(大概是其他方式的2倍)。
特征选择
对所有的文本执行分词完成之后产生分词集合,并不是所有分词集合中的分词或者特征在特征预测中都发挥作用,因此,需要删除某些无用的分词或者特征(例如,一些出现几率很小的分词),从中抽取有用的分词或者特征,该过程被称之为特征选择,也就是,需要运用有效的方法测量这些分词或者特征的重要性(对特征预测的贡献度),并从中选取一些最有用的分词或者特征用于分析。
满足用于特征选择的算法或者函数很多,这些函数输入特征以及特征对应的标签、输出特征的重要性对应的分数。其中,函数f_classif 与函数chi2是常用的函数,实验证明这两个函数的执行效果相当。
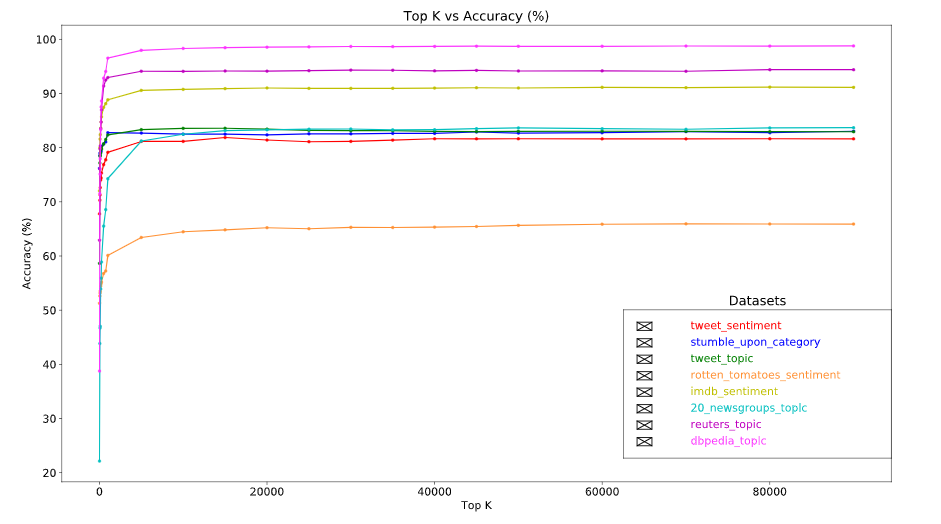
如上所示,使用的是英文文本,使用不同的数据集合以及不同的数据量对算法准确度执行评估、执行准确度的对比分析,其中,top-20k特征数据量的准确度处于稳定的水平,大于20k特征数据量的评估,则算法的运行性能会下降。
标准化
标准化是将所有的特征或者样本转换成小而且类似的值,该处理过程在机器学习算法中被称之为梯度下降(使用收敛函数),在本例中,该处理过程可以简化为以下三个步骤:
|
以上的步骤对应代码逻辑如下所示:



由以上的分析可知,n-gram向量集在实现向量化的过程中与文本的顺序无关,与n-gram向量化的表示相关联的算法包括逻辑回归、多层感知、梯度推进机、支持向量机。
(未完待续)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











