







1 前言
2 收集数据
3 探索数据
4 选择模型
5 准备数据
6 模型-构建训练评估
构建输出层
构建n-gram模型
构建序列模型
GloVe(英文全称是Global Vectors for Word Representation)是一个全球化的英语语境的单词表示的向量集,其使用非监督类型的机器学习算法生成(GloVe在后续章节中详细描述)。
IMDb数据集合与GloVe数据集合的来源不一样,因此,机器学习过程需要进行一些上下文环境的优化与调整才能在不同向量空间中实行相互融合,其调整步骤如下所示:
| 步骤1: 在第一次运行机器学习的过程中,先不使用嵌入层的向量空间参与学习,也就是,保持权重不变,其他层保持正常学习,在第一次运行机器学习过程中,让权重这些初始值先达到一个比较好的状态,在第二次运行机器学习的过程中,使用嵌入层的向量空间参与到整个神经网络的学习,第二次运行机器学习对整个神经网络的权重进行较好的调整,该过程被称之嵌入层的微调(小幅度的调优)。 |
| 步骤2: 步骤1的嵌入层的微调能够取得更好的准确度,但是该过程也大幅度地消耗更多的计算资源。实践证明,只要学习的样本足够多,使用其他的机器学习方式也能取得与嵌入层微调相同的准确度,其他机器学习方式能大幅度地降低计算资源的消耗。 |
监督型机器学习
监督型机器学习模型训练的数据包括两个部分,特征数据集(问题)以及每个特征对应的标签数据集(答案),该学习方式类似于从一系列的问题以及问题对应的答案中学习,通过机器学习之后,系统掌握了问题与答案之间的映射关系,并将这些问题与答案进行归类为某一个主题,当系统接收到全新的问题的时候,则从这些主题中寻找答案。
非监督型机器学习
非监督型机器学习模型训练的数据只包括一个部分,特征数据集,其学习的目的是从这些未被标签化的特征数据集中进行归类(聚类)于类似的分组。例如,对不同属性的音乐进行分类,然后,将分类所得的音乐集合推送给用户(推荐服务)。
半监督型机器学习
半监督型机器学习模型的数据包括两个部分,特征数据集以及一部分特征数据集对应的标签数据集,由于标签不全,需要通过机器学习推断其他未被标签化的特征数据集,标签推断完成之后,再进行全面的监督型机器学习。
实践证明,通过对比不同的序列化机器学习模型(CNN, sepCNN, RNN (LSTM & GRU), CNN-RNN),sepCNN(在后续章节中详细描述)模型是效率最高的模型,其学习表现比其他模型更加优秀,sepCNN模型(四层)的代码如下所示:




训练模型
训练模型是对前面章节中构建的模型进行训练,训练涉及到的步骤是根据模型的当前状态做出预测,计算预测的准确率,根据预测的准确率更新以及调整神经网络中的权重、参数,从而最小化模型预测的错误,最终使得构建的模型的预测更加准确,训练过程中不断重复这些预测与分析的过程,直到模型达到收敛的效果而结束训练模型的过程,该过程涉及到三个关键参数如下所示:
|
这些参数的对照信息如下所示:

如上所示,learning parameter是学习参数类型,Value是学习参数对应的名称。
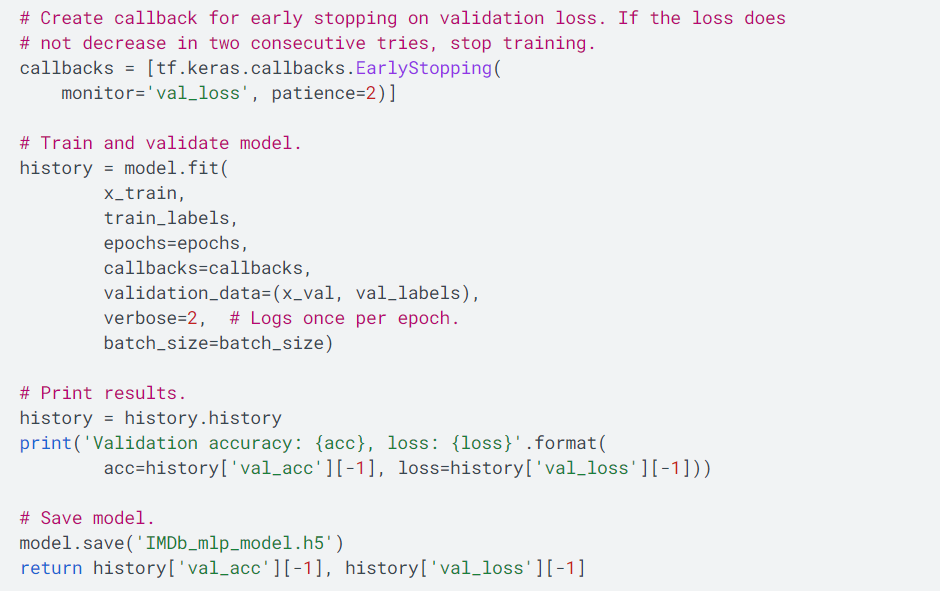
在训练流程中,主要使用模型的fit函数,根据训练数据集的规模,训练的大部分计算时间都消耗在fit函数中。在训练过程的每次迭代中,从训练数据集中提取batch_size大小的数据样本进行训练,在该次迭代中,使用损失函数计算损失值,根据损失值更新神经网络中的权重值。在训练过程中,经过多次的迭代,训练数据集已经根据batch_size大小处理了所有的批次,则该次训练过程完成,该过程被称之为一次epoch。在每次epoch完成时,使用测试数据集验证该次epoch的训练效果如何,经过多次epoch的训练,验证的训练效果的准确度达标以及准确度达到稳定的状态,则停止训练。训练的超级参数如下所示:

如上所示,Training hyperparameter是超级参数的名称,Value是超级参数对应的值。
Keras技术框架使用前面所述的调优参数以及超级参数的代码如下所示:


7 参数调优
机器学习过程中需要根据实际的需求为模型选择一些超级参数用于定义以及训练。这些参数调整建议如下所示:
| 模型的层数(Number of layers in the model) 神经网络的层数决定其复杂度,层数太多则容易产生训练过多而过度拟合,层数太少则容易产生训练不足,对于MLPs类型的文本分类模型,层数保持在1层、2层、3层,有些场景用2层最合适,对于sepCNNs类型的文本分类模型,层数保持在4层、6层,有些场景用4层最合适 |
| 每层的单元数(Number of units per layer) 单元是用于数据样本的信息转换,第一层的单元数是由特征数确定,随后的层的单元数是由前一层的输出、具体的扩展或者具体的收缩而确定,为了最小化每层信息在转换过程中信息的丢失,单元数保持的建议值是[8, 16, 32, 64],其中32或者64的单元数表现更优秀 |
| 删除比率(Dropout rate) 该处理层是用于防止过度拟合,删除一部分比较随机的特征数据,建议范围是0.2–0.5 |
| 学习速率(Learning rate) 该参数主要用于在多次迭代之间的权重值的变化的速率,保持低学习速率是比较好的设置,但是模型会执行更多的迭代,建议设置值是1e-4,如果训练过程非常缓慢,则建议提升该设置值,如果模型不训练,则建议降低该设置值 |
sepCNN模型涉及到的超级参数的调整如下所示:
| 核心大小(Kernel size) 卷积的窗口大小,建议值是3或者5 |
| 嵌入层的维度(Embedding dimensions) 用于标识嵌入向量空间的大小,每个单词的向量集合的大小,建议值是50–300,GloVe类型的嵌入向量空间的大小,建议值是200 |
8 部署模型
将训练好模型部署到具体的运行环境中,运行环境包括公用云、私有云、容器云。具体部署方式参考云计算提供商的环境部署说明。
(未完待续)
















 978
978











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











