






用于视觉识别的深度高分辨率表示学习
摘要: 高分辨率表示对于人体姿态估计、语义分割和目标检测这类位置敏感的视觉问题至关重要。现有的 sota 框架首先通过串联 high-to-low 分辨率卷积(例如ResNet、VGGNet)形成的子网将输入图像编码为低分辨率表示,然后从编码的低分辨率表示中恢复高分辨率表示。但是,HRNet在整个过程中保持高分辨率表示。HRNet 有两个关键特征:(i) 并行连接 high-to-low 分辨率卷积流;(ii) 在不同分辨率之间反复交换信息,使 HRNet 的结果在语义上更丰富,在空间上更精确。我们通过展示 HRNet在人体姿态估计、语义分割和目标检测等应用中的优越性,表明 HRNet 是解决计算机视觉问题的一个更强大的支柱。
文章目录
1 INTRODUCTION
深度神经网络 DCNNs 在图像分类、目标检测、语义分割、人体姿态估计等许多计算机视觉任务上都取得了 sota 结果。DCNNs 较传统手工制作表示的优势在于它能够学习更丰富的表示。
大多最近开发的分类网络,包括AlexNet、VGGNet、GoogleNet、ResNet等,都遵循 LeNet-5 的设计规则。该规则如图1(a)所示:逐渐减小特征图的空间大小,串联高分辨率到低分辨率的卷积,形成低分辨率表示,并进一步进行分类处理。
像语义分割、人体姿态估计和目标检测这类位置敏感的任务需要高分辨率表示。先前的 sota 方法采用高分辨率恢复过程,从分类网络或类似于分类网络输出的低分辨率表示中提高分辨率表示,其过程如图1(b)所示。代表性示例包括 SegNet、DeconvNet、U-Net、 Hourglass、encoder-decoder 和 SimpleBaseline。此外,扩张卷积(空洞卷积)也被用于移除一些下采样层,从而产生中等分辨率表示。

图1. 从低分辨率恢复高分辨率的结构。 (a) 一种低分辨率表示学习子网(如VGGNet,ResNet),通过串联 high-to-low 卷积形成。(b) 恢复子网的高分辨率表示法,通过串联 low-to-high 卷积形成。代表性示例包括 SegNet、DeconvNet、U-Net、 Hourglass、encoder-decoder 和 SimpleBaseline
我们提出了一个新的架构——HRNet,它在整个过程中保持高分辨率表示。我们以一个高分辨率卷积流开始,逐个添加 high-to-low 分辨率卷积流,并行连接多分辨率卷积流。如图2所示,HRNet由 4 (本文选4)个 stage 组成,第n stage 包含对应于 n 个分辨率的 n 个流,通过不断在并行流之间交换信息来进行重复的多分辨率融合。

图2. HRNet 的一个示例。 该示例不包括 stem (两个 stride=2 的 3×3 卷积),仅对main body进行了说明。该网络有四个stage。第一 stage 由高分辨率卷积组成。第二、第三、第四 stage 重复两分辨率、三分辨率、四分辨率 blocks。
从 HRNet 中学习到的高分辨率表示不仅在语义上很强,在空间上也更精确。这可能源于两个因素:
- HRNet 并行而非串行连接 high-to-low 分辨率流,因此 HRNet 能够保持高分辨率,而非从低分辨率中恢复高分辨率,这样学习到的表示可能在空间上更精确。
- 大多数现有的融合方案聚合了高分辨率低级别和高级别的表示,这些表示是通过对低分辨率表示进行上采样获得的。然而,我们重复多分辨率融合,在低分辨率表示的帮助下增强高分辨率表示,反之亦然。因此,所有 high-to-low 分辨率的表示在语义上都很强。
我们展示了两个版本的HRNet:(1) HRNetV1,只输出从高分辨率卷积流计算出的高分辨率表示。HRNetV1 根据热图估计框架应用于人体姿势估计上。HRNetV1 在COCO关键点检测数据集上的实验结果证明了它在姿态估计上的优越性能。(2) HRNetV2,结合所有高分辨率到低分辨率并行流的表示。HRNetV2 通过从组合的高分辨率表示中估计分割图,应用于语义分割。HRNetV2 在 PASCAL-Context,Cityscapes和LIP上实现了 sota 结果,并具有相似的模型大小和较低的计算复杂度。从实验结果可以观察到:在 COCO 姿态估计方面 HRNetv1 和 HRNetv2 具有相似性能;在语义分割方面 HRNetV2 较 HRNetV1 优秀。
此外,我们从 HRNetV2 的高分辨率表示输出中构造了一个多级表示——HRNetV2p,并将其应用于 sota 检测框架,包括Faster-R-CNN、Cascade RCNN、FCOS 和 CenterNet,以及 sota 联合检测和实例分割框架,包括Mask R-CNN、Cascade Mask R-CNN,和 Hybrid Task Cascade。结果表明,我们的方法能提高检测性能,尤其显著提高了对小目标的检测性能。
2 RELATED WORK
我们从低分辨率表示学习、高分辨率表示恢复和高分辨率表示保持三个方面回顾了主要用于人体姿态估计、语义分割和目标检测的表示学习技术。此外,我们还提到了一些与多尺度融合有关的工作。
Learning low-resolution representations 学习低分辨率表示: 完全卷积网络方法通过移除分类网络中的全连接层来计算低分辨率表示,并估计它们的粗略分割图。通过组合从中度低层中分辨率表示( intermediate low-level medium-resolution representations)或迭代过程中估计的精细分割图改进估计的分割图,类似的技术也被应用于边缘检测中,例如整体边缘检测。
通过将几个(通常是两个)strided 卷积和相关卷积替换为扩张卷积(空洞卷积),将完全卷积网络扩展为扩张版本,从而得到中分辨率表示。通过针对多尺度分割对象的特征金字塔将这些表示进一步扩展为多尺度上下文表示。
Recovering high-resolution representations 恢复高分辨率表示: 利用上采样能够将低分辨率表示逐步恢复为高分辨率表示。上采样子网可以是下采样过程(例如VGGNet)的对称版本,通过跳过一些镜像层的连接来转换pooling indices 池化索引(做最大池化时,Segnet会记录最大像素的index,最大像素值的位置区域,叫做pooling indices),例如 SegNet 和 DeconvNet ,或者复制特征图,例如U-Net 和 Hourglass,encoder-decoder 等。U-Net 的一个扩展:全分辨率残差网络 full-resolution residual network 引入一个额外的全分辨率流,该流以全图像分辨率传输信息,以替换 skip 连接,下采样和上采样子网中的每个单元从全分辨率流中接收信息,并向全分辨率流发送信息。
对称的上采样过程也被广泛研究。RefineNet 改进了上采样表示和从下采样过程复制的相同分辨率表示的组合。其他工作包括:轻上采样过程,可能在 backbone 中使用扩张卷积;轻下采样和重上采样过程,复合器网络;使用更多或更复杂的卷积单元改进 skip 连接,并将信息从低分辨率 skip 连接发送到高分辨率 skip 连接,或在它们之间交换信息;研究上采样过程的细节;组合多尺度金字塔表示法;将多个 Deconvnet/Unet/Hourglass 与密集连接堆叠在一起;
Maintaining high-resolution representations 保持高分辨率表示: 我们的工作与一些可以生成高分辨率表示的工作密切相关,例如 convolutional neural fabrics,interlinked CNNs ,GridNet 和 multi-scale DenseNet。
convolutional neural fabrics 和 interlinked CNNs 这两个早期工作在何时启动低分辨率并行流、如何以及在何处跨并行流交换信息方面缺乏详细的设计,并且没有用 batch normalization 和残差连接,因此性能不尽人意。GridNet 类似于多个 U-Net 的组合,包括两个对称信息交换阶段:第一阶段仅将信息从高分辨率传递到低分辨率,第二阶段仅将信息从低分辨率传递到高分辨率,这限制了他的分割质量。multi-scale DenseNet 没有从低分辨率表示中接收到任何信息,因此无法学习强高分辨率表示。
Multi-scale fusion 多尺度融合: 简单的多尺度融合方法是将多分辨率图像分别送入多个网络,并聚合输出特征图。Hourglass、UNet 和SegNet通过skip 连接,将 high-to-low 下采样过程中的低级特征逐渐组合为 low-to-high 上采样过程中相同分辨率的高级特征。PSPNet 和 DeepLabV2/3融合了金字塔池化模块和空洞空间金字塔池化(ASPP)获得的金字塔特征。我们的多尺度(分辨率)融合模块类似于这两个池化模块,区别在于:(1) 我们的融合输出四种分辨率表示,而不是一种分辨率表示;(2)受深度融合启发,我们的融合模块被重复多次。
our approach 我们的方法: 我们的网络并行连接 high-to-low 卷积流,它在整个过程中保持高分辨率表示,并通过多次融合多分辨率流中的表示,生成可靠的具有很强位置敏感性的高分辨率表示。
这篇论文是我们之前论文的一个非常实质性的扩展。与之前的论文相比,主要的技术创新有三个方面:(1)将之前论文中提出的网络:HRNetV1扩展到两个版本:HRNetV2 和 HRNetV2p,这两个版本探索了所有四种分辨率表示。(2) 在多分辨率融合和常规卷积之间建立了联系,这为探索 HRNetV2 和 HRNetV2p 中所有四种分辨率表示的必要性提供了证据。(3)展示了 HRNetV2、HRNetV2p 较 HRNetV1 的优越性,并在语义分割和目标检测等视觉问题中介绍了 HRNetV2 和 HRNetV2p 的应用。
3 HIGH-RESOLUTION NETWORKS HRNet
将图片输入到一个由 2 个 stride=2 的 3×3 卷积组成的 stem 中,将分辨率降至 1 4 \frac{1}{4} 41,紧接着是输出相同分辨率 ( 1 4 \frac{1}{4} 41) 表示的 main body。main body 部分如图2所示,由以下几个部分组成:Parallel Multi-Resolution Convolutions 并行多分辨率卷积、repeated multi-resolution fusions 重复多分辨率融合,以及 representation head 表示头(如图4所示)。
3.1 Parallel Multi-Resolution Convolutions 并行多分辨率卷积
我们以一个高分辨率卷积流作为第一 stage 开始,逐个添加 high-to-low 分辨率流形成新的 stage,并行连接多分辨率流。因此,后一阶段并行流的分辨率由前一阶段的分辨率和一个较低的分辨率组成。
图2所示的网络结构包含4个并行流,其逻辑如下所示:

N
s
r
N_{sr}
Nsr 是第s stage中的子流,r 是分辨率索引。第一个流的分辨率索引 r=1。索引 r 的分辨率是第一个流分辨率的
1
2
r
−
1
\frac{1}{2^{r-1}}
2r−11。
3.2 Repeated Multi-Resolution Fusions 重复多分辨率融合
融合模块的目标是在多分辨率表示中交换信息。融合模块会重复多次(例如,每4个残差单元重复一次)。
如图 3 所示是一个融合 3-分辨率表示的示例,根据示例,融合2个分辨率的表示和4个分辨率的表示可以很容易被推导出。输入由三种形式组成:
{
R
r
i
,
r
=
1
,
2
,
3
}
\{R^i_r, r= 1,2,3\}
{Rri,r=1,2,3},r 是分辨率指数,相应的输出表示为:
{
R
r
o
,
r
=
1
,
2
,
3
}
\{R^o_r, r= 1,2,3\}
{Rro,r=1,2,3}。每个输出是转换三个输入的总和:
R
r
o
=
f
1
r
(
R
1
i
)
+
f
2
r
(
R
2
i
)
+
f
3
r
(
R
3
i
)
R^o_r=f_{1r}(R^i_1)+f_{2r}(R^i_2)+f_{3r}(R^i_3)
Rro=f1r(R1i)+f2r(R2i)+f3r(R3i)。跨 stage (从stage 3 到 stage 4)的融合模块有一个额外的输出:
R
4
o
=
f
14
(
R
1
i
)
+
f
24
(
R
2
i
)
+
f
34
(
R
3
i
)
R^o_4=f_{14}(R^i_1)+f_{24}(R^i_2)+f_{34}(R^i_3)
R4o=f14(R1i)+f24(R2i)+f34(R3i)。
转换函数
f
x
r
(
⋅
)
f_{xr}(·)
fxr(⋅) 的选择取决于输入分辨率指数 x 和输出分辨率指数 r。如果 x=r,
f
x
r
(
R
)
=
R
f_{xr}(R)=R
fxr(R)=R,如果 x<r,
f
x
r
(
⋅
)
f_{xr}(·)
fxr(⋅) 通过 (x-r) 个 stride=2 的 3×3 卷积对输入表示 R 进行下采样。例如,一个 stride=2 的 3×3 卷积能够进行2倍下采样,两个 stride=2 的 3×3 卷积能够进行4倍下采样。如果 x<r,
f
x
r
(
⋅
)
f_{xr}(·)
fxr(⋅) 通过双线性插值对输入表示 R 进行上采样,之后通过 1×1 卷积对其通道数。图3描述了该机制:

图3. 从左到右,融合模块如何聚合高、中、低分辨率的信息。 右图例: strided3×3= stride=2 的 3×3 卷积,up samp.1×1=双线性插值上采样+1×1卷积
3.3 Representation Head 表示头
图 4 阐述了 3 种表示头,分别是: HRNetV1,HRNetV2 和 HRNetV1p。
HRNetV1:如图 4(a) 所示,输出仅来自高分辨率流的表示,忽略其他三种表示。
HRNetV2:如图 4(b) 所示,通过双线性上采样 rescale 低分辨率表示,不将通道数更改为高分辨率的通道数,并串联这四种表示,然后进行一个1×1卷积来混合这四种表示。
HRNetV2p:如图 4(c) 所示,通过将 HRNetV2 的高分辨率表示输出降采样到多个级别来构造多级表示。

图4. (a) HRNetV1:仅从高分辨率卷积流输出表示。(b) HRNetV2:连接来自所有分辨率的(上采样)表示(为清晰起见,未显示后续的1×1卷积)。(c) HRNetV2p:根据 HRNetV2的表示形成一个特征金字塔。
每个子图底部的四个分辨率表示从图2中的网络输出,灰色框表示如何从输入的四个分辨率表示中获得输出表示。
在本文中,我们将 HRNetV1应用于人体姿势估计、HRNetV2应用于语义分割,HRNetV2p 应用于目标检测。
3.4 Instantiation 实例化
main body 包含四个 stage ,即四个并行卷积流,分辨率是:1/4、1/8、1/16和1/32。第一 stage 包含4个残差单元,每个残差单元由一个 width=64 的bottleneck + 一个将特征图 width(通道)变为 C 的3×3卷积形成。第2,第3,第4 stage 分别包含 1,4,3 个模块化块 modularized blocks。模块化块中的 多分辨率并行卷积 中的每个分支包含4个残差单元。每个残差单元对于每个分辨率,包含两个3×3卷积,每个卷积之后是 batch normalization 和非线性激活ReLU。这4个分辨率卷积的通道数分别是 C,2C,4C ,8C。图2是一个示例网络。
图2. HRNet 的一个示例。 该示例不包括 stem (两个 stride=2 的 3×3 卷积),仅对main body进行了说明。该网络有四个stage。第一 stage 由高分辨率卷积组成。第二、第三、第四 stage 重复两分辨率、三分辨率、四分辨率 blocks。
3.5 Analysis 分析
该小节对模块化块 modularized blocks 进行分析。模块化块分为两部分:多分辨率并行卷积(图5(a))和多分辨率融合(图5(b))。多分辨率并行卷积类似于组卷积,将输入通道划分为几个通道子集,并分别在不同的空间分辨率上对每个子集执行常规卷积,只不过在组卷积中,分辨率是相同的。这种联系意味着多分辨率并行卷积有着组卷积的一些优势。
如图5(c) 所示,多分辨率融合单元类似于规则卷积的多分支全连接形式。规则卷积可以分为多个小卷积(组卷积论文阐述的)。输入通道被划分为几个子集,输出通道也被划分为几个子集,输入和输出通道子集以全连接的方式连接,每个连接都是一个规则卷积。每个输出通道子集是对每个输入通道子集进行卷积后的输出的总和。两者的不同之处在于多分辨率融合单元需要处理分辨率的变化。多分辨率融合和规则卷积之间的联系为探索 HRNetV2 和 HRNetV2p 中的所有 4-resolution 表示提供了证据。

图5. (a) 多分辨率并行卷积. (b)多分辨率融合.(c) 常规卷积(左)等价于全连接的多分支卷积(右)。
4 HUMAN POSE ESTIMATION 人体姿态估计
人体姿态估计,又称关键点检测,旨在从 size 为 W×H×3 的图像 I 中检测关键点或部位(如肘部、手腕等)的位置。我们遵循 sota 框架,将此问题转化为估计 K 个size 为
W
4
×
H
4
,
{
H
1
,
H
2
,
…
,
H
k
}
\frac{W}{4}×\frac{H}{4}, \{H_1, H_2, …, H_k\}
4W×4H,{H1,H2,…,Hk} 的热图,每张热图
H
k
H_k
Hk 表示第 k 个关键点的位置置信度。
从 HRNetV1 高分辨率表示输出上回归热图。实验结果表明 HRNetv1和HRNetV2 的性能几乎相同,因此选择计算复杂度稍低的 HRNetv1。均方误差用于计算预测热图和GT热图的 loss。应用2D高斯分布生成GT热图,以每个关键点的 GT 位置为中心,标准偏差为2像素。如图6所示为人体姿态估计的定性结果。

图6. 定性COCO人体姿态估计结果。 是对具有不同人体大小、不同姿势或杂波背景的代表性图像的结果。
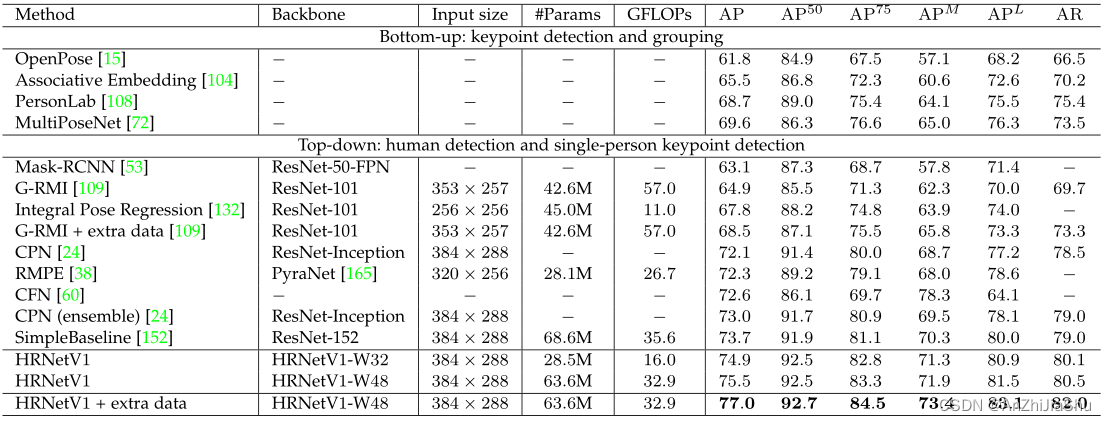
表1 COCO val 上的比较结果。 输入尺寸=256×192时,采用小模型:HRNetV1-W32,从零开始训练,比之前的 sota 方法性能更好;输入尺寸=384×288 时,使用小模型的 HRNetV1-W32 比使用大模型的 SimpleBaseline 获得更高的 AP,尤其是
A
P
75
AP^{75}
AP75的提升比
A
P
50
AP^{50}
AP50更显著。Pretrain=在 ImageNet 上预训练 backbone。OHKM=在线硬关键点挖掘;#param 和 FLOPs是在姿态估计网络上计算参数量和计算量,不包括用于人体检测和关键点分组的参数量和计算量。

5 SEMANTIC SEGMENTATION 语义分割
语义分割是为每个像素分配一个类别标签。图7给出了我们方法的一些示例结果。将输入图像输入到 HRNetV2(图4(b))中,然后将每个位置的结果 15C-维表示传递给具有 softmax 损失的线性分类器,以预测分割图。通过双线性上采样将分割图上采样(4次)到输入大小,用于训练和测试。在PASCAL-Context 、Cityscapes以及LIP数据集上进行实验,采用 mIoU 作为评价指标。

图7. Cityspace(左二)、PASCAL-Context(中二)和LIP(右二)的定性分割示例。
表3. Cityscapes val上的语义分割结果(单尺度且无翻转)。根据输入尺寸1024×2048计算GFLOPs。具有最小GFLOPs的小型模型 HRNetV2-W40的性能优于两个代表性的上下文方法(Deeplab 和 PSPNet)。结合最近开发的对象上下文表示方案(OCR)我们的方法得到了进一步的改进。D-ResNet-101=Dilated-ResNet-101。

表4. Cityscapes test上的语义分割结果。 使用 HRNetV2-W48 进行比较,HRNetV2-W48 的参数复杂度和计算复杂度与基于Dilated ResNet-101 的网络相当。我们的结果在四个评估指标方面都是优秀的。与OCR的结合能进一步改进我们的方法。D-ResNet-101=Dilated-ResNet-101。

表5. PASCAL-Context的语义分割结果。 在59个类和60个类上评估这些方法。我们的方法在60个类中表现最好,在59个类中表现比 APCN差,APCN 开发了一种强大的上下文方法。我们的方法与OCR相结合,获得了显著的提升,并且性能最好。D-ResNet-101=Dilated-ResNet-101。

表6. LIP 语义分割结果。我们的方法不利用任何额外的信息,例如姿态或边缘。我们的方法总体性能最好,结合OCR方案进一步提高了分割质量。D-ResNet-101=Dilated-ResNet-101。

6 COCO 目标检测

表7. GFLOPs 和 #Param 用于COCO目标检测。 The numbers are obtained with the input size 800×1200 and if applicable 512 proposals fed into R-CNN except the numbers for CenterNet are obtained with the input size 511×511. R-x= ResNet-x-FPN, X-101= ResNeXt-101-64×4d, H-x= HRNetV2p-Wx, and HG-52= Hourglass-52

表8. COCOval 上Faster R-CNN 和 Cascade R-CNN目标检测结果. LS = learning schedule. 1×=12e, 2×=24e. 我们的方法比ResNet和ResNeXt性能更好。我们的方法在 LS=2× 比 LS=1× 以及小对象(
A
P
S
AP_S
APS)比中对象(
A
P
M
AP_M
APM)和大对象(
A
P
L
AP_L
APL)改进的更显著。

表9. FCOS 和 CenterNet框架上的COCO val 的目标检测结果。 对于相似的参数和计算复杂度,我们的方法优于ResNet和 Hourglass。我们的HRNetV2p-W64 性能比 Hourglass-104稍差,原因是 Hourglass-104比HRNetV2p-W64重得多。

表10. Mask R-CNN及其扩展框架在COCO val上的目标检测结果。我们方法的总体性能优于ResNet,除了 HRNetV2p-W18 有时比 ResNet-50 性能差。与检测(bbox)类似,小物体(
A
P
s
AP_s
APs)在 mask 方面的改善也比中物体(
A
P
M
AP_M
APM)和大物体(
A
P
L
AP_L
APL)更显著。结果是通过MMDetection得到的

表11. 在固定BN参数且无多尺度训练和测试的情况下,在 COCOtest-dev上与 sota 单模型目标检测器的比较结果。∗表示结果来自原始论文。表7给出了模型的GFLOPs和#Param。实验结果与COCO val上的结果相似,表明在 sota 对象检测和实例分割框架下,HRNet 的性能优于 ResNet 和ResNeXt。

7 ABLATIONSTUDY 消融实验
我们在两项任务中对 HRNet中的组件进行了消融研究:COCO validation 上的人体姿态估计和 Cityscapes validation 上的语义分割。我们主要使用HRNetV1-W32 进行人体姿态估计,HRNetV2-W48进行语义分割。姿态估计的所有结果都是在256×192的输入范围内得到的。我们还提供了 HRNetV1和HRNetV2的比较结果。

图9. 人体姿态估计表示分辨率的消融实验。1×、2×、4×分别对应于高、中、低分辨率的表示。结果表明,分辨率越高,性能越好。
表12. multi-resolution fusion units 多分辨率融合单元在COCOval 人体姿态估计(AP)和Cityscapes val 语义分割(mIoU)的消融研究。 Final =表示头部前的最终融合,Across = stage 之间的中间融合,Within = stage内的中间融合。实验结果表明这三种融合对人体姿态估计和语义分割都是有益的。


图10. HRNetV1 和 HRNetV2 的比较结果。 (a) HRNetV1及其变体HRNetV1h 和 HRNetV2(单尺度且无翻转)在 Cityscapes val 和 PASCAL-Context 上的分割对比。(b) HRNetv1及其变体HRNetV1h和HRNetV2p 在COCO val 上的目标检测比较(LS=学习计划)。从图中可以看出:HRNetV2在语义分割和目标检测方面都优于 HRNetV1。
8 CONCLUSIONS 结论
在本文中,我们提出了一种用于视觉识别问题的高分辨率网络 HRNet。HRNet与现有的低分辨率分类网络和高分辨率表示学习网络相比,有三个基本区别:(1) 将高分辨率和低分辨率卷积并联,而非串联;(2) 在整个过程中保持高分辨率,而不是从低分辨率恢复高分辨率;(3) 反复融合多分辨率表示,呈现丰富的高分辨率表示,具有很强的位置敏感性。
在广泛的视觉识别问题上的优越结果表明 HRNet 是计算机视觉问题的一个更强大的 backbone。我们的研究也鼓励直接为特定的视觉问题设计网络体系结构,而非扩展、修正或修复从低分辨率网络(如ResNet或VGGNet)学习到的表示。
Discussions. 现在可能有一个误解:分辨率越高,HRNet的内存成本越大。实际上,HRNet 在人体姿态估计、语义分割和目标检测这三个应用中的内存开销与最新的 sota 技术相当,只是目标检测中的训练内存开销稍大。
此外,我们在 PyTorch1.0 平台上总结了运行时成本对比。HRNet的训练和推理时间成本与之前的 sota 技术相当,除了(1)用于分割的 HRNet 的推理时间更小。(2)用于姿态估计的HRNet训练时间稍长,但在支持静态图形推理的 MXNet 1.5.1 平台上的耗费与SimpleBaseline类似。我们想强调的是,对于语义分割,HRNet 的推理成本明显小于 PSPNet 和 DeepLabv3。表13总结了内存和时间成本对比。
表13. 就 training/inference memory 和 training/inference time 而言,在 PyTorch 1.0 上对于姿势估计、语义分割和目标检测(在 Faster R-CNN框架下)的 Memory 和 time cost 的比较。 我们还报告了在 MXNET1.5.1 上姿势估计的推断时间(in()),MXNET1.5.1 支持静态图推断,HRNet中使用的多分支卷积可以从中受益。
训练的数据是在配备4个 V100GPU 的机器上获得的。在训练过程中,姿势估计、分割和检测的输入大小分别为256×192,512×1024和800×1333,batch size为128、8和8。推断的数据是在单个 V100GPU上获得,输入大小分别为256×192、1024×2048和800×1333。score 是指在COCO val上的姿势估计AP(表1),在 COCO val上的检测AP(表8),以及在CitySpaces上的分割mIoU(表3)。
重点介绍了以下几个观察结果:Memory:HRNet在训练和推理时消耗的内存相似,只是在人体姿势估计训练时消耗较小的内存;Time:HRNet的训练和推理时间成本与之前的 sota 技术水平相当,只是用于分割的 HRNet 的推理时间要小得多。SB-ResNet-152=使用ResNet-152 backbone 的SimpleBaseline。PSPNet和DeepLabV3使用dilated ResNet-101作为backbone(表3)。

未来和后续工作。 我们将研究 HRNet 与其他语义分割和实例分割技术的结合。目前,通过将 HRNet 与对象上下文表示(object-contextual representation OCR)方案(对象上下文的一种变体)相结合,得到的 mIoU 结果如表 3 4 5 6 所示。我们将通过进一步提高表示的分辨率来进行研究,例如,将分辨率提高到1/2,甚至是全分辨率。
HRNet 的应用不仅限于上述我们已完成的工作,而且适用于其他位置敏感视觉应用,例如 facial landmark 检测,超分辨率、光流估计、深度估计等。目前也已经有许多后续工作,例如,图像样式化、修复、图像增强、图像去叠、实时姿态估计和无人机目标检测。
一篇文献中提到,在单模型情况下,稍加修改的HRNet 结合 ASPP,在地图全景分割上取得了 sota 性能。在2019年ICCV的COCO + Mapillary Joint Recognition Challenge Workshop 上,COCO DensePose挑战的获胜者和几乎所有COCO keypoint detection挑战的参与者都采用了HRNet。OpenImage实例分割挑战赛冠军(ICCV 2019)也使用了HRNet。















 875
875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









