







Outline

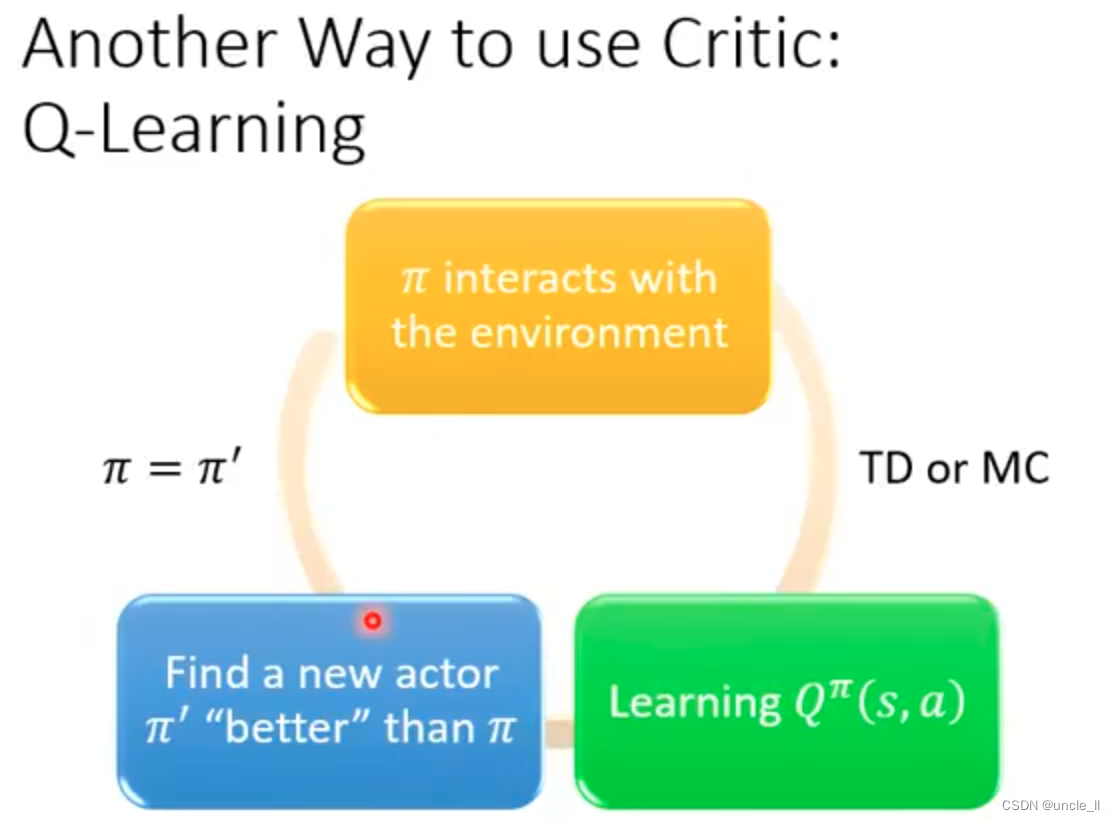
Critic

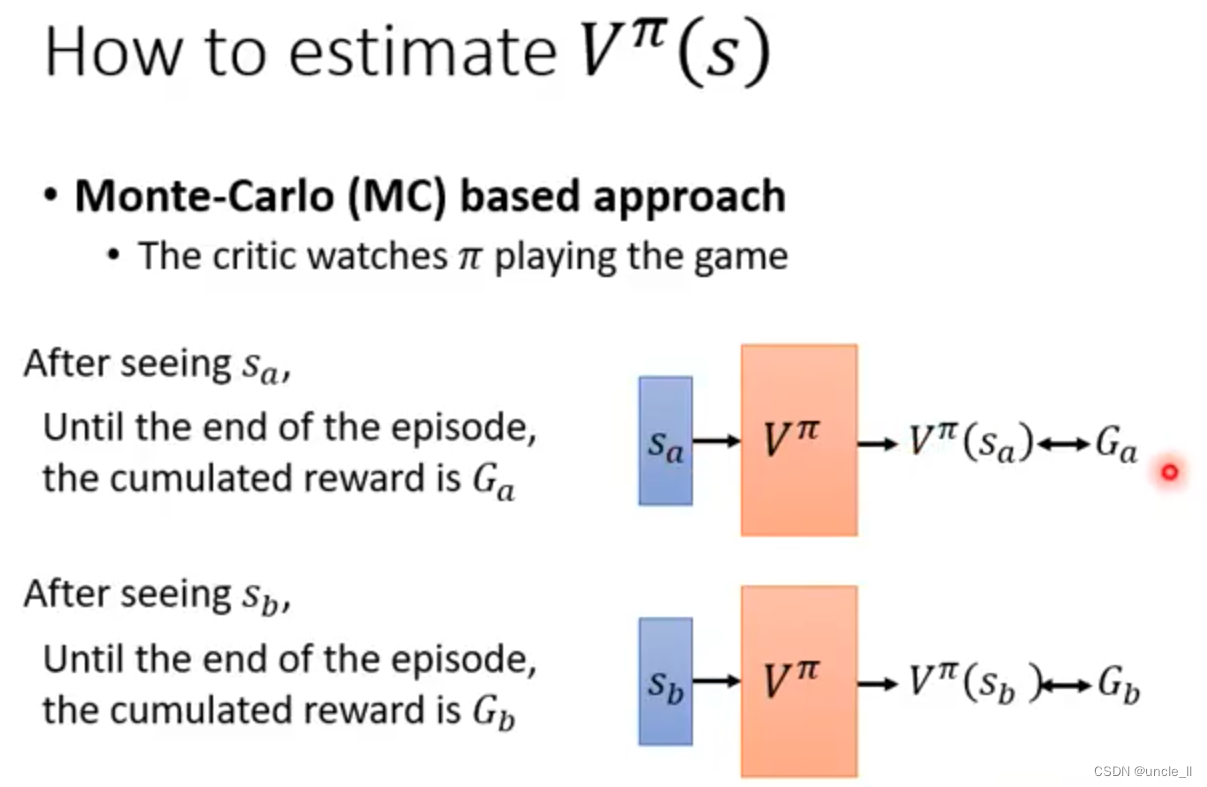
- 从头往后,逐渐累积
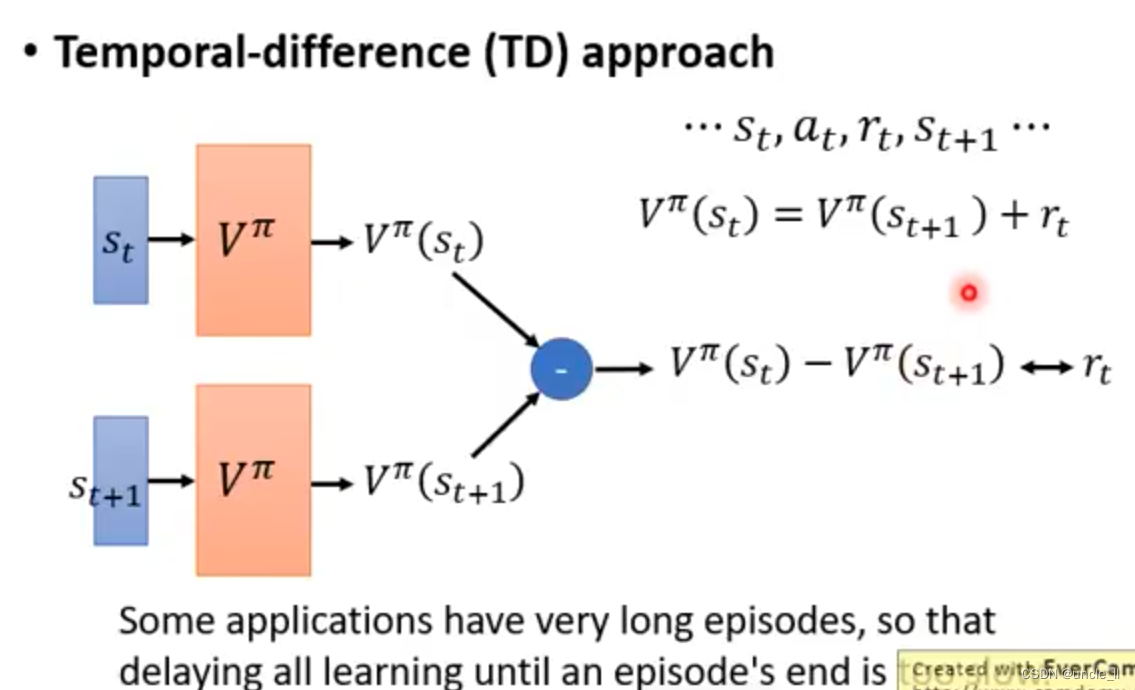
- 新时刻跟前一时刻有关
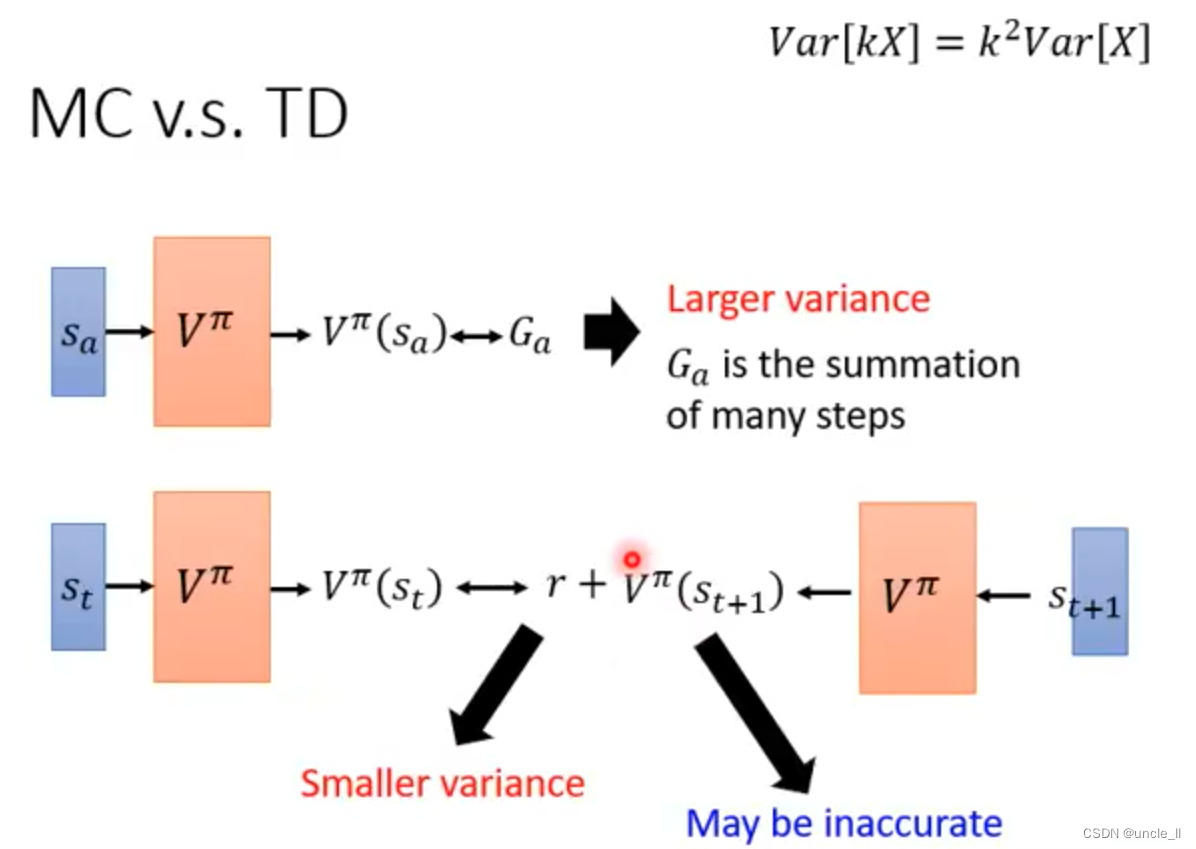

- 不同的方法得到不同的假设,得到不同的结果
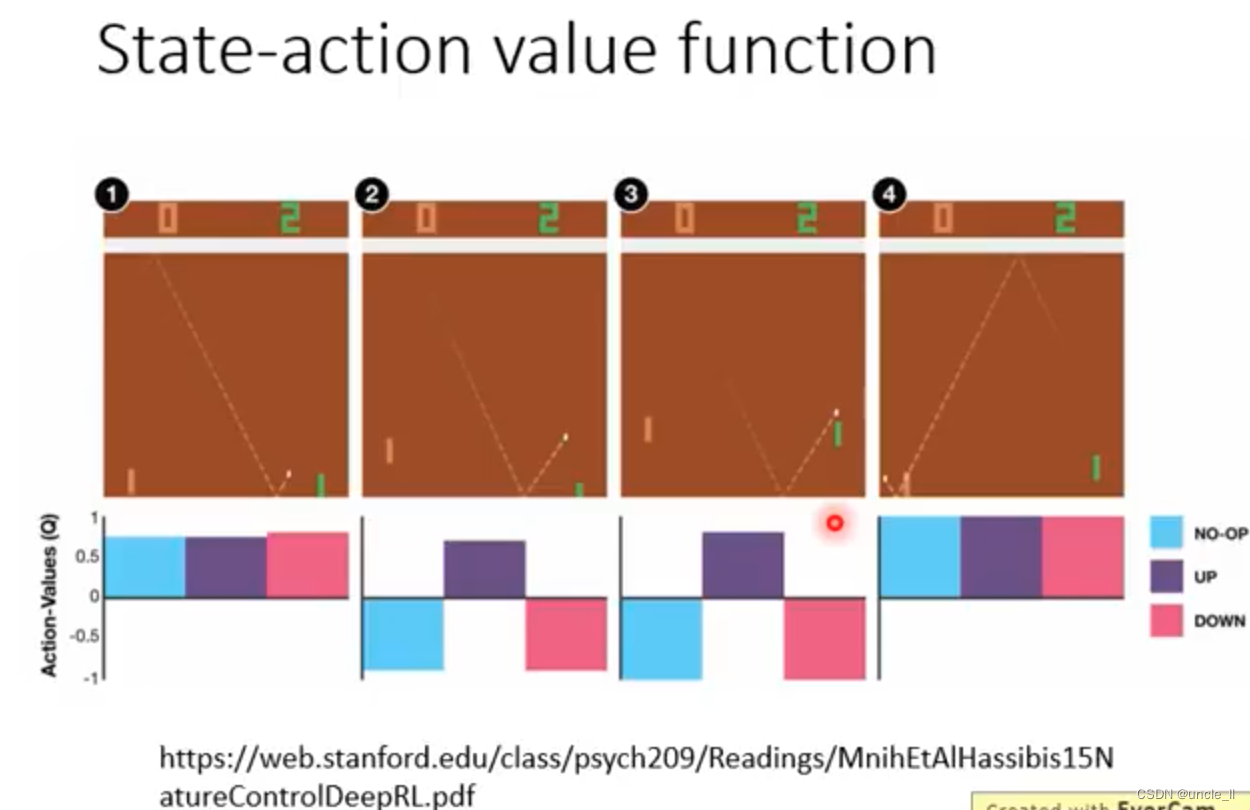
Q-function
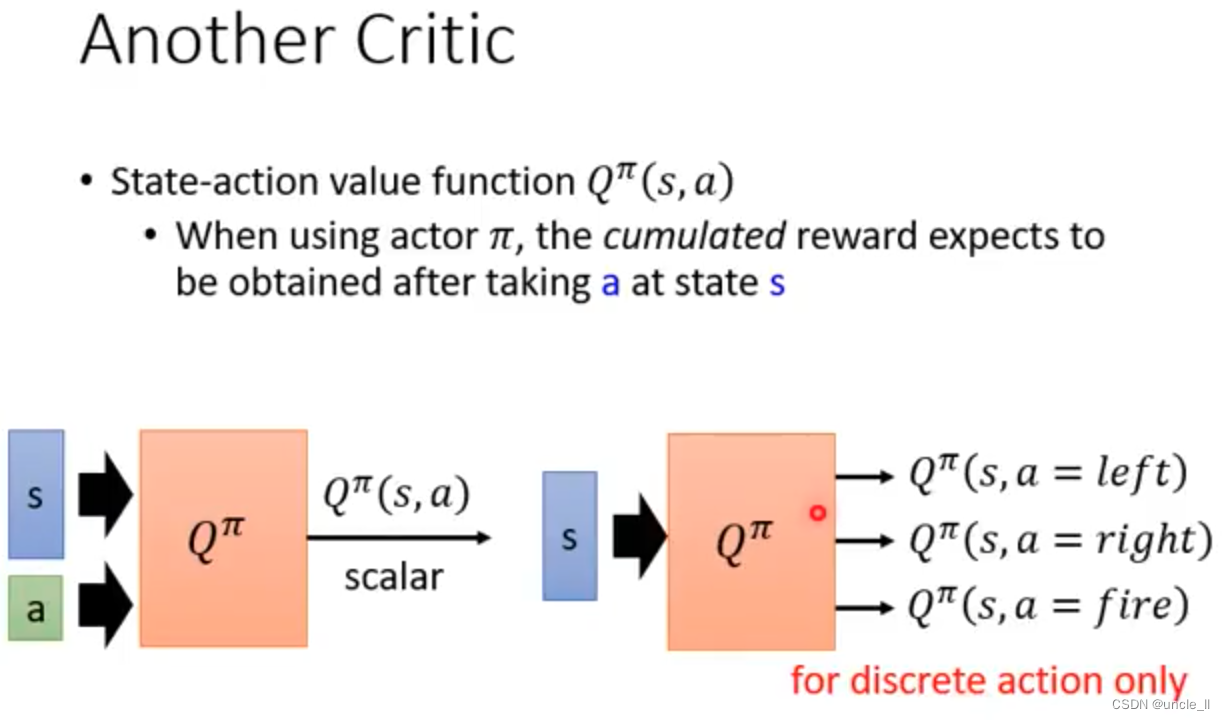
- 在状态s下强制执行a得到对应的奖励

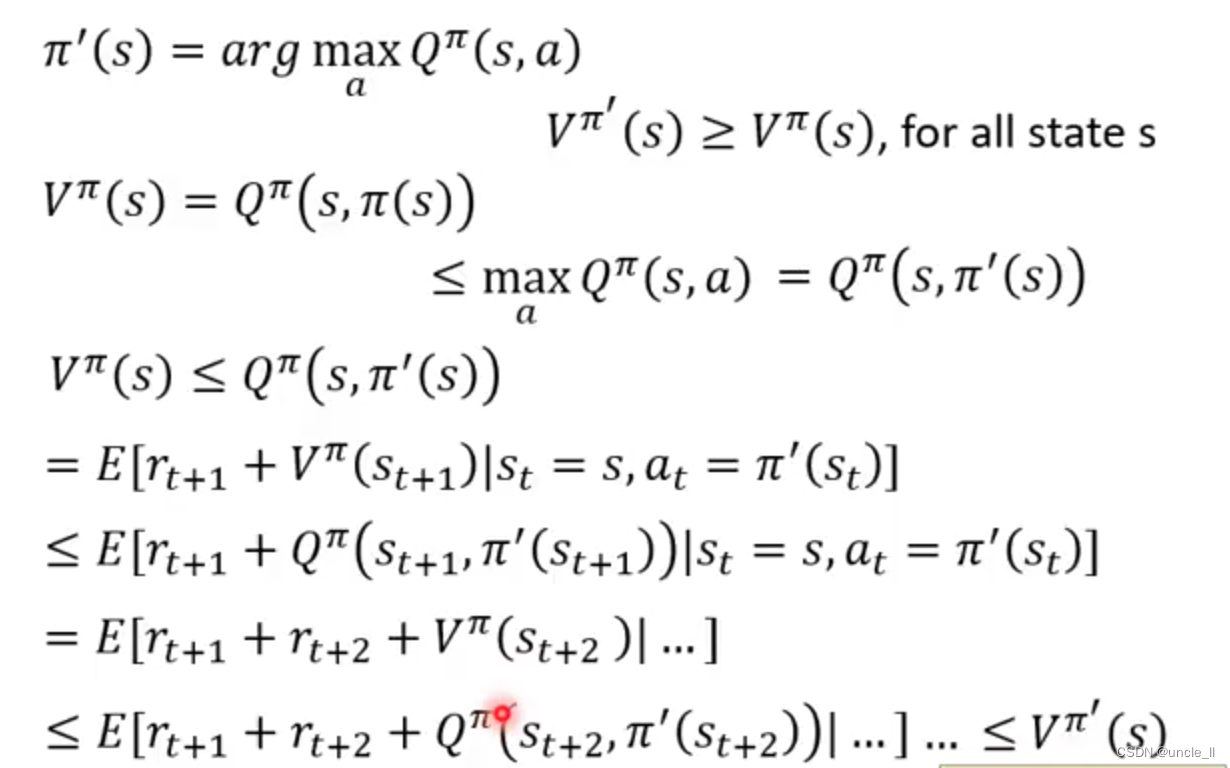
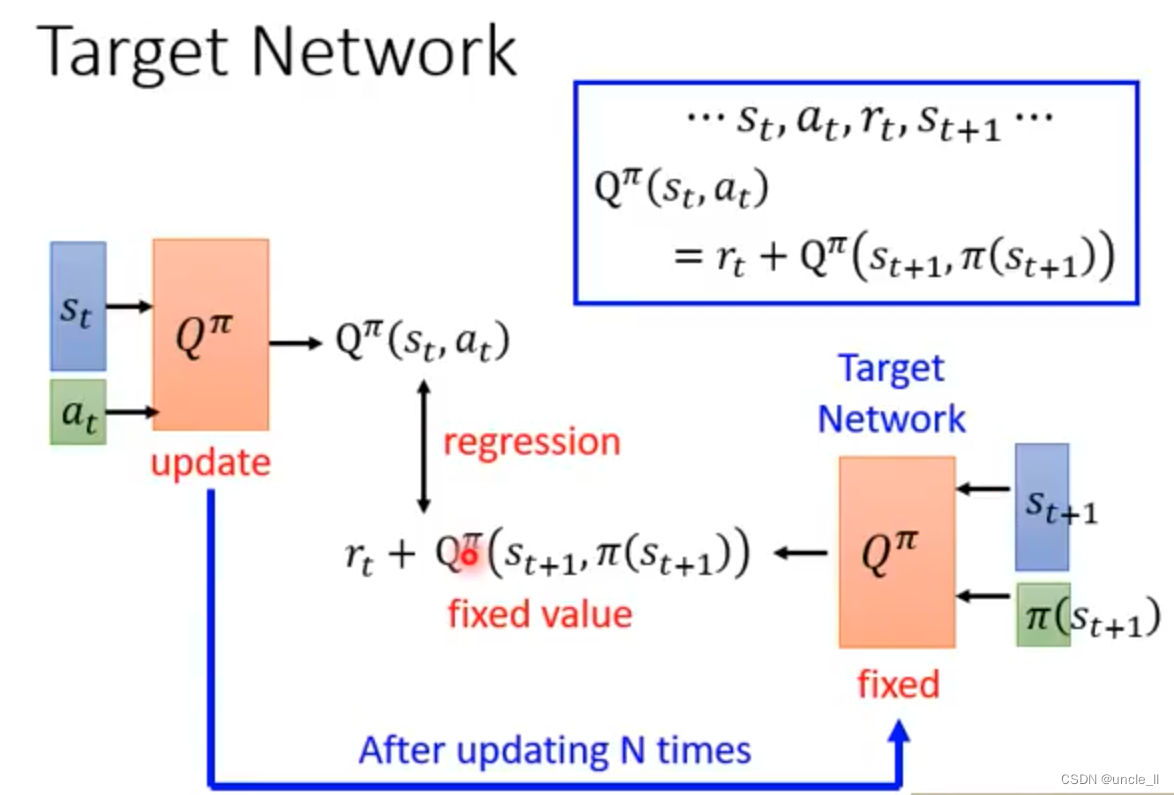
目标网络
-
targe一直在变
-
将其中的一个Q进行固定

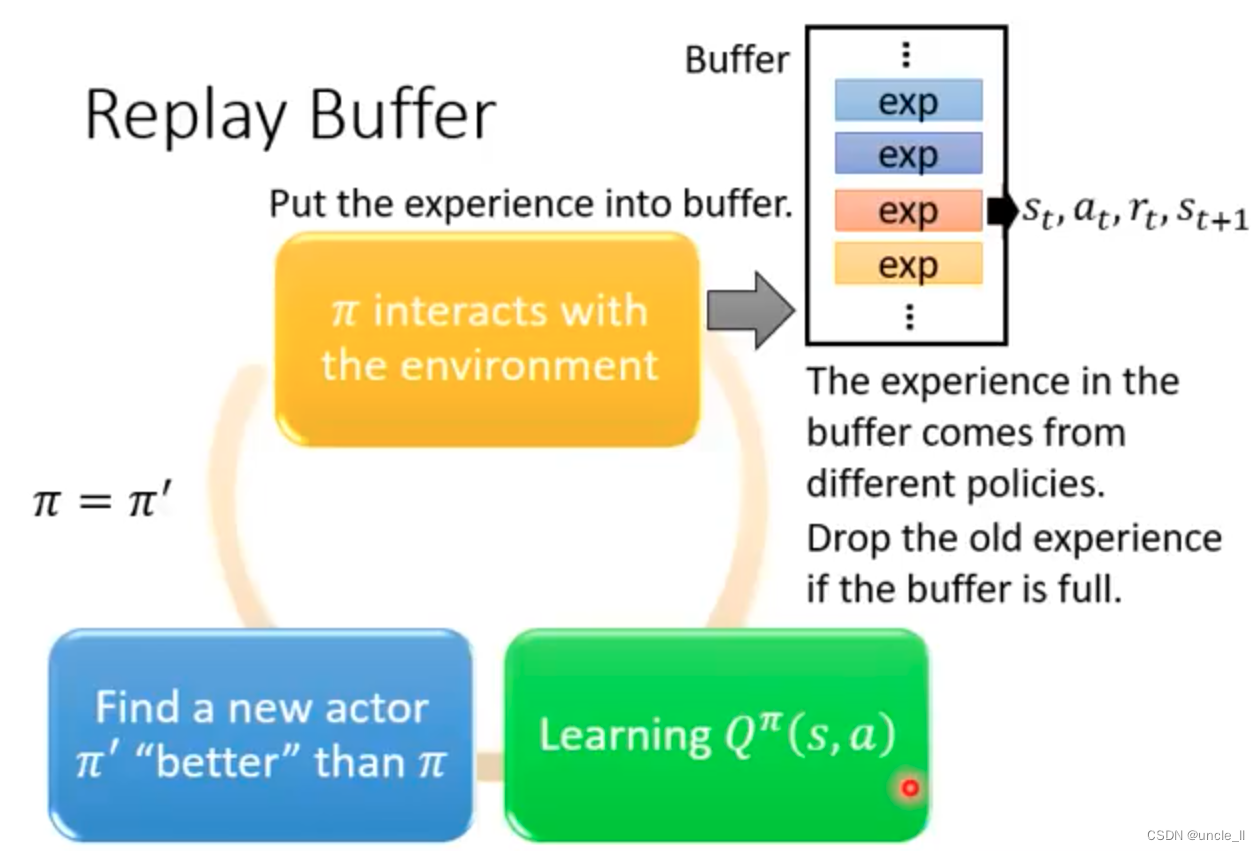
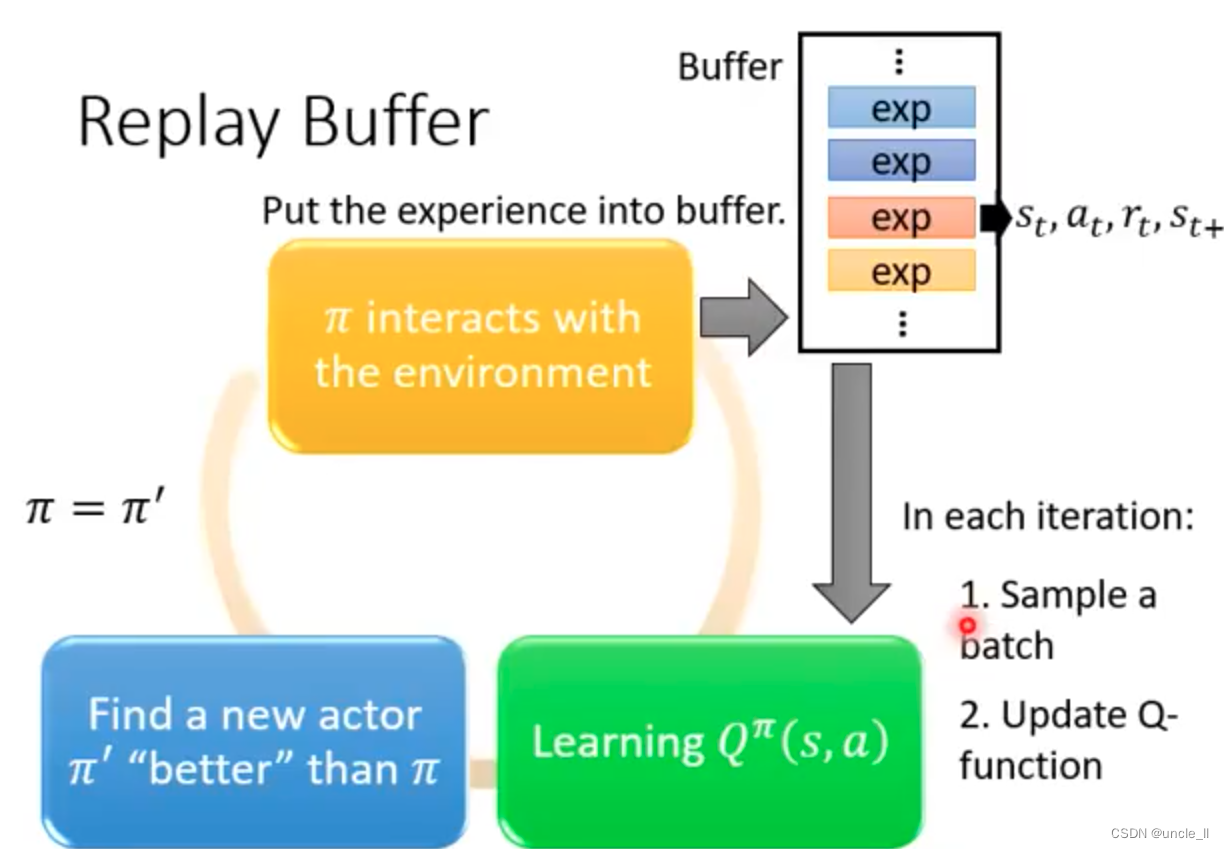
-
sample a batch
-
udpdate Q-function

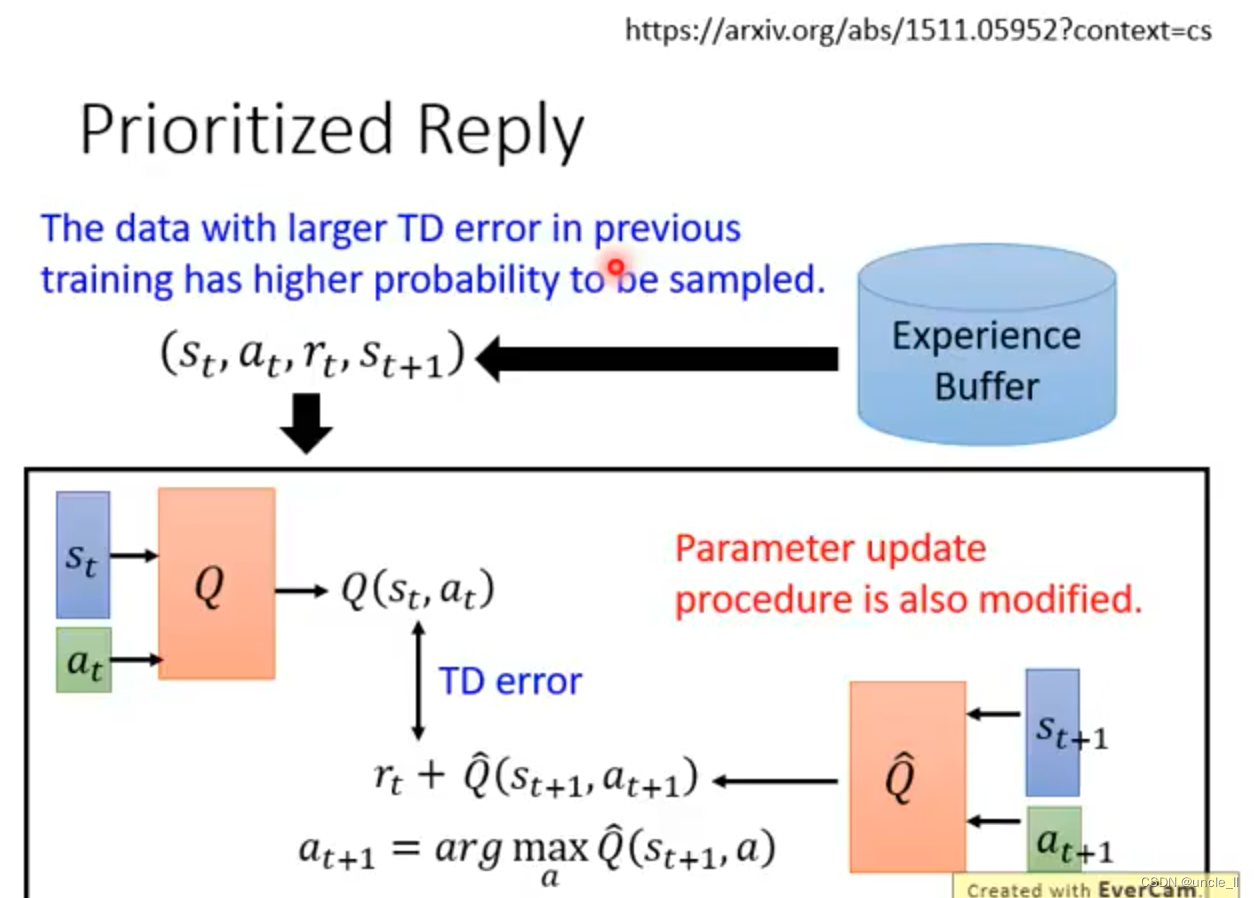
Tips of Q-learning
Double DQN
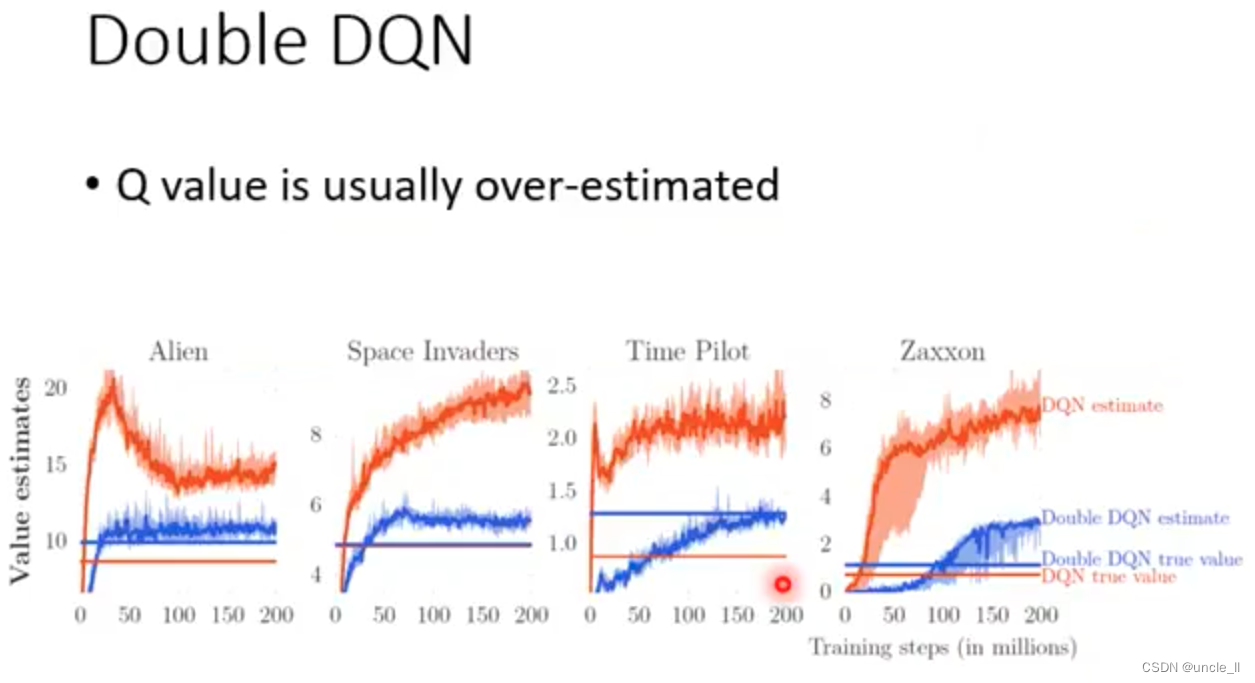
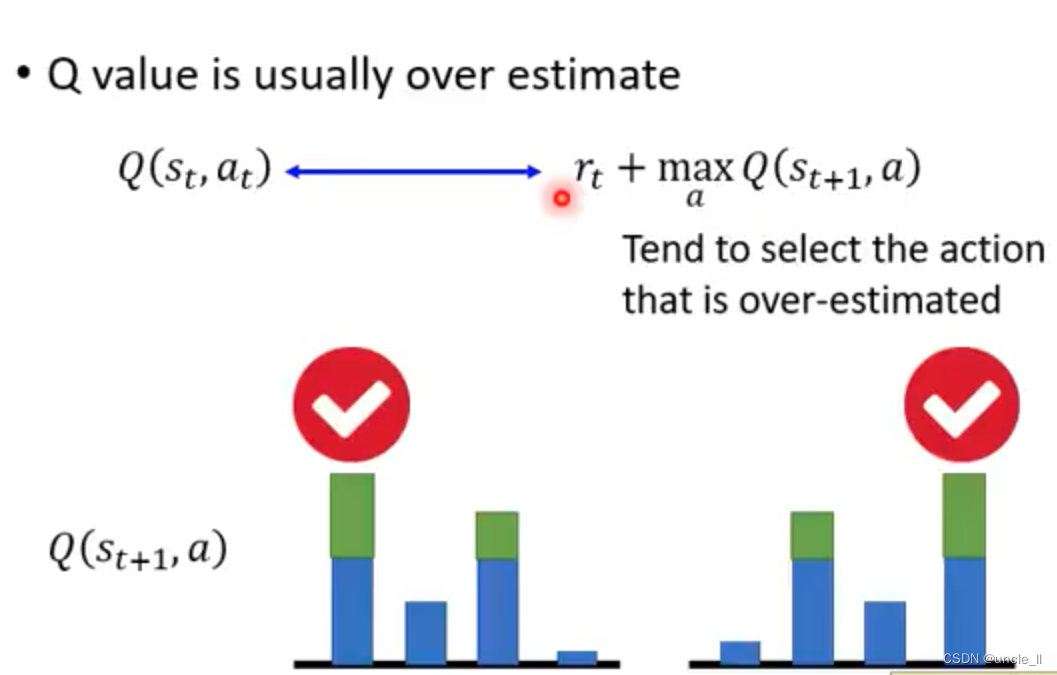
- Q value往往是被高估的

Dueling DQN
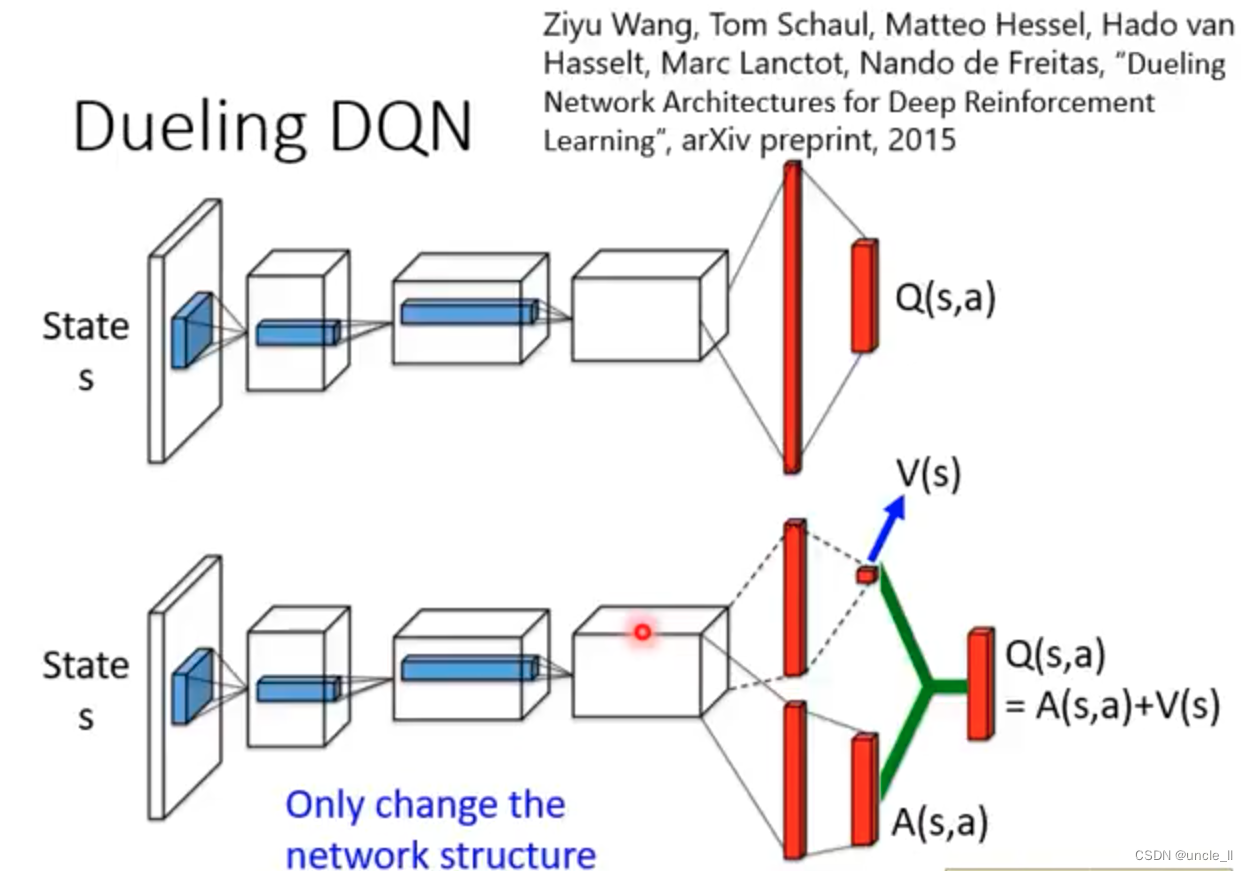
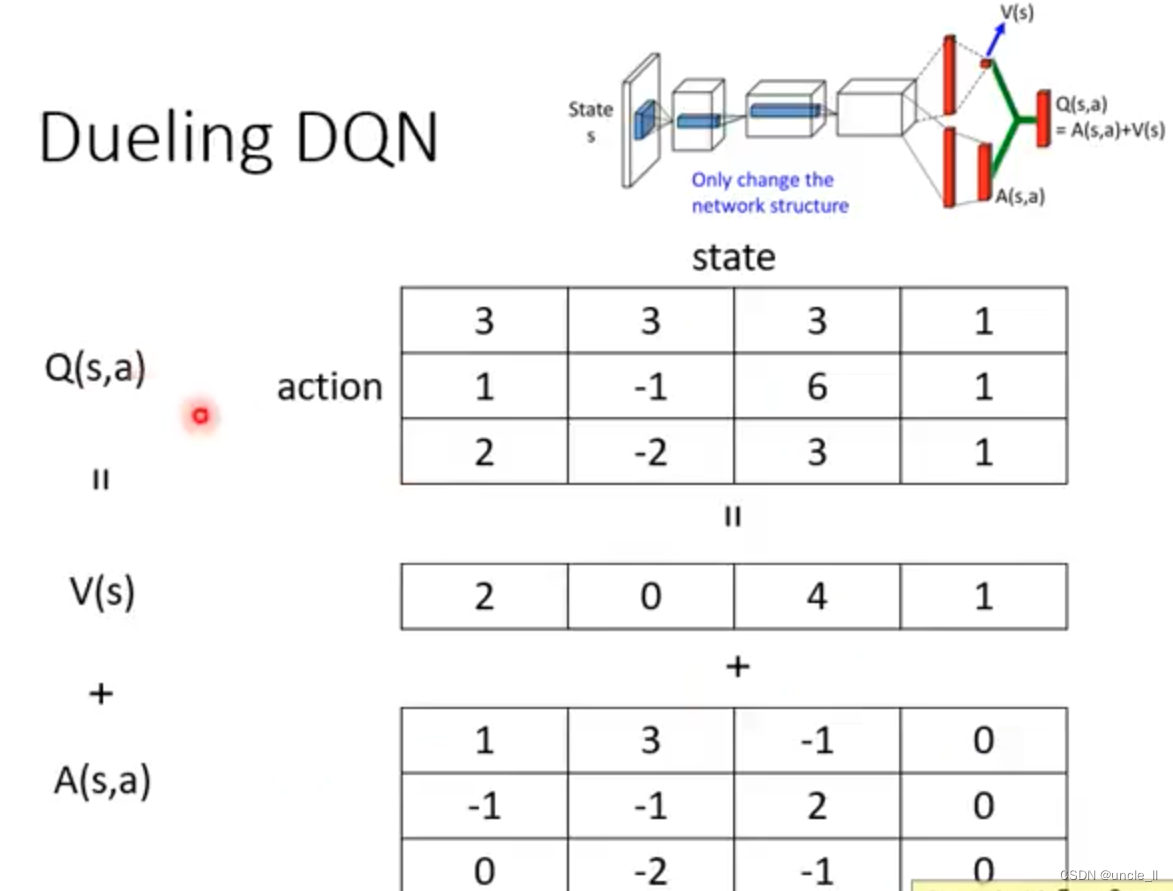

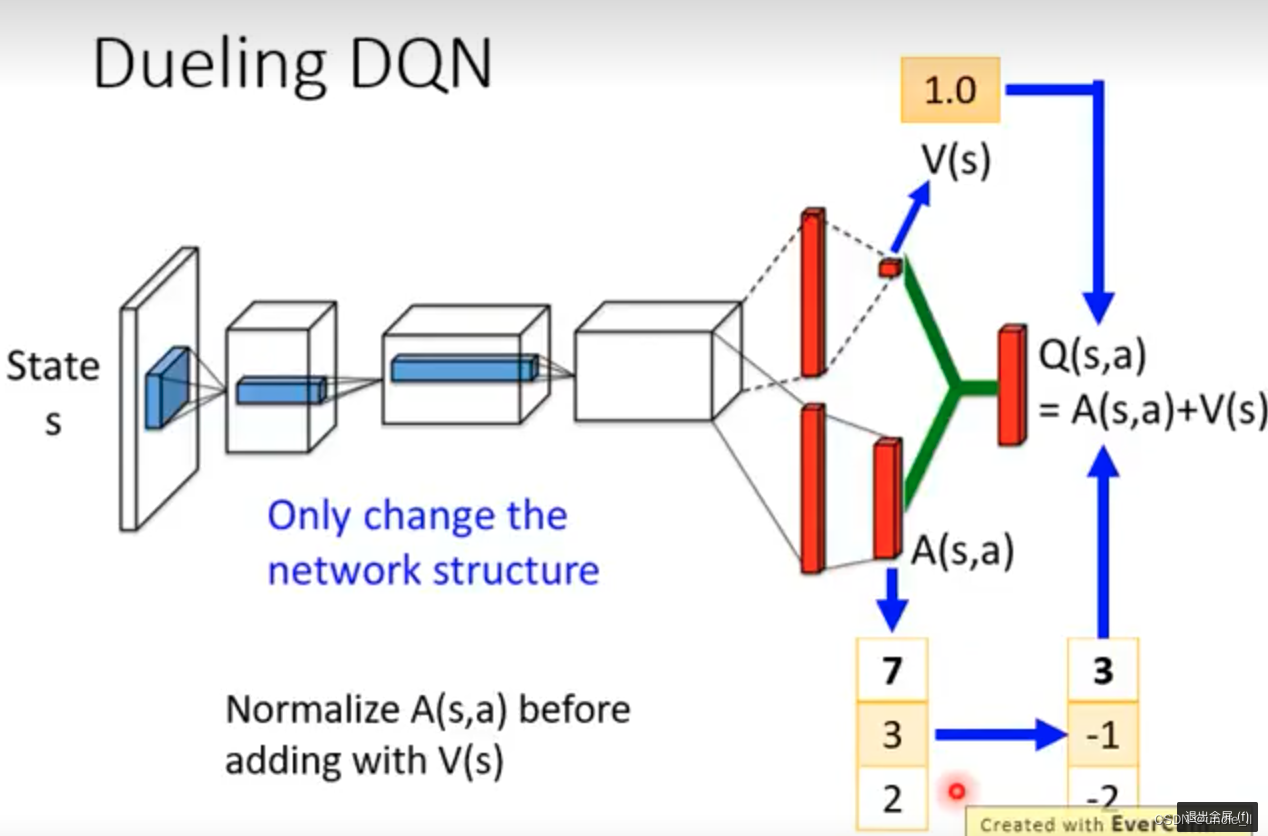
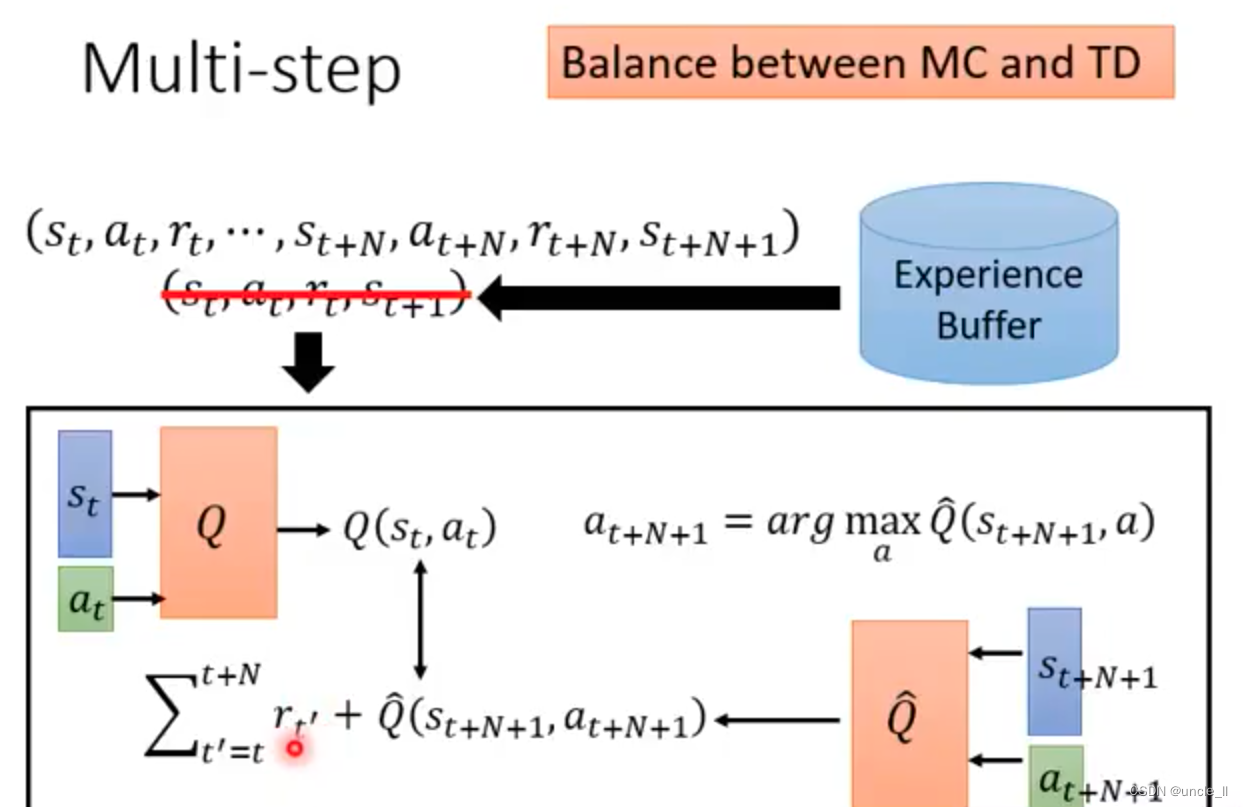
- 调整超参数N

- 加噪音
Distributional Q-funciton
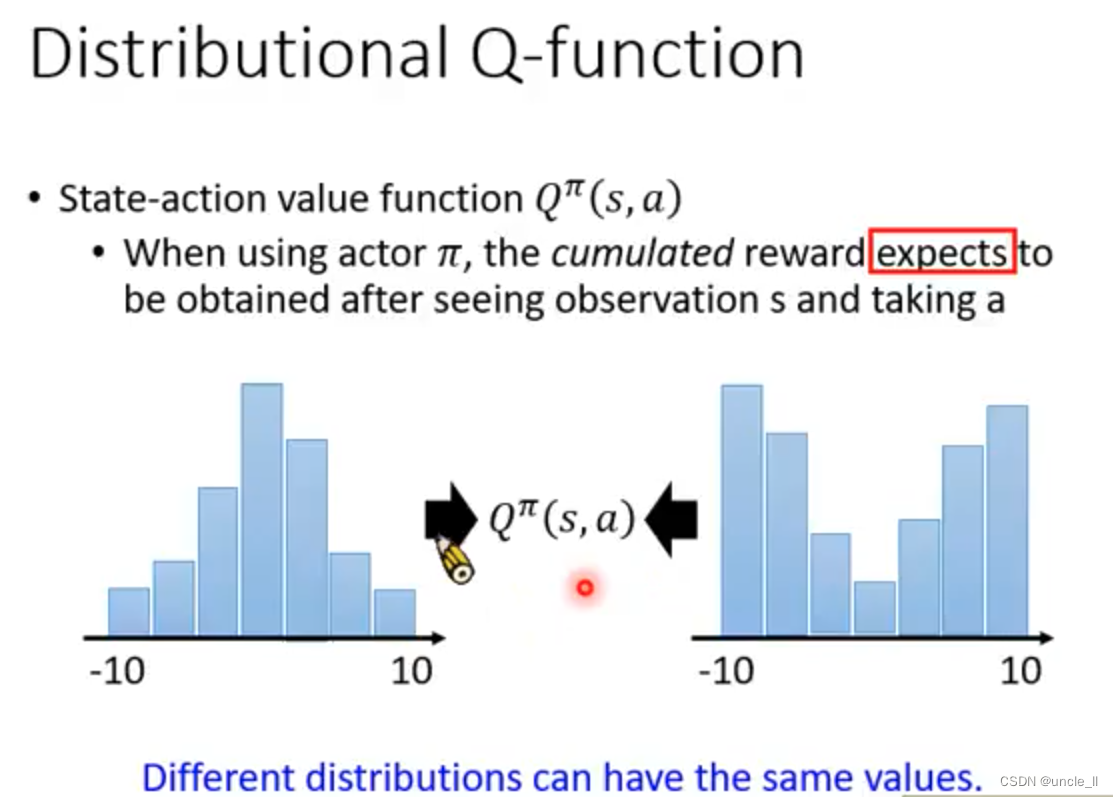
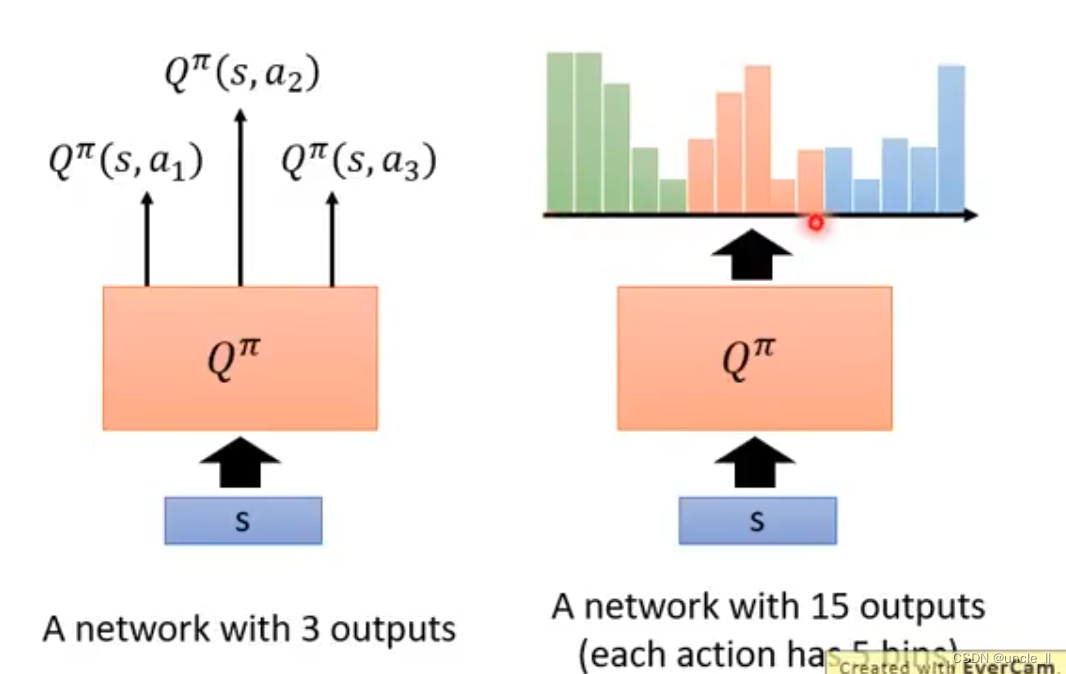
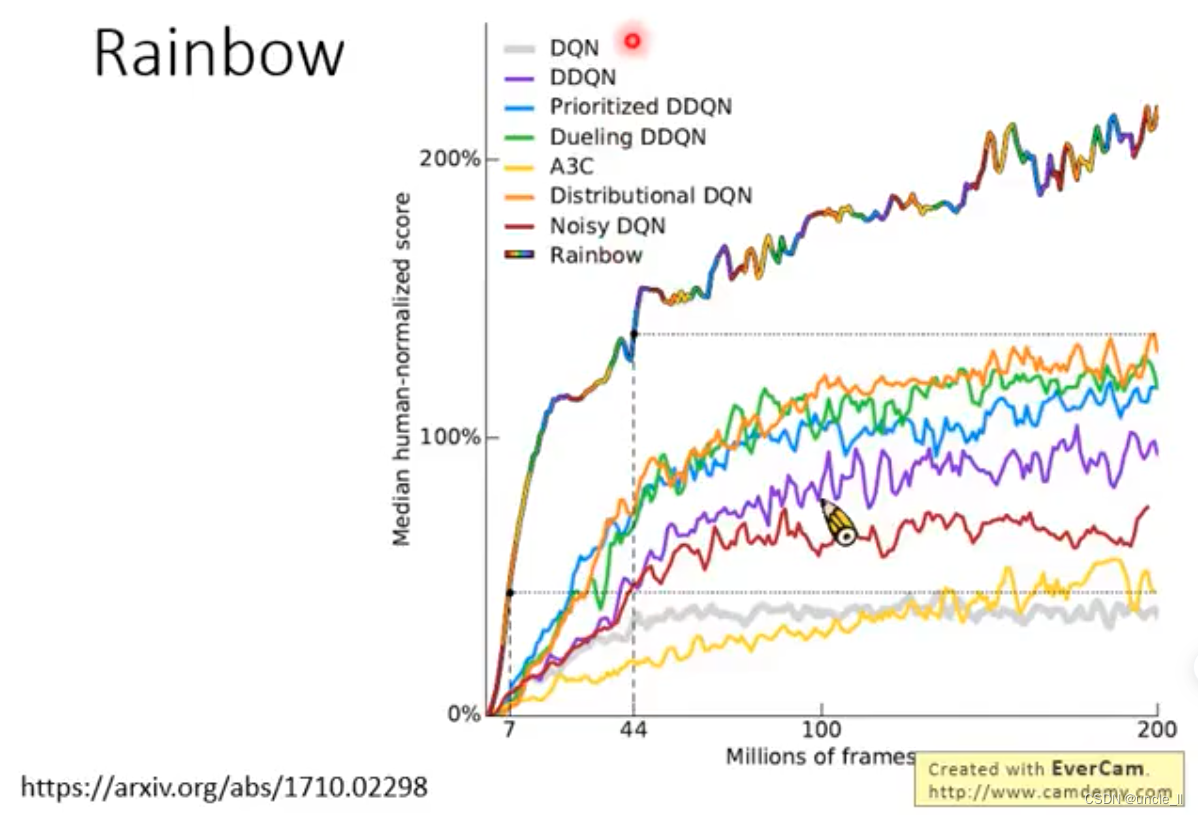
- 增加一些方法的结果
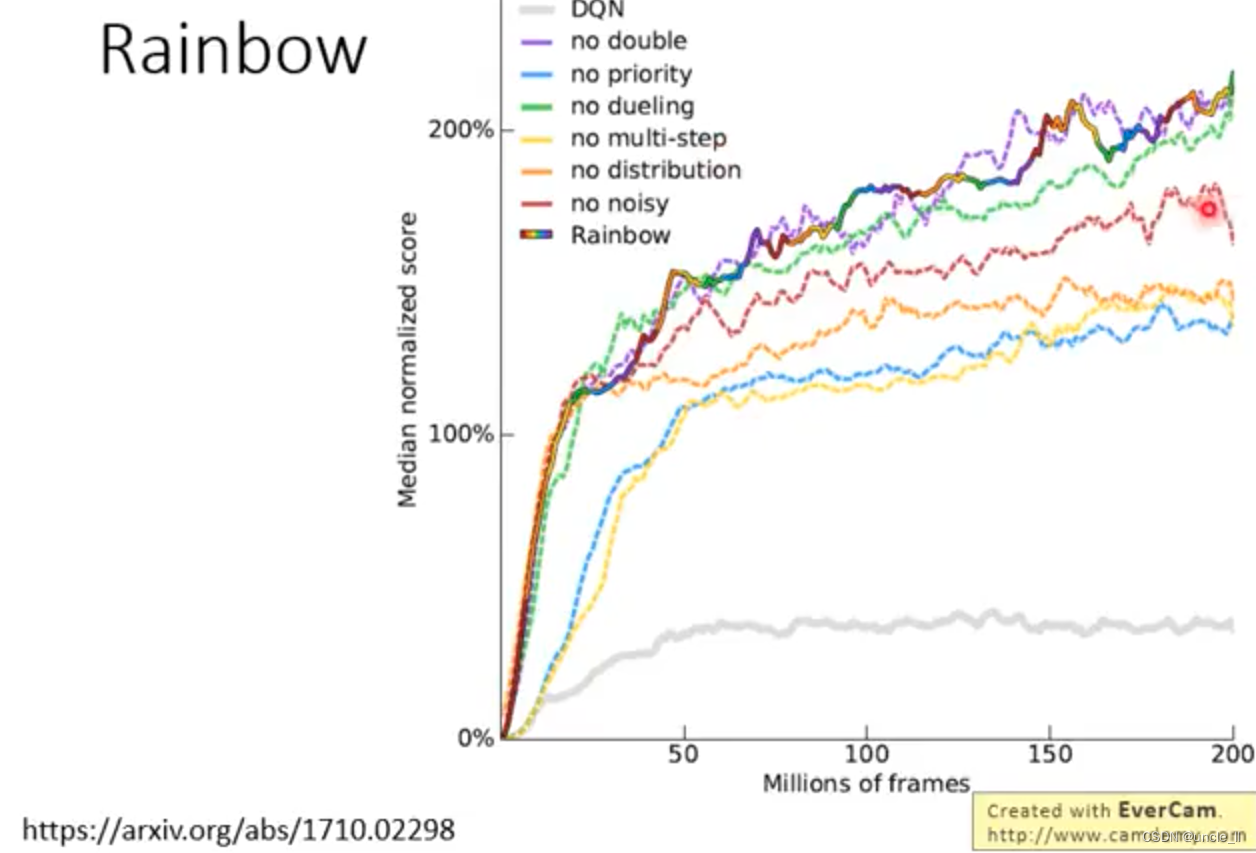
- 从算法集合中减少其中某一个算法后的性能
Q-Learning for Continuous Actions


- 方法1:从连续动作中采样
- 方法2:基于目标函数使用梯度下降算法求解
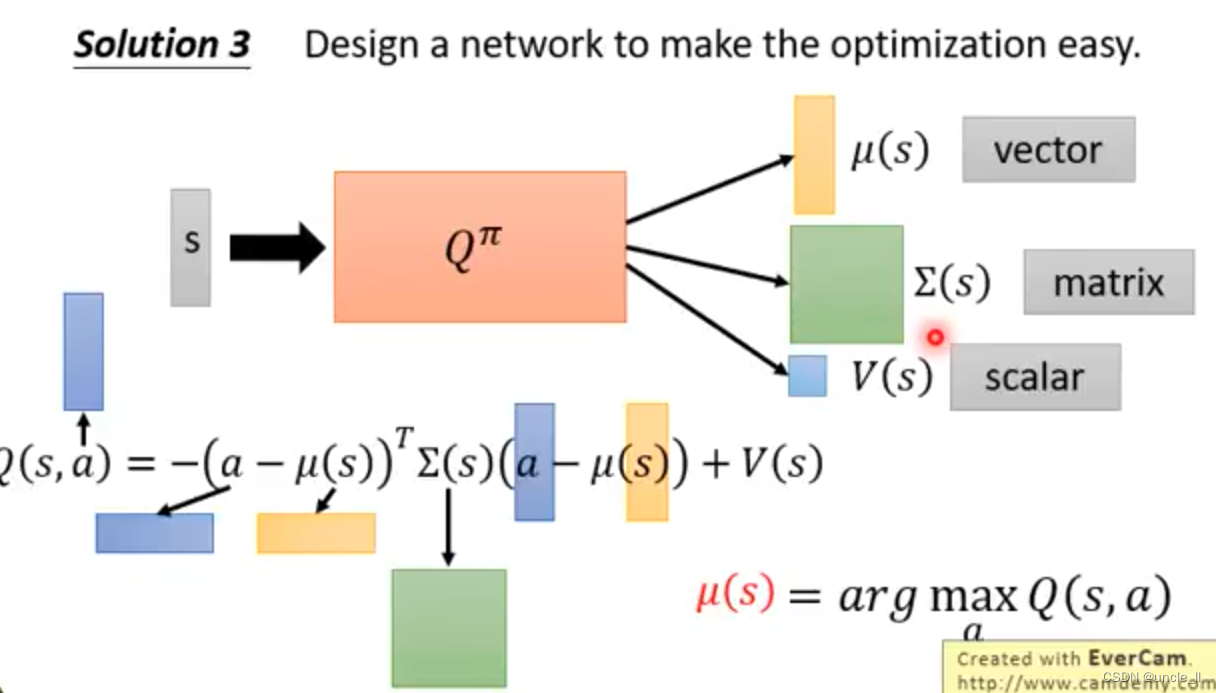
- 方法3:设计网络使得优化变得更加简单
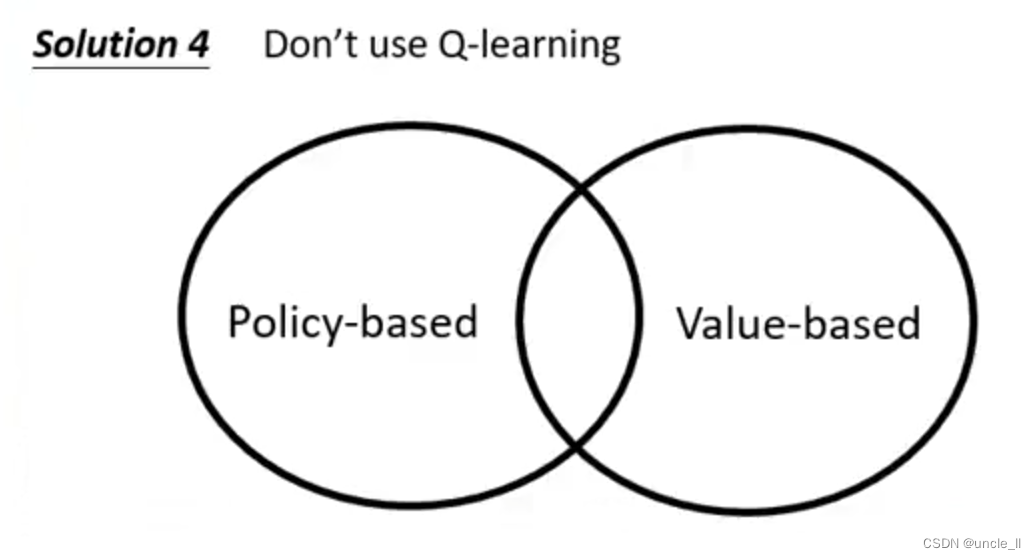
- 方法4: 不实用Q-learning















 8536
8536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











